🤓 Encoder, Decoder부터 이해하자
👂🏻 Encoder, 받아들인다.
- 인코더는 기계가 주어진 문장을 모두 읽고, 단어 정보를 압축화해서 벡터로 반환합니다.
- 인코더, 디코더는 사실 두 개의 RNN 구조 입니다.
- 둘 다 수많은 RNN 셀로 구성되어 있습니다.
- 인코더의 각 셀들이 단어를 입력 받은 후, 인코더 내 마지막 단계에서 벡터화한 은닉층을 디코더의 첫 RNN 셀에 넘겨주게 되는 것입니다.
- 인코더가 만든 이 벡터를 Context Vector라고 지칭합니다.
👄 Decoder, 뱉는다.
- 디코더는 인코더가 만든 Context Vector을 받습니다.
- 디코더가 출력을 하기 위해서 첫 번째로 입력해줄 토큰은 'Sentence of Sequence', 줄여서 'SoS'라고 합니다.
- 디코더의 셀들은 입력 단어로부터 다음에 올 단어를 예측한 후, 다시 그것을 다음 셀의 입력으로 보냅니다.
- 디코더는 기본적으로 다음에 올 단어를 예측하고, 예측 단어를 다음 RNN 셀에 입력하는 방식을 반복합니다.
- 이는 문장의 끝을 의미하는 'End of Speed', 즉 'eos' 토큰이 나타날 때 까지 반복됩니다.
👆 Attention이란?
- 등장 배경
- 인코더의 마지막 은닉층에서는, 인코더의 모든 흐름에서 나온 정보를 우겨넣게 됩니다.
- LSTM으로 장기기억 소실 (Long Term Dependency)을 해결해도, 뒷쪽 타임 스텝에서 앞쪽의 정보를 잘 저장하지 못하는 현상이 발생하기도 했습니다. 이를 보완하기 위해 Attention이 등장하게 됩니다.
-
attention이란, Decoder가 각 time step에서 결과를 생성할 때, 몇 번째 time step을 더 집중(Attention)해야 하는 지를 스코어 형태로 나타낸 것입니다.
-
각 디코더의 타임 스텝마다 인코더의 hidden state vector 간의 유사도를 계산합니다.
-
그리고 인코더의 타임스텝들 중 몇 번째 타임 스텝에 속하는 hidden state vector가 더 중요한 정보를 담고 있는지 적절히 고려할 수 있게 됩니다.
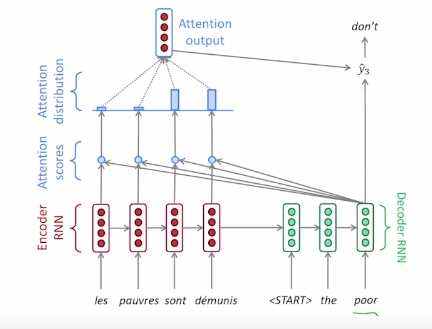
- 디코더가 계산한 어텐션 스코어를 각 셀마다 곱해주고 (=내적하고), 최종적으로 반환된 값(확률)을 비교 확인합니다.
- 참고자료
[네이버 부스트코스]
https://m.boostcourse.org/ai330/lecture/1455755
[딥 러닝을 이용한 자연어 처리 입문] 위키독스
https://wikidocs.net/24996

유저가 왜 그랬을까