이미지 증강 관련 배경지식
1. 이미지 로드하기
- 첫 번째 방법:
matploblib.pyplot imread()-
두 번째 방법:
PIL(pillow) - flip, rotation, zoom이 모두 가능 -
세 번째 방법:
OpenCV로 불러오는 방법 (Computer Vision - 특히 영상처리 관련)
2. activation map
- 활성화 함수를 통과한 feature map을 의미한다.
3. Maxpooling
- 가로 세로의 길이 축소 (권장 이미지 사이즈는 따로 없음)
- 이미지 크기를 줄여 효율적 계산 + 데이터 압축
- 이미지를 추상화해주므로, 자세한 학습 방지 (=과적합 방지)
- stride값은 지정해줄 수 있으며 고정이 아님. - stride를 크게 설정하면 용량이 줄어들고 학습속도가 빨라지지만 세부내용을 학습하지 않아 과소적합된다.
- 과대적합: 데이터의 노이즈나 원하지 않는 세부부분까지 학습.
- 기타: AveragePooling, MinPooling
4. SoftMax
- 다중분류에 사용 (가장 큰 확률값을 클래스의 답으로 사용)
- np.argmax() 사용 시 가장 큰 확률값에 대한 인덱스 반환 (=가장 큰 값의 인덱스를 사용)
5. 이진분류
- 출력 activation으로 sigmoid를 사용
- 0 ~ 1 사이 확률값을 반환.
- 특정 임계값 기준 분류. (기본값: 0.5)
- sigmoid는 출력층, 은닉층에서 사용 가능
- 은닉층에서 사용 시, 역전파 단계에서 미분값이 0이 되는 문제 발생 위험 (=기울기 소실)
6. PIL, OpenCV
-
포토샵에서 이미지 사이즈를 줄이듯 조정.
-
이미지 사이즈 축소
장점: 빠른 연산.
단점: 이미지 왜곡(크게 만들어도 동일) -
이미지 사이즈 확대
장점: 정확도 상승 (학습량 확대)
단점: 시간 소요
7. tensorflow + Keras 활용 전처리
# 접기
tf.keras.layers.RandomFlip
# 돌리기
tf.keras.layers.RandomRotation
# 확대
tf.keras.layers.RandomZoom
# 자르기
tf.keras.layers.RandomShear
# 밝히기
tf.keras.layers.RandomBrightness
# RGB값 변경
tf.keras.preprocessing.image.random_channel_shift
# whitening 효과는 불러올 때 지정
datagen = ImageDataGenerator(zca_whitening=True) 레이어 구성
데이터셋 분할
# validation split을 통해 학습:검증 비율 = 8:2로 분할
from tensorflow.keras.preprocessing.image import ImageDataGenerator
datagen = ImageDataGenerator(rescale+1/255.0, validation_split=0.2)모델 구성
num_classes = len(class_names)
model = Sequential([
layers.Rescaling(1./255, input_shape=(img_height, img_width, 3)),
layers.Conv2D(filters=16, kernel_size=3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(filters=64, kernel_size=3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Flatten(),
layers.Dense(units = 128, activatioin = 'relu'),
layers.Dense(num_classes)
])컴파일
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])- filters 갯수: feature map의 갯수
- kernel_size (커널의 행, 열): filter size
- paddinng
* 'valid': 유효한 영역만 출력 (출력 이미지 사이즈 == 입력 사이즈)- 'same': 출력 이미지 사이즈 == 입력 이미지 사이즈
레이어 종류
- Conv1D 층으로 sequence, 텍스트 데이터, 시계열 데이터(순서가 중요) 등 처리
- Conv2D 층으로 이미지 데이터 , 스펙트로그램 오디오 데이터
- Conv3D 층으로 볼륨 데이터, 비디오 데이터 처리
- 순환 신경망: 오디오 데이터, 텍스트 데이터, 시계열 데이터, 또는 비디오
- 기타: MLP(밀집층)을 통한 벡터 데이터 처리
# 유의사항
합성곱 신경망은 공간적인 특성 맵을 벡터로 바꾸기 위해
종종 flatten 층과 전역 풀링 층으로 끝납니다.
그리고 일련의 밀집층(MLP)로 처리하여
분류나 회귀 출력을 만들게 됩니다.과대적합 방지
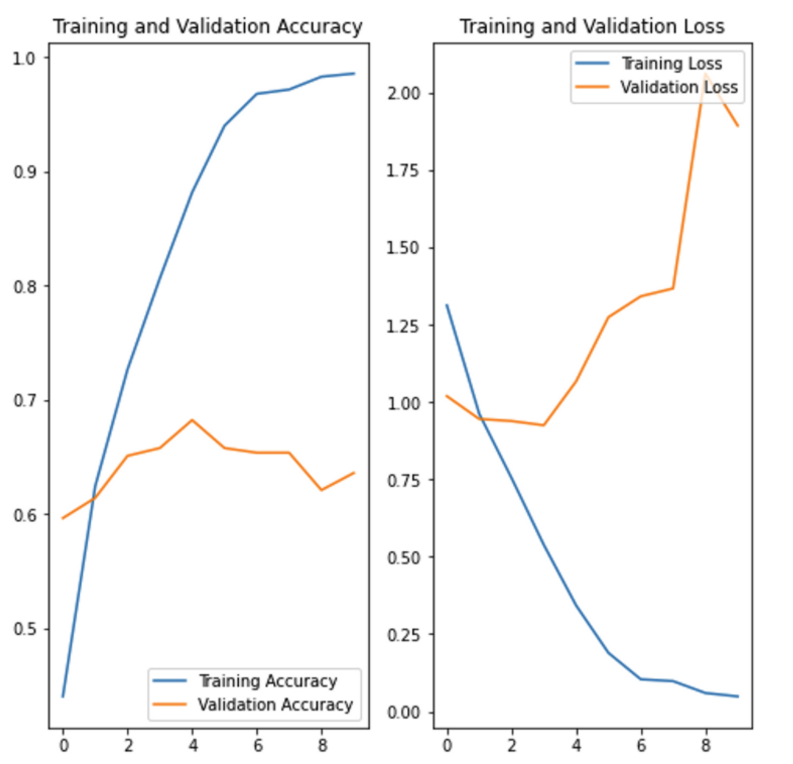
- 노이즈 데이터 등으로 인해, Training loss가 감소하고 Validation loss가 증가한 경우를 과대적합되었다고 표현한다.
- 데이터 증강, Dropout, 전처리 기능 등을 통해 해결 가능하다.
현실세계의 CNN
- 노이즈 등을 크롭, 확대할 경우 문제가 될 수 있음.
- 회전, 반전 등 숫자 6, 9처럼 의미가 변화해서 안 되는 경우 유의
- 색상 변경 (ex. 신호등)
- 증강 시 train에만 해주고, test에는 해주지 않음 (현실세계 문제를 푼다고 가정할 경우 증강하지 않고 판단)
- 증강 시 현실세계 문제와 연관해서 고민

유저가 왜 그랬을까