1. 분류와 회귀
(1) 분류
- 개체가 속한 범주 식별
- 이진분류, 다중분류로 구성
- 스팸메일 탐지기, 웹 사이트 언어 분류 등
(2) 회귀 - 개체와 연결된 연속값 속성을 예측
- 숫자의 많고 적음에 대해 처리할 때 사용
- 광고 클릭률, 원유가격, 기간별 매출액, 재고량, 약물 반응, 주가 예측, 생산량 예측 등
(3) 추천 시스템 - 함께 구매한 상품, 관심있는 상품에 기반하여 추천하므로 비지도 학습에 가까움.
(4) 정답의 유무 - 정답 = Label = Target
- 정답이 Nan, null 등 결측치이면 정답이 없는 것임.
2. 지도학습의 과정
(1) Model
- Training data
X_train
기출문제에 해당 - Training Labels
y_train
기출문제의 정답
(2) Prediction - Test Data
* X_test(Generalization)
(3) Evaluation - Test Label
**비지도학습 - 차원축소: 주성분 분석 (이후 과정에서 학습)
3. 변수명
(1) 대문자 X, 소문자 y
일반적으로 디자인 매트릭스는 X 응답 벡터는 y를 쓰는것이 관례. 원래 표기법대로라면 둘 다 대문자가 맞지만, X는 일반적으로 2차원의 매트릭스 형태고 y는 1차원의 벡터라 대소문자로 나눠 적게 된 것.
(2) 주요 파라미터
- criterion: 가지 분할의 품질을 측정하는 기능
- max_depth: 트리의 깊이를 결정하며, 모델 성능에 큰 영향을 끼침.
(3) 지도학습에서 X_train, y_train, X_test, y_test를 나누는 프로세스는 ML이나 DL이나 동일하다.
4. Tree Algorithm
- Pseudo_code
from sklearn.tree import plot_tree # sklearn에서 tree 알고리즘을 import한다.
plt.figure(figsize=(30,10)) # pyplot으로 사이즈를 지정해준다.
plot_tree(model, max_depth=3,# 트리에 사용할 데이터, 트리의 노드 갯수의 depth를 설정한다.
feature_names=feature_names, filled=True, fontsize=15) # 변수명, 색, 폰트크기를 지정한다.
plt.show위 코드의 결과로 다음과 같은 트리가 그려진다.
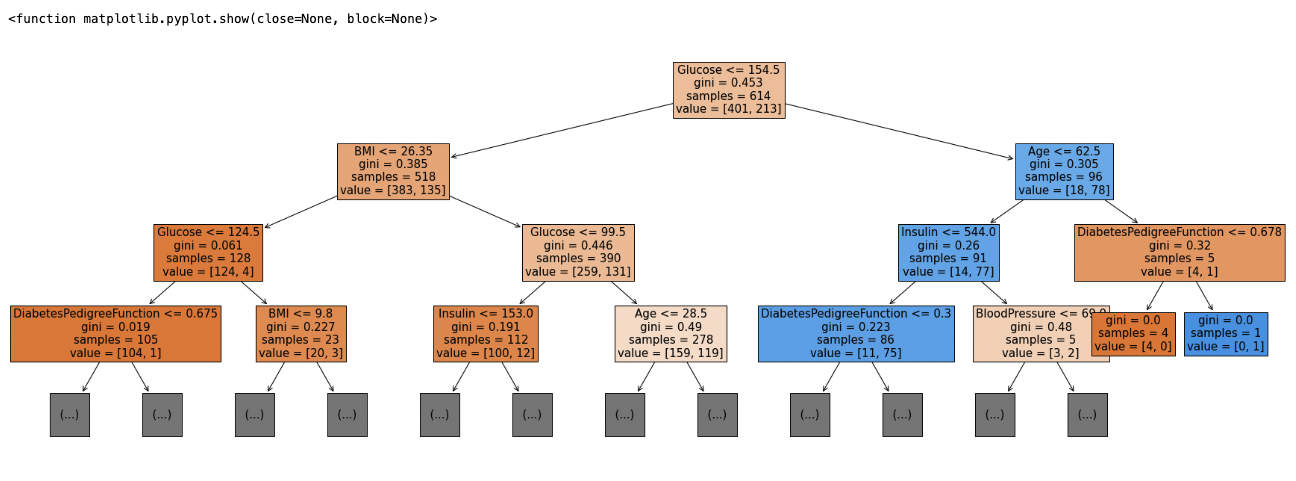
관찰
- 글루코스가 핵심 인자이다.
- 나이가 62.5세 이하인 점이 영향을 미칠 수 있다.
- BMI 지수가 26.35보다 낮은 점이 영향을 미칠 수 있다.
- gini는 지니 계수를 의미하며, criterion(트리 성능 측정)에 사용되는 도구 중 하나이다.
(2) 알고리즘의 시대적 경향
- SVC에서 Tree Decision 쪽으로 트렌드가 넘어왔음.
- CART (classification and regression tree)
- 나이브 베이즈는 회귀에는 쓸 수 없다.
참고
실습파일 0401.ipynb ~ 0402.ipynb 참고

유저가 왜 그랬을까