likeLion
1.멋사 ai 스쿨 TIL - (1)

터미널에서 파일명을 입력 시, 코드를 실행한다. 데이터를 먼저 입력 후, 그 다음에 코드를 입력한다. for 문 입력 후 pring()*n 하면 n만큼 반복 들여쓰기를 해서 함수의 열을 맞춰주면, 함수가 같은 횟수로 실행된다 예시: >for x in range
2.멋사 ai스쿨 TIL - (2)

안타깝게도 .. 이제야 코드를 작성하는 옵션을 깨달았다 어젠 하루종일 인용구만 쓰느라 들여쓰기 다 온통 망쳤는데 1일차 TIL 가서 다시 수정해야지 .. (경택님 마크다운 링크 보내주셔서 감사해요..!) 여담이지만, 퀴즈가 4개 있었는데 한번에 쓰라는 줄 알고
3.멋사 ai스쿨 TIL - (3)
\-- 사담영역 --으앗 .. 다음 실시간 검색어 8월부터 사라졌는데 (15년만)커리큘럼이 수정되지 않는 대참사 ㅎㅎbeautiful soup는 '파이썬으로 웹크롤러 만들기' (라이언 미첼) 책에서 접해본 적 있었는데여기서 만나니 참 반갑다!문과 감성으로는 .. 아름다
4.멋사 ai스쿨 TIL - (4)
1\. 엑셀로 분석할 수 있는 행의 갯수 2\. 추상화가 잘 되었다는 의미는? 3\. 파파고 서비스팀의 인원은? 4\. ELT, ETL의 차이점은? 5\. Data Lake를 구축하는 이유는? 6\. 인기있는 게임 로그가 하루에 쌓이는 양 - 200만가량
5.멋사 ai 스쿨 TIL - (5)

if 문무조건 들여쓰기한 내용이 다음에 나와야 함(ex. print 함수 앞에 공백)제어문 끝에는 콜론(:) 필수PEP8: 파이썬 컨벤션 (익스텐션으로 자동 교정 가능)==는 비교연산, =는 할당연산을 의미indentation과 colon 까먹지 말 것pylint 등의
6.멋사 ai스쿨 TIL - (6)
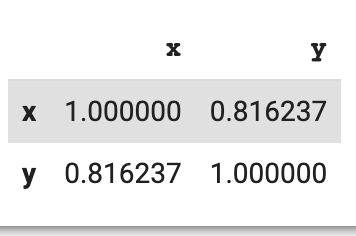
복습as: alias브로드캐스팅: 테이블 전체에 설정프로파일링: 성능검증
7.멋사 ai스쿨 TIL (insight_day) - (7)
(1) 숫자형 % - 나머지 반환// - 몫 반환 (2) 문자열 ''' - 출력 시 줄 바꿈문자열 포매팅포매팅 연산자 %d와 %를 같이 쓸 때는 %%를 쓴다.아래처럼 포맷 함수를 사용할 수도 있다.join 함수는 무엇으로 연결할 지 생갹해야 한다.(4) 튜플하나의 요
8.멋사 ai 스쿨 TIL - (8)
% 어떤 단어가 와도 상관 없다는 의미 어떤 단어가 와도 상관 없다는 의미 (LIKE와 함께 활용)%나 자체를 찾고 싶을 경우, escape 문자 '\\'를 앞에 기입. (1) 도시목록 출력 인구수가 100,000명 이상이고 국가코드가 USA인 도시의 데이터를 불러오
9.멋사 ai 스쿨 TIL - (9)
unique value in pandas출처: https://snepbnt.tistory.com/570그래프 보는 법pandas Profiling Report만 보아도 알 수 있듯이, 다양한
10.멋사 ai 스쿨 TIL - (10) 웹스크래핑
\-- 어제 배운 내용 --범주형 변수에 대한 기술통계를 보기결측치의 합 구하기결측치의 평균 구하기 (1) frequency, top 값 등을 확인 (2) 범주형 데이터는 object 외에도 boolean 등의 형식으로도 구성. (3) nunique 값 구하기 (4
11.멋사 ai 스쿨 TIL - (12) 카페 위치 데이터

selenium 버전 관련패키지가 업그레이드되면서 지원되지 않는 함수 존재 (업그레이드 하면서 드문 케이스 - 보통 지원함)위치 데이터 정리하면서 사용 불가할 경우 새로운 방법을 찾아봐야 함.데이터 서치 시나리오(1) 네이버 맵을 활용한다(2) 오프라인 매장 갯수 to
12.멋사 ai 스쿨 TIL - (14) 서울정보소통광장 웹스크래핑
1\. ANACONDA를 사용하는 이유python이 둘러싼 라이브러리들은 내부에 C나 java가 들어가 있는 경우도 있음해당 언어들을 실행할 환경 설정이 되어 있지 않은 경우 에러가 발생함버전 호환성 맞춰주기도 쉽지 않음기타 언어에 의존성 높아서 활용 불가한 패키지 배
13.멋사 ai스쿨 TIL - (15) plotly
join은 column - row의 데이터가 겹치지 않을 경우 날려줄 수 있음 중복값 있을 시, warning message 설정 가능
14.멋사 ai스쿨 TIL - (16) plotly-2
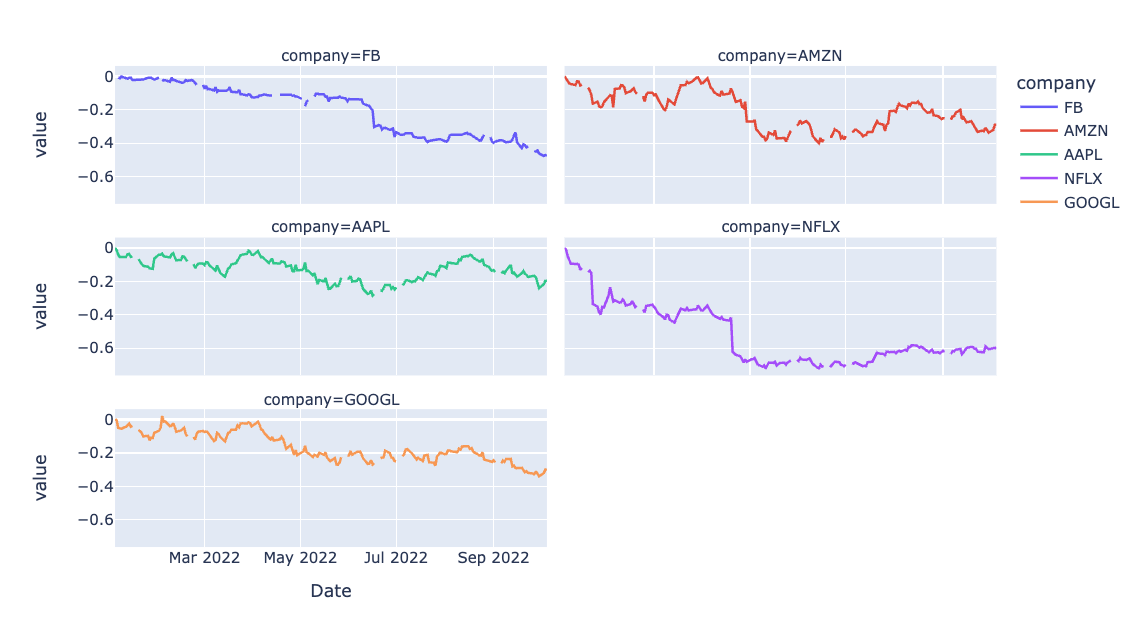
1\. px.line으로 선 그래프 그리기테이블의 컬럼명을 company로 지정해주고, 아래와 같은 다섯개의 서프 플롯 그래프를 그려낼 수 있다.컬럼명은 아래와 같이 입력한다.2\. 일별 수익률 구하기3\. px.area4\. 막대 그래프값이 과도하게 겹칠 경우 fac
15.멋사 ai 스쿨 - (17)
: Series는 괄호 여부에 따라 달라진다.pandas는 벡터 연산을 하게 된다.Tidy data를 만들려면?melt: 열(column)에 있었던 데이터를 행(row)으로 녹여낸다.연도, 월 등 컬럼의 세분화 또한 포함됨Tidy Data로 만들어주면 데이터 전처리,
16.멋사 ai스쿨 TIL - (18)
데이터 시나리오 주제: 인기 한국 드라마 top 100이 주로 방영된 요일은 무슨 요일일까? / 폭력성 및 나이 제한은 상위 50%와 하위 50% 중 어디에 더 많이 분포해 있을까?https://www.kaggle.com/datasets/chanoncharuc
17.멋사 ai 스쿨 TIL - (19)
relplot은 관계, displot은 분포, catplot은 범주.
18.멋사 ai 스쿨 TIL - (20) Datarian Final
DATE_ADD, DATE_SUB: 단순 사칙연산으로는 날짜 데이터를 조작할 수 없으므로, 위 함수를 사용해주어야 함.sql 부등호: <>UNION 이전 쿼리: ORDER BY 특정컬럼 불가능GROUP BY 이후 갯수 출력: HAVING COUNT (\*)CASE
19.멋사 ai스쿨 TIL - (21)
용량 절감 bool값이 int8보다 용량을 더 많이 먹는다 downcast를 활용해서 용량을 줄일 수 있다. 자료형 이름만 얻어오는 예시이다. 'unit16' 따위의 값을 리턴한다. csv는 열 단위, parquet은 행 단위의 압축을 지원하여 후자가 더 저장공간을 절
20.멋사 ai 스쿨 TIL - (22)
gitignore 옵션파일 생성시, 업로드 해서는 안되는 파일들에 대한 필터링 옵션을 걸 수 있다.LICENSErepository 소유자가 소스코드 권한에 대해 입장 표명. 처음부터 설정해줄 수도 있고, 이후에 파일 추가하면 라이센스 템플릿 선택도 가능함 (ex. MI
21.멋사 ai 스쿨 TIL - (23) ML Tools
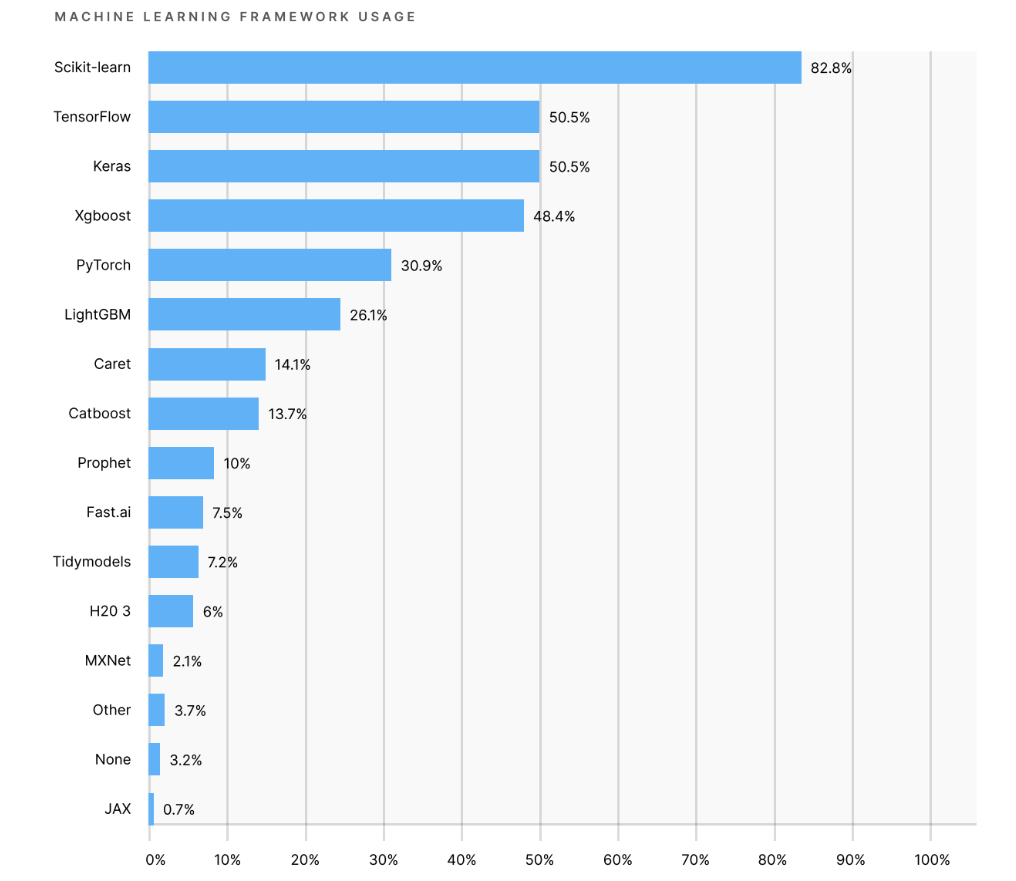
캐글은 해마다 설문조사를 진행하고 있다.사람들이 어떤 도구를 주로 사용하고 있는지 관심있게 살펴보기 위함이다. 주로 사이킷런을 가장 많이 사용한다.파이썬을 쓴다면 주로 사이킷런을 사용한다.Xgboost는 트리계열의 부스팅 알고리즘을 라이브러리로 만들어둔 것이다. 트리를
22.멋사 ai스쿨 TIL - (24) 분류와 회귀
(1) 분류개체가 속한 범주 식별이진분류, 다중분류로 구성스팸메일 탐지기, 웹 사이트 언어 분류 등(2) 회귀개체와 연결된 연속값 속성을 예측숫자의 많고 적음에 대해 처리할 때 사용광고 클릭률, 원유가격, 기간별 매출액, 재고량, 약물 반응, 주가 예측, 생산량 예측
23.멋사 ai스쿨 TIL - (25)

(1) desc:(2) quantile: 25%와 75% 값을 가져와서 활용저성능 분류기들을 결함시키는 방법이다. 과반수 투표를 진행한다. 배깅(분산 감소시키기), 부스팅(편향 사용), 스태킹(stacked generation) 등의 접근법이 있다.(1) 정의: Boo
24.멋사 ai 스쿨 TIL - (26) Tableau

데이터 해석기자동 전처리 도구. 결측치 등 제거Live Connection vs Extract(1) Live Connection: 데이터를 원본 DB에 남겨둔다고성능 DB 기능 활용시각화 자료 업데이트(2) Extract: DB가 무거울 때 일부만 추출집계(1) Vis
25.멋사 ai 스쿨 TIL - (27)
요약중
26.멋사 ai 스쿨 TIL - (28)
(1) 정의: 어떤 수를 나타내기 위해 고정된 밑을 몇 번 곱해야 하는 지 표현. 지수함수의 역함수.이진로그: 밑이 2인 로그자연로그: 특정 상수를 밑으로 하는 로그상용로그(10진로그): 10을 밑으로 하는 로그(2) 공통점: x가 1일 때, y는 0이다.(1) 전제불
27.멋사 ai 스쿨 TIL - (29)

시각화 하여 정규분포 여부를 확인 (피쳐 전처리 고민)평균, 중앙값 등으로 대체 데이터 왜곡에 주의할 것 (ex. 연예인 집값 != 일반인 집값)현실 데이터에서의 큰 문제.범주형 데이터에서 빈도가 적게 등장하는 값단점: \- 원핫인코딩 시, 범주가 적은 값을 피처로
28.멋사 ai 스쿨 TIL - (30)
결측치 대체(Imputation)수치형 변수를 대체할 때는 원래의 값이 너무 왜곡되지 않는지도 주의가 필요합니다.중앙값(중간값), 평균값 등의 대표값으로 대체할 수도 있지만, 당뇨병 실습에서 했던 회귀로 예측해서 채우는 방법도 있습니다.당뇨병 실습에서 했던 인슐린을 채
29.멋사 ai 스쿨 TIL (31) - a.m 자기주도학습
강사님의 건강상 이슈로 인해 인사이트 데이와 동일하게 자기주도학습을 실시했다.학습 목표는 K-MOOC 강좌 중 Classification, Clustering, Neural Network의 요약 및 정리이다.두 관측치의 거리가 가까우면 target도 비슷하다.K개의 주
30.멋사 ai 스쿨 TIL (32) - p.m 자기주도학습
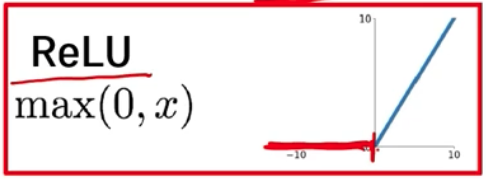
max(0, x) 0을 기준으로, 입력값이 음수면 0을 출력하고 양수면 들어온 값을 그대로 출력한다.깊은 수준의 모델을 학습시키기에 용이역치를 넘을 때 전달하고 넘지 않을 때는 전달하지 않는 뉴런의 특성을 잘 설명행렬에 weight matrix의 값을 조정하여 분포 기
31.멋사 ai 스쿨 TIL (33) - a.m 자기주도학습
자료에 중복 정보가 많을 경우, 자료가 갖는 차원보다 더 작은 수의 차원에서도 자료에내재한 정보 설명 가능처음 몇 개의 차원이 정보를 최대한 많이 설명할 수 있도록 자료를 새로운 방향에서 보게 함각각의 성분 간에 상관관계가 없음 -> 이후 회귀 분석 등에서 종속 관계
32.멋사 ai 스쿨 TIL - (33) 자기주도학습
데이터 셋을 서로 중복되지 않는 subset으로 나누어 평가를 실시하는 것을 뜻합니다. 고정된 training dataset과 test dataset을 통한 평가 및 튜닝으로 인해 test dataset에 과적합 되는 것을 방지하기 위한 방법입니다. holdout, k
33.멋사 ai 스쿨 TIL - (34) codingtest_week1
페이지 교체 알고리즘FIFO: 페이지가 주 기억장치에 적재된 시간을 기준으로 교체될 페이지를 선정하는 방법LFU: 가장 적은 횟수를 참조하는 페이지를 교체LRU: 가장 오랫동안 참조되지 않은 페이지를 교체하는 기법리스트로의 변환메모리 효율이 떨어지게 된다.순회 가능한
34.멋사 ai 스쿨 TIL - (34) 평가지표와 SMOTE
다수 범주의 데이터를 소수 범주의 데이터 수에 맞게 샘플링하는 것이다. (다수의 데이터를 줄이는 방법)under sampling을 할 경우, 일반적으로 recall값이 낮아지기 때문에 over sampling을 주로 사용한다.예시) 1의 값을 가지는 데이터가 492인
35.멋사 ai 스쿨 TIL _ (35) tensorflow
tensorflow 모델의 구성tensorflow와 pytorch의 차이점라이브러리 도구의 api 차이 (seaborn vs plotnine처럼)모델 컴파일훈련 중 모델이 얼마나 정확한지 측정합니다. 모델을 올바른 방향으로 "조정"하려면 이 함수를 최소화해야 합니다.l
36.멋사 ai 스쿨 TIL - (36) tensorflow 실습_0901
callbackverbose=0을 모델 옵션에 넣어주면 로그 출력을 하지 않는다.출력 함수가 sigmoid일 때, 특정 임계값을 정하면 크고 작다는 기준을 갖게 될 수 있으므로 True, False 값으로 판단한다.임계값은 보통 0.5를 사용하지만, 다른 값을 사용하기
37.멋사 ai 스쿨 TIL -(36) codingtest_week2
이호준 강사님이 추가해주신 자료들https://www.bigocheatsheet.com/https://wayhome25.github.io/python/2017/06/14/time-complexity/
38.멋사 ai 스쿨 TIL - (37)
합성곱 층 만들기DNN을 사용할 때 입력과 CNN 입력 차이: DNN에 비해 CNN에서는 컬러채널이 추가된다. input shape에서 (이미지 높이, 이미지 너비, 컬러채널) 순으로 입력값이 추가된다.모니터, 인쇄매체 등 어디에 색상을 사용하느냐에 따라 표현 방식이
39.[CNN] 이미지 증강 (image augmentation)
이미지 로드하는 방법matploblib.pyplot imread()PIL(pillow): PIL로 flip, rotation, zoom이 모두 가능하다. (이미지 편집기를 만들 수도 있다)OpenCV로 불러오는 방법 (Computer Vision)
40.[CNN] 전이학습 (transfer learning)
transfer learningnumpy array
41.멋사 ai 스쿨 TIL - (38) 자연어 처리
np.array로 되어있는 이미지 자료를 다시 np.array로 바꾸어주는 이유 리스트 안에는 np.array로 작성되어 있지만, 여러 장의 이미지를 하나로 만들 때 파이썬 리스트에 작성해주었다. 이미지 여러 장을 하나의 변수에 넣어주었을 때 해당 변수의 데이터타입은
42.멋사 ai 스쿨 TIL (40) - online retail
R => 값이 작을 수록 높은 점수를 줍니다. 왜냐하면 최근에 왔는지를 보기 때문에F => 값이 높을 수록 높은 점수를 줍니다. 왜냐하면 자주 왔는지를 보기 때문에M => 값이 높을 수록 높은 점수를 줍니다. 왜냐하면 얼마나 많은 금액을 구매했는지 보기 때문에
43.[Final Project] TIL (2) : Seq 2 Seq Model
RNN 모델에서 Many to Many (다 대 다 모델)에 해당합니다.입력도 출력도 모두 Sequence 형태로 이루어져 있음을 의미합니다.자연어 처리에서 입력은 word 단위의 문장이고, 출력도 마찬가지이다.두 가지로 이루어져 있으며, 두 모델 모두 RNN으로 이루
44.[Final Project] TIL (1) : Subword Tokenization
1. 등장 배경 문법적으로 더 이상 나눌 수 없는 단위인 토큰으로 분리하는 작업을 의미합니다. POS tagging 과거의 토큰화 방법입니다. 단점: 처음 등장하는 단어를 처리할 경우, 모델에 Unknown Token이 들어가게 되어 모델의 성능이 낮아지는 것을 유발합
45.[Final Project] TIL (3) : Attention
Decoder부터 이해하자 인코더는 기계가 주어진 문장을 모두 읽고,이해하는 과정입니다. 문장을 생성하는 task에서 주로 사용됩니다. 입력 토큰을 'Sentence of Sequence', 즉 '첫 번째로 입력해줄 토큰' Decoder는 말 그대로 순서대로 입력되는