1. 캐글, AI
- 캐글은 해마다 설문조사를 진행하고 있다.
사람들이 어떤 도구를 주로 사용하고 있는지 관심있게 살펴보기 위함이다. 주로 사이킷런을 가장 많이 사용한다.
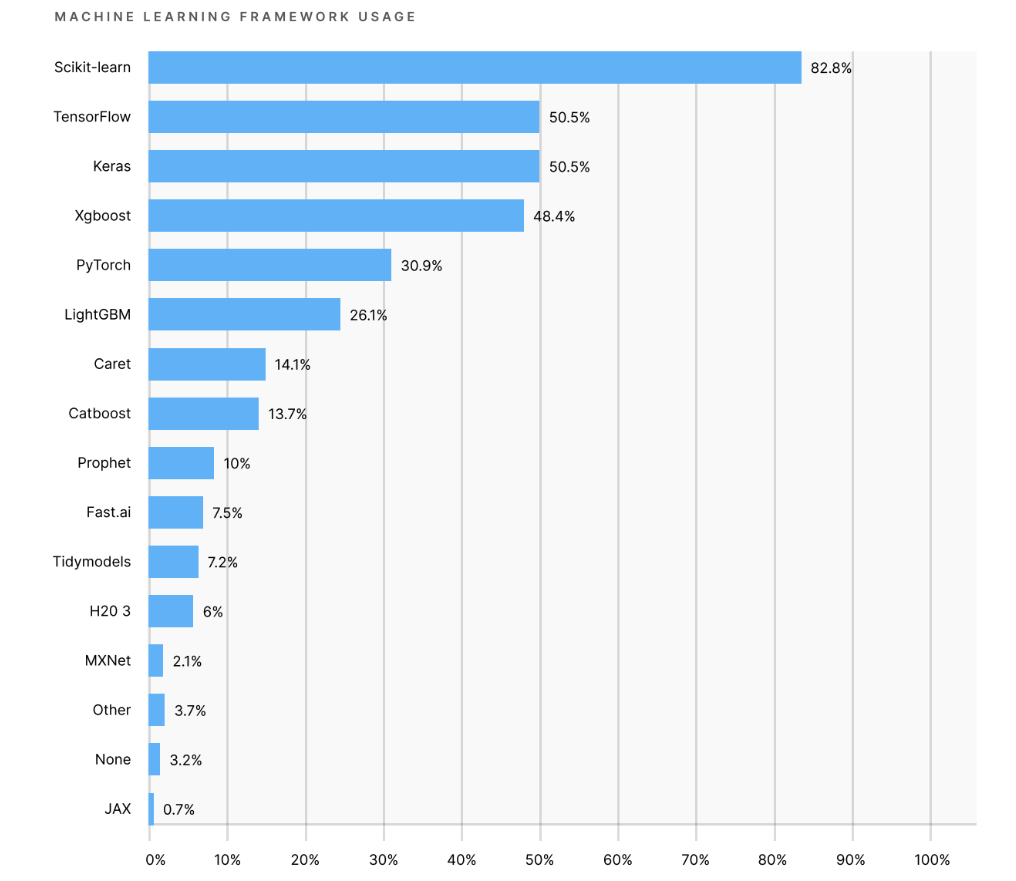
- 파이썬을 쓴다면 주로 사이킷런을 사용한다.
- Xgboost는 트리계열의 부스팅 알고리즘을 라이브러리로 만들어둔 것이다. 트리를 따라가며 최적화 선택을 하여 낭비를 최소화.
- TensorFlow, Keras, Pytorch 모두 딥러닝 라이브러리이다.
- Caret은 OpenMl에 가깝다. 사용하기 쉽게 추상화해두었다.
- Prophet은 시계열 데이터 예측에 주로 사용된다.
- 파이썬의 특징은 문서화가 잘 되어있다는 점이다. 새로운 라이브러리를 접한다고 해도, 두려워할 필요없이 문서를 먼저 확인해보자.
- 도구를 너무 기능적으로 생각해서 도구를 파편화해서 외우는 것에 집중하는 실수를 저질러서는 안 된다.
2. 에디터들
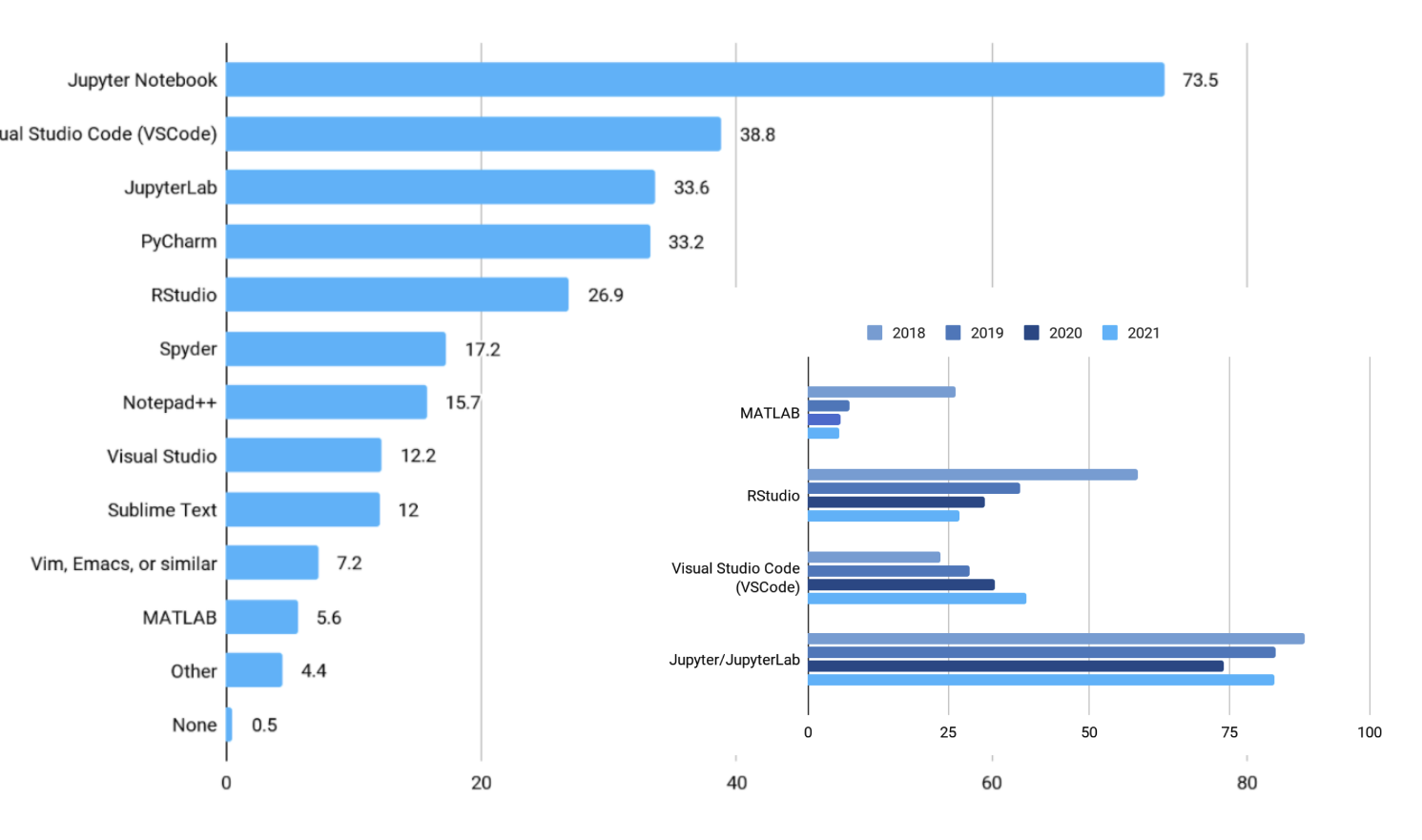
- 주피터랩은 .py 파일 편집 기능 뿐만 아니라, 주피터노트북처럼 터미널 활용도 가능하다.
- 주피터랩은 주피터노트북의 업그레이드 버전이다. 새로운 창을 띄우면 탭으로 뜬다.
- Pycharm은 Vscode보다도 하위에 위치한다.
3. 알고리즘
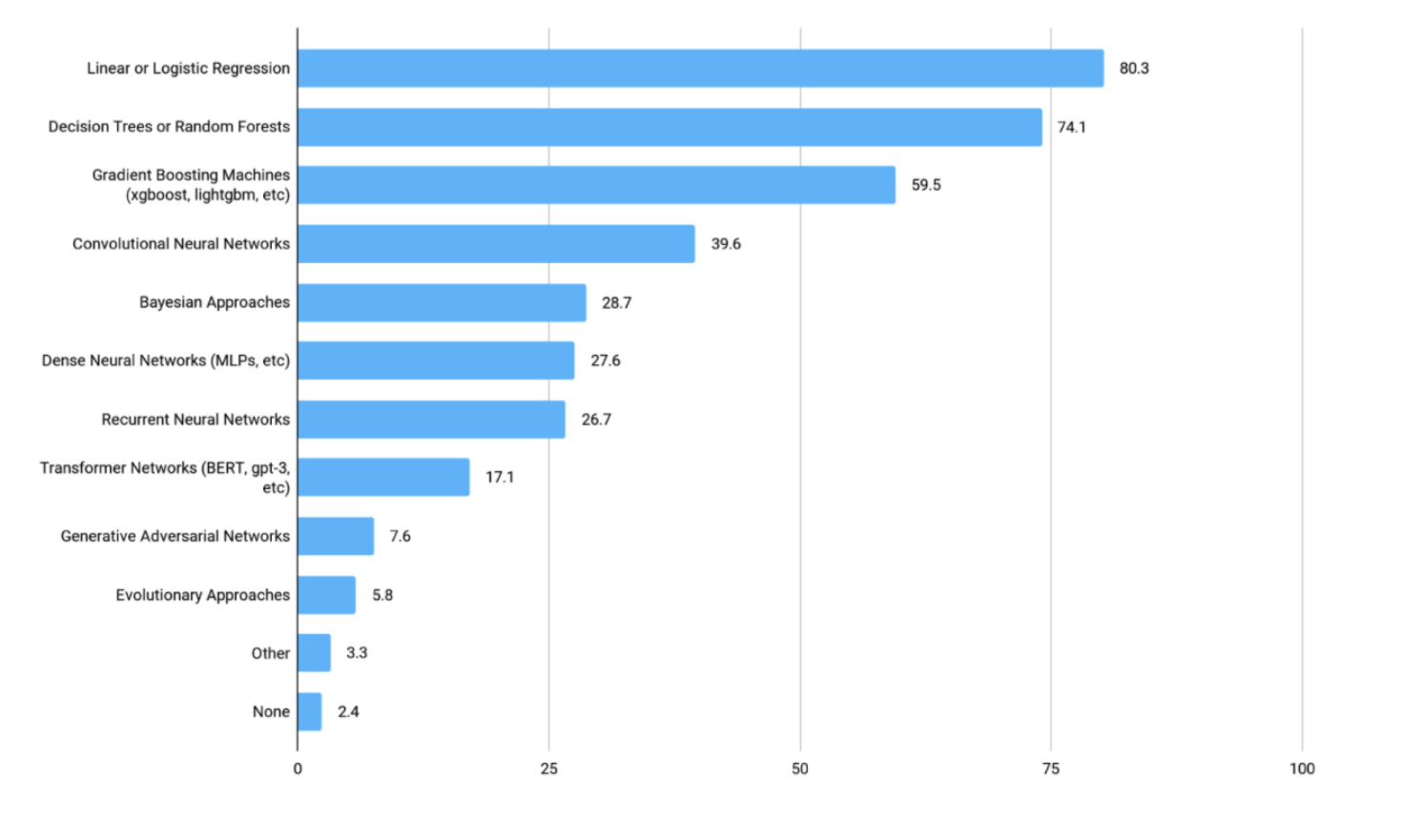
-
선형 회귀 모델을 가장 많이 사용한다는 것을 알 수 있다.
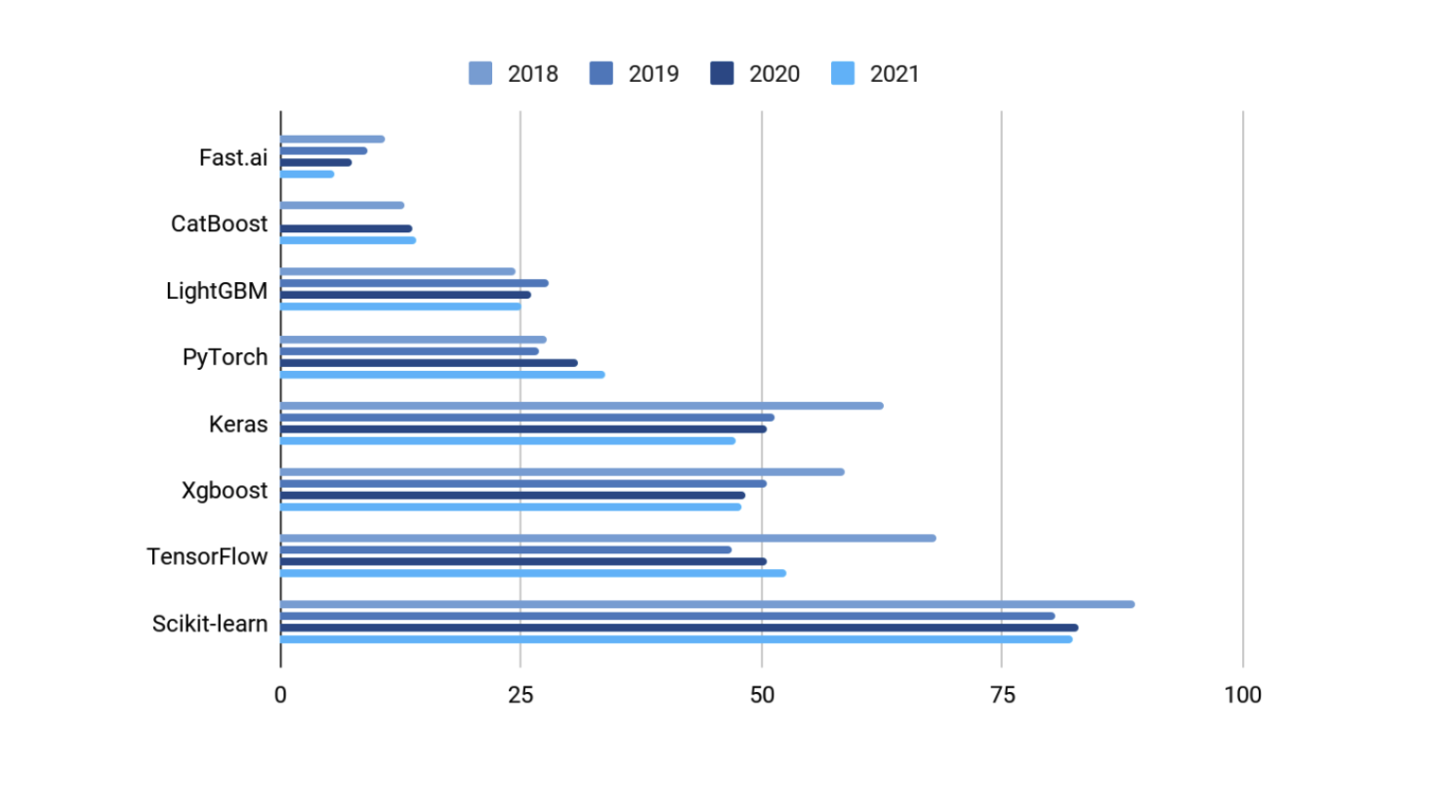
-
사이킷런이 가장 많이 사용되지만, Fast.ai는 Keras를 공식 툴로 채택했다.
-
XGboost는 트리를 따라 선택하여 손실을 ㅊ ㅚ소화한다.
-
Catboost
-
PyCaret는 파이썬을 한번 둘러싼 라이브러리이다. Auto Ml에 가까우며, 여러 라이브러리 활용으로 결과를 보여준다. 추상화가 잘 된 상태.
-
H2O는 수동 코드 작성 시간을 줄이고자 하며, 훈련 데이터셋을 클러스터로 확장한다.
-
SVC - support vector machine
4. Classification (분류)
-
라벨이 붙은 데이터를 학습시킨다. 지도학습에 해당.
5. Regression (회귀)
-
범주형 데이터의 분석
6. Clustering (군집화)
-
라벨이 붙지 않은 데이터를 학습시킨다. 비지도 학습에 해당. 라벨 자체를 찾는 학습도 가능 (파이썬 라이브러리를 활용한 머신러닝 참고)
7. Dimensionality (차원축소)
-
방대한 데이터. 속도 개선을 통해 효율을 높인다.
8. Model Selection (모델선택)
-
최적화 모델 선택. 테스트 데이터셋도 중요. 모델 성능 추정과정.
9. Pre-processing(전처리)
-
특징 추출, 정규화.
-
pandas에서는 정규화 활용 시 0에서 1 사이의 값으로 표현 가능 - 백분율까지 연결 가능.
-
문자열 자체를 인식시킬 수는 없음.
10. 지도학습 - Supervised ML
17개의 알고리즘. Unsupervised Ml에는 6개의 알고리즘 존재. 리니어 알고리즘 내에서만 해도 18개의 알고리즘 존재.
11. Tensorflow
Seaborn이 Matplotlib을 감싼 것 처럼, Tensorflow를 사용하기 쉽게 감싸놓은 것이 Keras.
12. XAI - 설명가능한 인공지능
(1) AI 블랙박스 문제를 해결하기 위한 연구.
(2) 모델을 어떻게 잘 설명하면 되는 지에 대한 부분.
(3) 예측 가능성에 대해 시각화
Ex. Yellow brick algorithm
(4) 순열 중요도
- 예측에 가장 큰 영향ㅇ르 미치는 feature을 파악하는 방법
- 모델 훈련 완료 후 계산
- 훈련 모델이 특정 feature을 사용하지 않았을 때 어느정도 손실이 발생하는 지 예측 가능.
13. ELI5
(1) Explain Like I'm 5 ! !
(2) 모델을 만든 후, 왜 모델이 이렇게 예측했는지 시각화하여 설명.
14. Scikit-Learn Cheatsheet
(1) 표본이 50개보다 많으면 범주 예측으로 넘어간다.
(2) Labeling은 정답의 유무를 의미한다.
(3) 정답이 있으면 분류나 회귀모델.
(4) 정답이 없으면 군집화나 차원축소.

