프로그래머스 인공지능 미니 데브코스
1.[프로그래머스 인공지능 미니 데브코스] 수업 정리 -1- [Python으로 시각화하기 - Matplotlib]
matplotlib 파이썬의 데이터 시각화 library 라이브러리 와 프레임워크의 차이 라이브러리 : 라이브러리 내부의 코드를 조합해서 원하는 결과를 내야한다. 프레임워크 : 이미 틀이 짜여있음, 틀에 내용물을 채워가며 결과를 내야한다. 1.matplotlib 설
2.[프로그래머스 인공지능 미니 데브코스] 수업 정리 -2- [Web Application with Flask]
Python 기반 마이크로 웹 프레임워크다양한 장르의 프로젝트를 진행하다보면 프로젝트 관리를 위해서 독립적인 환경을 구축하는게 편하다.라고 배웠지만 잘 안 되어 찾아보니 powershell 은 조금 다른 방법이였다.으로 실행한다. (이때 만일 코드가 안된다면 관리자 모
3.[프로그래머스 인공지능 미니 데브코스] 수업 정리 -3- [Web Application with Django]
: python 기반 웹 프레임워크한 project는 여러 App로 구성되어 있다.각 기능에 대해 독립적으로 구현할 수 있다는 것이 장점이다.디자인 패던 - 각 코드의 모듈화를 통해 각 코드가 독립적으로, 유기적으로 원하는 기능을 실행할 수 있도록 만들어주는 구조MVC
4.[프로그래머스 인공지능 미니 데브코스] 수업 정리 -4- [Django으로 동적 웹 페이지 만들기]

4. Model : 어떤 정보의 요청에 대해 DB를 관리하는 곳이다. Template과 View에 정보를 제공한다. : 데이터베이스는 정보를 정렬(구조화)하여 user가 쉽게 참조 할 수 있는 시스템이다. RDB(Relational DB)는 테이블(row, colum
5.[프로그래머스 인공지능 미니 데브코스] 수업 정리 -5- [웹 스크래핑 기초 I]

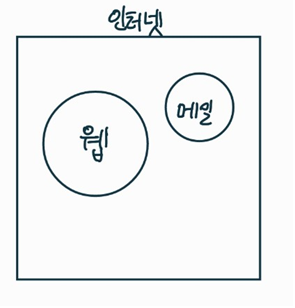
태초에 컴퓨터가 있었다!두 컴퓨터를 연결하는 네트워크(Network)의 탄생네트워크를 묶어 근거리 지역 네트워크(LocalArea Network, LAN)탄생범지구적으로 연결된 네트워크 Inter Network - 인터넷(Internet) 탄생: 인터넷에서 정보를 교
6.[프로그래머스 인공지능 미니 데브코스] 수업 정리 -6- [웹 스크래핑 기초 II]
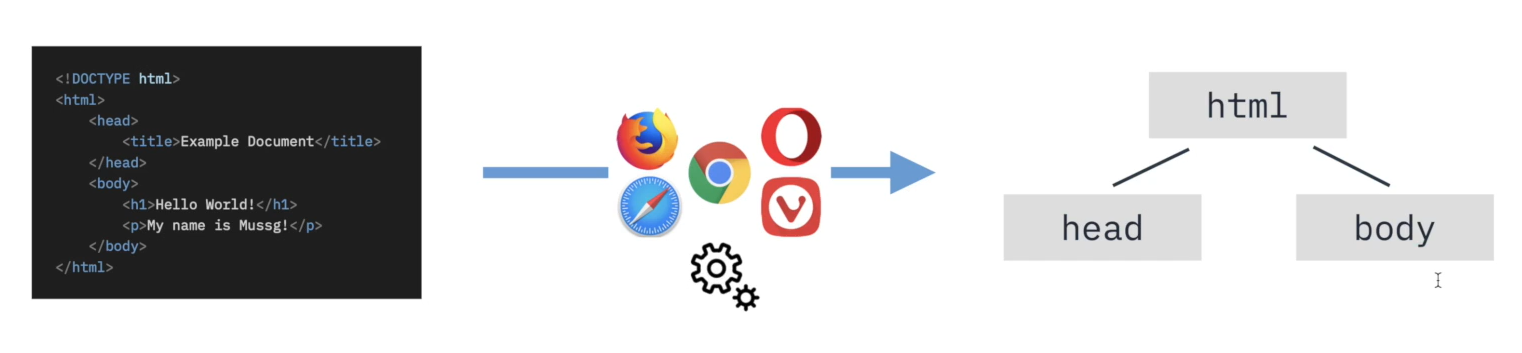
브라우저의 렌더링 엔진은 웹 문서를 로드한 후, 파싱을 진행이를 DOM(Document Object Model) 이고 한다.각 노드를 객체로 생각하면 문서를 더욱 편리하게 관리할 수 있다.DOM Tree를 순회해서 특정 원소를 추가할 수 있다.DOM Tree를 순회해서
7.[프로그래머스 인공지능 미니 데브코스] 수업 정리 -7- [웹 스크래핑 기초 III]
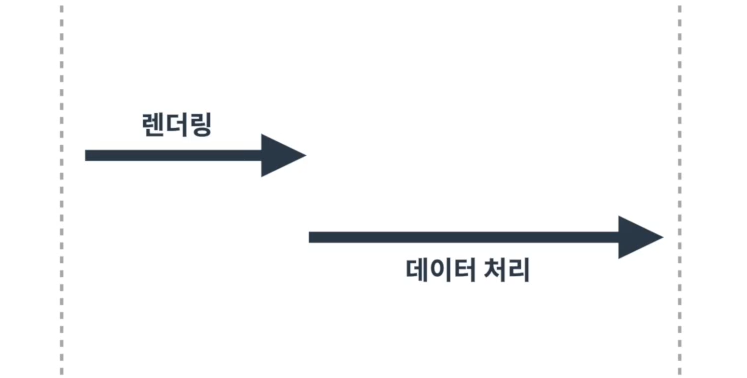
웹 페이지는 어떻게 생성되냐에 따라 크게 2가지로 구분1\. HTML 내용이 고정된 정적(static) 웹 사이트 \-> ex) 변경이 없는 사이트 \-> 같은 주소로 보내면 항상 같은 값을 받음 \-> HTML 문서가 완전하게 응답2\. HTML 내용이 변하는 동적(
8.[프로그래머스 인공지능 미니 데브코스] 수업 정리 -8- [웹 스크래핑 기초 IV]
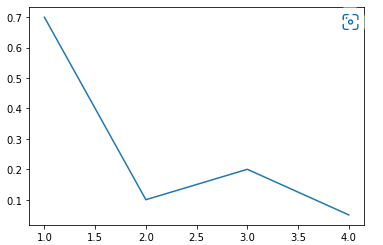
1. 시각화라이브러리, Seaborn 데이터 추출, 그리고 끝? 지금 까지 한 결과는 대부분 텍스트이다. 정보를 요약해서 한 눈에 보여주면 좋을 듯! 시각화(Visualization)가 필요! > 여러 기법을 통해서 스크래핑을 진행할 수 있었다. 스크래핑 결과가 너무
9.[프로그래머스 인공지능 미니 데브코스] 수업 정리 -9- [데이터 씹고 뜯고 맛보고 즐기기 - EDA]
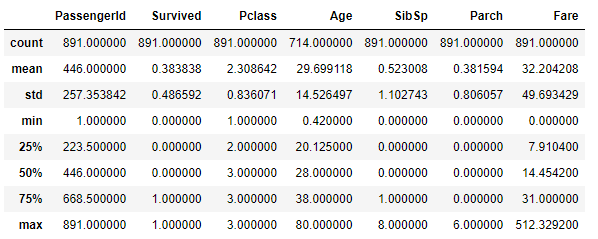
1. 탐색적 데이터 분석 EDA EDA? 데이터 그 자체를 보는 눈 데이터를 분석하는 기술적 접근은 매우 많다. 데이터 그 자체만으로부터 인사이트를 얻어내는 접근법! 통계적 수치나 numpy/pandas등으로 알 수 있다. EDA의 Process 분석의 목적과 변수
10.[프로그래머스 인공지능 미니 데브코스] 수업 정리 -10- [클라우드를 활용한 머신러닝 모델 Serving API 개발]

1. 클라우드 기초 Before Cloud Computing Backgrounds of Cloud computing Cloud Computing Features of Cloud Computing 클라우드 컴퓨팅 운용 모델 클라우드 서비스 제공 모델 AWS Cloud C
11.[프로그래머스 인공지능 미니 데브코스] 수업 정리 -11- [인공지능과 기계학습 소개]
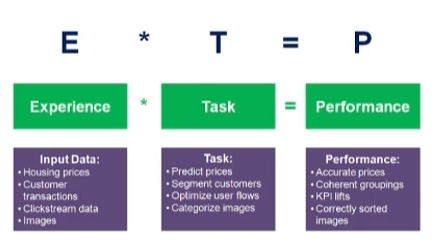
인공지능이란? 사전적 의미 인간의 학습 능력과 추론능력, 지각능력, 자연언어의 이해능력 등을 컴퓨터프로그램으로 실현한 기술 인간처럼 생각하고 행동하는 기기의 탄생! 학습 일상 속 인공지능 음성인식(siri) 추천시스템 (eBay, Netflix) 자율주행 (Waymo
12.[프로그래머스 인공지능 미니 데브코스] 수업 정리 -12- [기계학습과 수학]
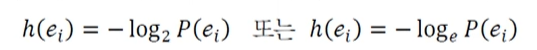
기계학습에서 수학의 역할 수학은 목적함수를 정의하고, 목적함수의 최저점을 찾아주는 최적화 이론 제공 최적화(optimization) 이론에 학습률(learning rate), 멈춤조건과 같은 제어를 추가하여 알고리즘 구축 사람은 알고리즘을 설계하고 데이터를 수집 선형
13.[프로그래머스 인공지능 미니 데브코스] 수업 정리 -13- [Machine Learning 기초 - E2E 머신러닝 프로젝트]
End-to-End 머신러닝 프로젝트 부동산 회사에 막 고용된 데이터 과학자라고 가정하고 예제 프로젝트를 처음부터 끝까지 (End-to-Enf) 진행하겠습니다. 주요 단계는 다음과 같습니다. 큰 그림을 봅니다 (look at the big picture). 데이터를
14.[프로그래머스 인공지능 미니 데브코스] 수업 정리 -14- [Deep Learning: 신경망의 기초 - 다층퍼셉트론 ]
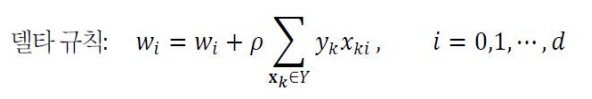
신경망 기초 인공신경망과 생물신경망 사람의 뉴런(neuron) : 두뇌의 가장 작은 정보처리 단위 : 구조 = 세포체는 간단한 연산 = 수상돌기는 신호 수신 = 축삭은 처리 결과를 전송 : 사람은 10^11개 정도의 뉴런을 가지며, 각 뉴런은 약 1000개 다른
15.[프로그래머스 인공지능 미니 데브코스] 수업 정리 -15- [Deep Learning: 신경망의 기초 - 다층퍼셉트론 II]

다층 퍼셉트론 퍼셉트론 : 선형 분류기(linear classifier) 한계 : 선형 분리 불가능한 상황에서 일정한 양의 오류 다층 퍼셉트론의 핵십 아이디어 은익층을 둔다. 은닉층은 원래 특징 공간을 분류하는 데 훨씬 유리한 새로운 특징 공간으로 변환한다. 시그모이
16.[프로그래머스 인공지능 미니 데브코스] 수업 정리 -16- [Deep Learning: 신경망의 기초 - 심층학습기초 I]
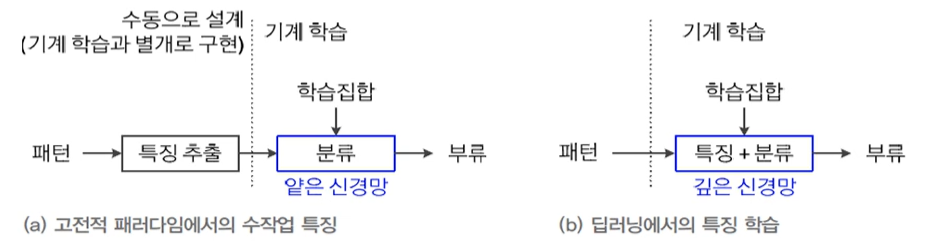
다층 퍼셉트론(multilayer perceptron)에 은닉층(hidden layer)을 여러 개 추가하면 깊은 신경망(deep neural networks)이 됨심층학습은 깊은 신경망의 학습심층학습은 새로운 응용을 창출하고 인공지능 제품의 성능을 획기적으로 향상 \
17.[프로그래머스 인공지능 미니 데브코스] 수업 정리 -17- [Deep Learning: 신경망의 기초 - 심층학습기초 II]
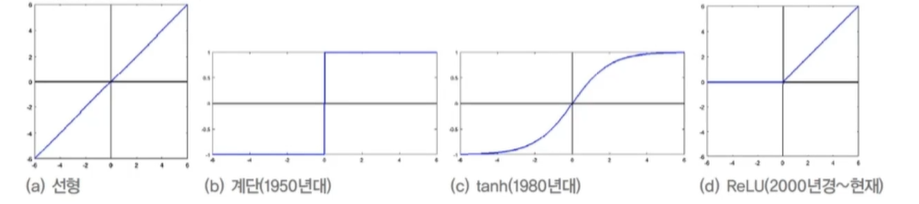
관점의 변화 : 동일한 객체라도 영상을 찍는 카메라의 이동에 따라 모든 픽셀값이 변화됨경계색(보호색) 으로 배경과 구분이 어려운 경우조명에 다른 변화기형적인 형태의 영상 존재일보가 가려진 영상 존재같은 종류 간의 변화가 큼선형함수인 컨볼류션과 비선형 함수인 활성함수의
18.[프로그래머스 인공지능 미니 데브코스] 수업 정리 -18- [Deep Learning: 신경망의 기초 - 심층학습기초 III]
AlexNetVGGNetGoogLeNetResNet과거에는 매우 어렵고 도전적인 문제였음ImageNet2만 2천 여 부류에 대해 부류별로 수백~수만장의 사진을 인터넷에서 수집하여 1500만여 장의 사진을 구축하고 공개 (현재, 부류와 개수가 추가됨)ILSVRC(imag
19.[프로그래머스 인공지능 미니 데브코스] 수업 정리 -19- [Deep Learning: 신경망의 기초 - 심층학습 최적화]
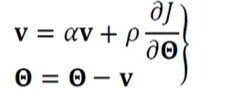
과학 혹은 공학에서 최적화 : 우주선의 최적궤도, 운영체제의 작업 할당 계획 등 기계학습의 최적화도 매우 복잡함 : 훈련집합으로 학습을 마친 후, 현장에서 발생하는 새로운(unknown)샘플을 잘 예측해야 함 -> 일반화 능력이 좋아야 함 훈련집합은 전체 데이터(실제
20.[프로그래머스 인공지능 미니 데브코스] 수업 정리 -20- [Deep Learning: 신경망의 기초 - 심층학습 최적화2]
딥러닝
21.[프로그래머스 인공지능 미니 데브코스] 수업 정리 -21- [Recommendation system: 추천 엔진1]
추천 엔진이란? 사용자와 아이템 사용자 : 서비스를 사용하는 사람 아이템 : 서비스에서 판매하는 물품 -> 다른 사용자가 물품이 될 수 있음 보통 서비스가 성장하면 사용자/아이템의 수도 같이 성장함 특히 사용자의 성장도가 훨씬 커짐 하지만 아이템의 수가 커지면서 아이
22.[프로그래머스 인공지능 미니 데브코스] 수업 정리 -22- [Recommendation system: 추천 엔진2]
기념비적인 추천 엔진 경진 대회2006년부터 3년간 운영된 넷플릭스의 기념비적인 추천 엔진 경진대회넷플릭스 추천 시스템 품질을 10% 개선하는 팀에게 $1M 수여 약속RMSE(Root Mean Square Error)가 평가 기준으로 사용됨네플릭스 브랜드 인지도도 올라
23.[프로그래머스 인공지능 미니 데브코스] 수업 정리 -23- [Recommendation system: 협업 필터링 기반 추천 엔진]
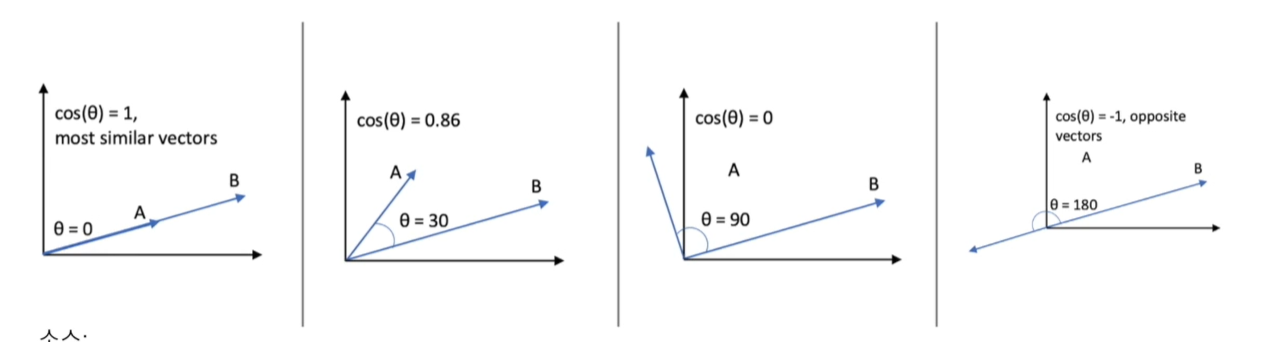
추천 엔진 아키덱쳐 전체적인 페이지에서 어떻게 보여주고 추천할지 생각해야한다. 추천엔진 기본적인 구조 협업 필터링 소개 기본적으로 다른 사용자들의 정보를 이용하여 내 취향을 예측하는 방식 크게 세 종류가 존재 사용자 기반 나와 비슷한 평점 패턴을 보이는 사람들을 찾
24.[프로그래머스 인공지능 미니 데브코스] 수업 정리 -24- [Recommendation system: ML 기반 추천 엔진 - SVD & 딥러닝 추천 엔진]

확장성(scalability) : 큰 행렬 계산은 여러모로 쉽지 않음하지만 아이템 기반으로 가면 계산량이 줄어듬Spark을 사용하면 큰 행렬 계산도 얼마든지 가능부족한 데이터(sparse data)많은 사용자들이 충분한 수의 리뷰를 남기지 않음해결책 -> 모델기반 협업
25.[프로그래머스 인공지능 미니 데브코스] 수업 정리 -25- [딥러닝 기초]

인공지능 인공지능이란 기계를 통해 인공적으로 구현된 지능을 의미 기계학습 : 데이터를 반복적으로 학습하여 데이터에 잠재된 특징을 발견 딥러닝 : 깊은 인공 신경망을 화룡하여 더 높은 정확도를 얻음 1. 지도학습(Supervised Learning) 지도학습은 명시적인
26.[프로그래머스 인공지능 미니 데브코스] 수업 정리 -26- [GAN]
꼼꼼한 논문 리뷰와 코드 실습 생성모델 Generative Adversarial Networks(NIPS 2014) 이산확률 분포 확률 변수 X의 개수를 정확히 셀 수 있을 때 이산확률분포라 말한다. 연속 확률 분포 확률 변수 X의 개수를 정확히 셀 수 없을 때 연