1. LLM from huggingface
from langchain_community.chat_models import ChatHuggingFace
from langchain_community.llms import HuggingFaceHub
from huggingface_hub import login
from transformers import AutoTokenizer
import os
# 4B 크기의 한국어 모델로 변경
llm_model_name = "google/gemma-2-2b-it"
# LLM(대형 언어 모델)을 생성하는 함수
def getLlmHuggingface():
# HuggingFace Hub에 로그인
huggingface_token = os.getenv("HUGGINGFACE_API_KEY")
if not huggingface_token:
raise ValueError("HUGGINGFACE_API_KEY not found in environment variables")
login(token=huggingface_token)
# 토크나이저 로드 및 chat template 설정
tokenizer = AutoTokenizer.from_pretrained(llm_model_name)
# tokenizer.chat_template = "{% for message in messages %}{% if message['role'] == 'user' %}{{ '### Human: ' + message['content'] + '\n' }}{% elif message['role'] == 'assistant' %}{{ '### Assistant: ' + message['content'] + '\n' }}{% endif %}{% endfor %}"
# HuggingFaceHub LLM 초기화
llm = HuggingFaceHub(
repo_id=llm_model_name,
huggingfacehub_api_token=huggingface_token,
model_kwargs={
"temperature": 0.7,
"max_length": 512,
"do_sample": True
}
)
# ChatHuggingFace 모델 초기화
chat_llm = ChatHuggingFace(
llm=llm,
tokenizer=tokenizer,
huggingfacehub_api_token=huggingface_token
)
return chat_llm # 생성된 LLM 반환
2. embedding from huggingface
from langchain_huggingface import HuggingFaceEmbeddings
from huggingface_hub import login
import os
import torch
from transformers import AutoModel
# 허깅페이스 임베딩 모델 설정
embedding_model_name = "sentence-transformers/paraphrase-xlm-r-multilingual-v1"
# 허깅페이스 토큰 설정
huggingface_token = os.getenv("HUGGINGFACE_API_KEY")
# 허깅페이스 임베딩 모델 초기화
embeddings = HuggingFaceEmbeddings(
model_name=embedding_model_name,
model_kwargs={"device": "cpu"},
encode_kwargs={"normalize_embeddings": True}
)
# 허깅페이스 임베딩 모델을 반환하는 함수
def getEmbeddingHuggingface():
return embeddings
3. Insert vector data to postgresql
from langchain_text_splitters import RecursiveCharacterTextSplitter
from modules.llm.embedding_huggingface import getEmbeddingHuggingface
from langchain_community.document_loaders import PyPDFLoader
from langchain_community.vectorstores.pgvector import PGVector
# PDF 파일 로드
loader = PyPDFLoader("./prince.pdf")
pages = loader.load()
# 문서 분할
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=450, # 한국어 문자 기준 (약 300-500자 권장)
chunk_overlap=100, # 오버랩 크기
length_function=len
)
split_docs = text_splitter.split_documents(pages)
# PGVector에 문서 저장
try:
PGVector.from_documents(
documents=split_docs,
embedding=getEmbeddingHuggingface(),
connection_string="postgresql://postgres:1234@localhost:5432/postgres",
collection_name="document"
)
print("Documents processed successfully")
except Exception as e:
print(f"Error processing documents: {e}")
4. Query to llm
from modules.data.postgre import getPostgreRetriever
from modules.llm.llm_huggingface_hub import getLlmHuggingface
from modules.llm.embedding_huggingface import getEmbeddingHuggingface
from langchain.chains import RetrievalQA
from langchain import hub
from modules.environment.loadenv import setLoadDotEnv
setLoadDotEnv()
retriever = getPostgreRetriever();
llm = getLlmHuggingface();
# 프롬프트를 제공한다.
prompt = hub.pull("rlm/rag-prompt")
# 체인 구성
chain = RetrievalQA.from_chain_type(
llm=llm,
retriever=retriever,
chain_type_kwargs={"prompt": prompt}
)
# 체인 실행 및 답변만 추출
result = chain({"query": "뱀이 말한 것은?"})
print(result["result"])5. 결과
모델의 수준 치고는 진짜 만족할만한 결과가 처음으로 나왔다.
<start_of_turn>model
뱀은 어린 왕자에게 말하기 위해 뱀의 말은 '누구든지 내가 건드리면 그가 나왔던 땅으로 되돌아가 지. 하지만 너는 순진하고 다른 별에서 왔으니까...'라고 말했다. 뱀은 어린 왕자에게 뱀의 말은 '네 곁을 떠나지 않을 테야'라고 말했고, 또 '사람들이 어디에 있니? 사막은 좀 외로운데...'라고 말했다. 뱀은 어린 왕자와는 다른 별에서 온 것으로, 뱀은 어린 왕자에게 '나는 너의 별이 너무 그리울 때면 언제고 내가 너를 도와줄 수 있어.'라고 말했다. 
- 또다른 질답 결과.
Q : 아이들은 무엇에 시간을 바치는가?
A : 아이들은 헝겊 인형에 시간을 바치는데, 이는 그들이 인형을 소중하게 여기는 이유를 드러냅니다. 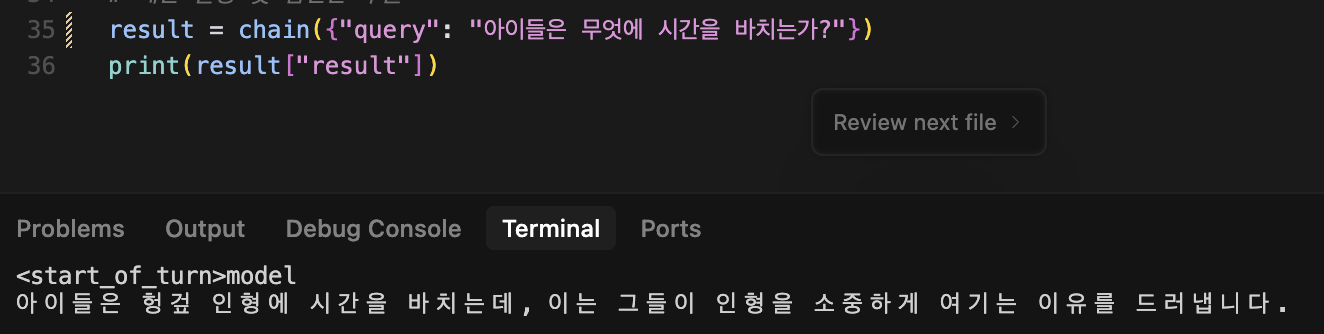
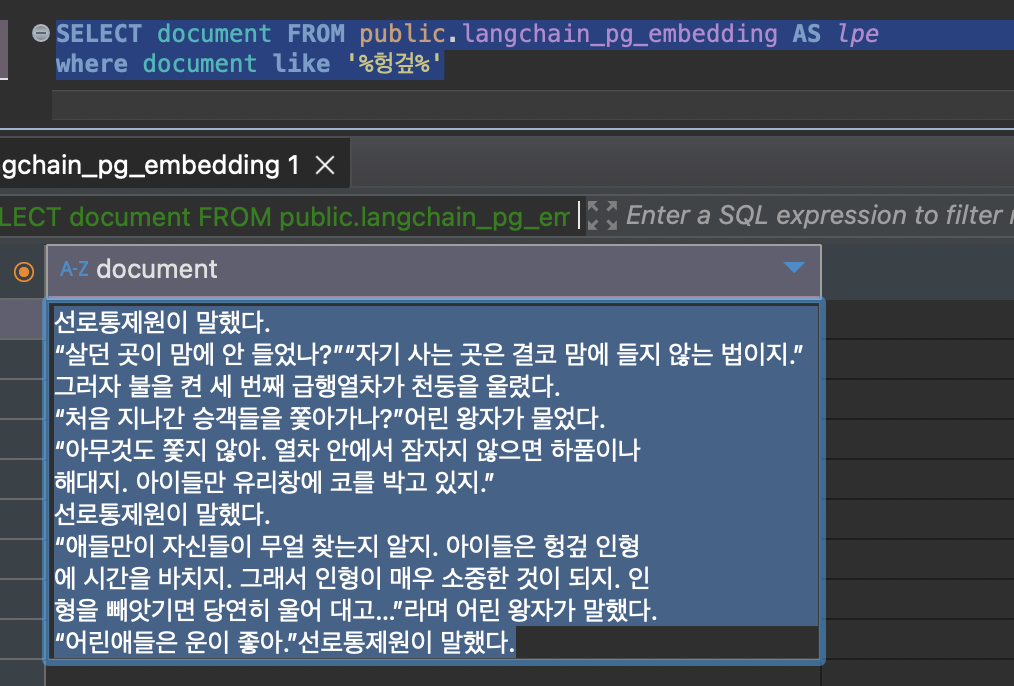
- llm 이 찾아야만 했던 벡터 데이터의 문자열

인공지능이라는 옷을 입었습니다. 뭔가 멋지면서도 잘 맞습니다.