Multi-layered Structure
Logistic Regression to Neural Network
1. Sigmoid
2. Tanh
3. ReLU
- max(0, x) 0을 기준으로, 입력값이 음수면 0을 출력하고 양수면 들어온 값을 그대로 출력한다.
- 깊은 수준의 모델을 학습시키기에 용이
- 역치를 넘을 때 전달하고 넘지 않을 때는 전달하지 않는 뉴런의 특성을 잘 설명
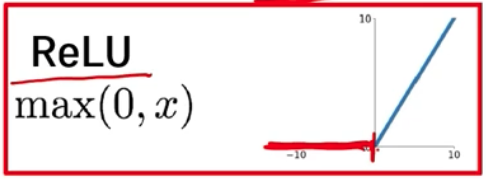
How Activation Function Works?
원리
- 행렬에 weight matrix의 값을 조정하여 분포 기준을 조정. (= parameter 조정)
- weight parameter는 2차원이나 hyperplain을 대변하는 값.
- 선형 변환을 통해 새로운 차원으로 projection하는 과정.
- 데이터 벡터를 내적해주면 기준이 되는 단위 벡터의 방향만이 유의미해지게 됨.
- 내적의 의미: 기본 데이터를 조정한 데이터 공간에 projection하여 나온 정보를 취한다.
예시
-
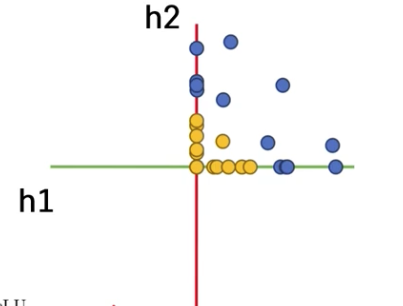
ReLU 함수를 적용했을 때의 결과: x축으로 사영이 일어나게 된다.
-
선형 분류기로 분류하기 용이한 형태가 되었다는 것을 확인할 수 있다.

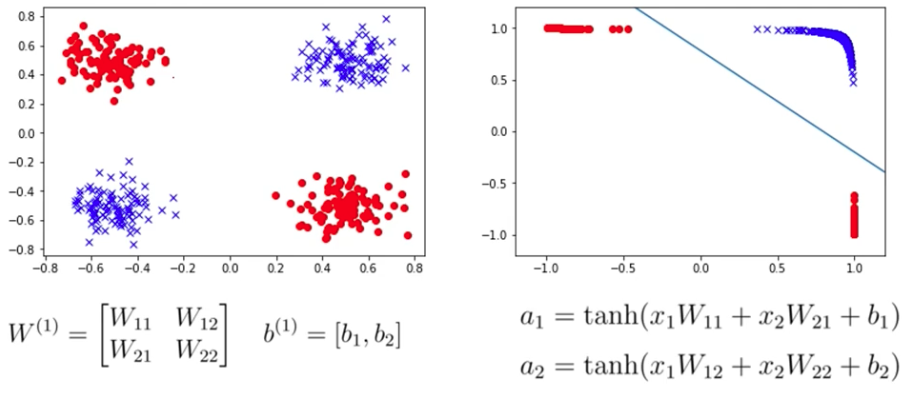
-
동일한 비선형적 데이터라 해도, 어떤 함수를 거치느냐에 따라 선형 변환 가능 여부가 결정된다.
Softmax
배경
- Multi-output - 2 hidden layer Neural Network 상황 가정 (클래스는 여러개)
- 특정 클래스에 속할 확률 측정 (classification)
원리
- logit = Nonlinear Activation 적용 전 Neural Network의 output
- 각각의 logit에 exponential을 취해서 정규화를 시킨다.
- 이 때 나온 output이 probability이며, 전부 더했을 때 1이 된다.
- 여기에 Cross_Entropy Loss를 적용해준다 (= 해당 수식의 Loss를 정의한다)
- 이런 multi-class 프로세스를 Softmax 함수로 처리한다.
특징
- max : exponential 함수를 통해 큰 수에 가중치를 부여하여 부각시킨다.
- soft : maximum 외의 나머지 값들을 0으로 처리하지 않고 어느정도 값을 부여한다.
(binary class에서는 sigmoid, multi-class에서는 softmax)

유저가 왜 그랬을까