꼼꼼한 논문 리뷰와 코드 실습
생성모델
Generative Adversarial Networks(NIPS 2014)
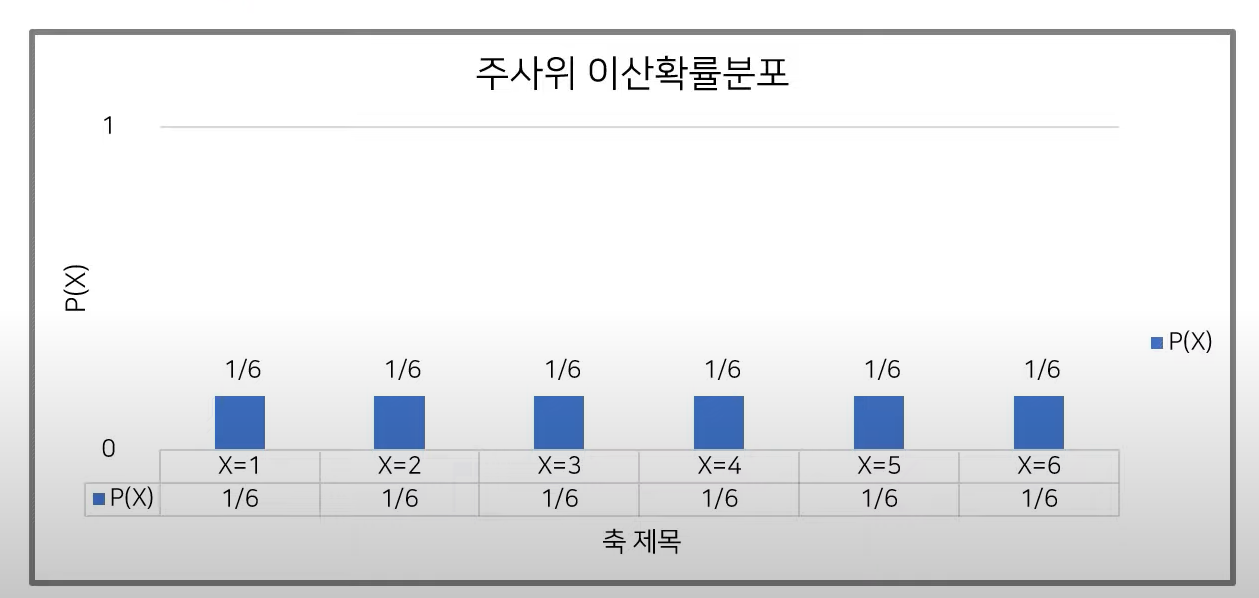
이산확률 분포
확률 변수 X의 개수를 정확히 셀 수 있을 때 이산확률분포라 말한다.
연속 확률 분포
확률 변수 X의 개수를 정확히 셀 수 없을 때 연속확률 분포라혹 한다.
확률 밀도 함수를 이용해 분포를 표현
연속적인 값 예시 : 키, 달리기 성적, 정규분포
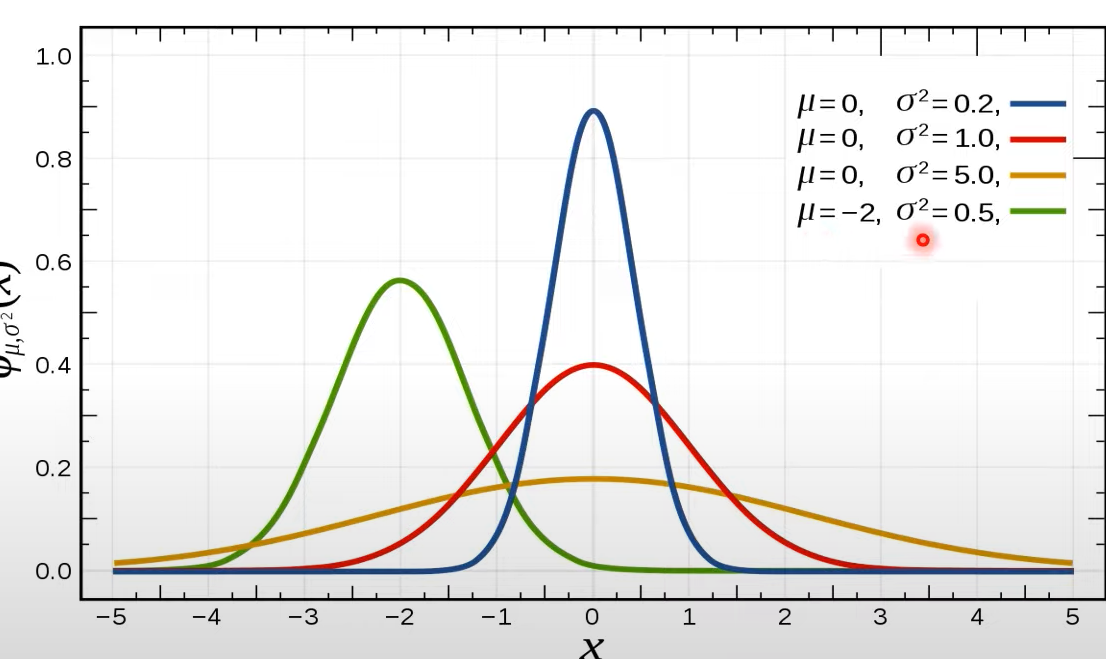
실제 세계의 많은 데이터는 정규분포로 표현할 수 있다.
이미지 데이터에 대한 확률분포
이미지 데이터는 다차원 특징 공간의 한 점으로 표현된다.
이미지 분포를 근사하는 모델을 학습할 수 있다.
사람의 얼굴에는 통계적인 평균치가 존재할 수 있다.
모델은 이를 수치적으로 표현할 수 있게 된다.
이미지에서의 다양한 특징들이 각각의 확률 변수가 되는 분포를 의미
다변수 확률 분포(Multivariate probability distribution)
생성 모델(Generative Models)
생성 모델은 실존하지 않지만 있을 법한 이미지를 생성할 수 있는 모델을 의미한다.
이미지 데이터의 분포를 근사하는 모델 G를 만드는 것이 생성 모델의 목표
모델 G가 잘 동박한다는 의미는 원래 이미지들의 분포를 잘 모델링 할 수 있다는 것을 의미
GAN이 대표적
GAN
생성자(generator)와 판별자(discriminator) 두 개의 네트워크를 활용한 생성 모델이다.
목표 함수를 통해 생성자는 이미지 분포를 학습할 수 있다.
생성자 : 노이즈 벡터(Z) 를 받아서 new data instance 만듬
판별자 : 이미지(x)를 받아 이미지가 진짜 같은 것을 확률 값을 부여 probability : a sample came from the real distribusion(Real : 1~ Fake : 0)
GAN에서의 기댓값 계산 방법
프로그램상에서 기댓값을 계산하는 가장 간단한 방법
단순히 모든 데이터를 하나씩 확인하여 식에 대입한 뒤에 평균을 계산하면 된다.
Ex~pdata(x)[logD(x)]
원본 데이터 분포에서의 샘플 x를 뽑아 logD(x)의 기댓값 계산
Ez~pz(z)[log(1-D(G(z)))]
노이즈 분포에서의 샘플 z를 뽑아 log(1-D(G(z)))의 기댓값 계산
기댓값 공식
기댓값은 모든 사건에 대해 확률을 곱하면서 더하여 계산할 수 있다.
이산확률변수에 대한 기댓값
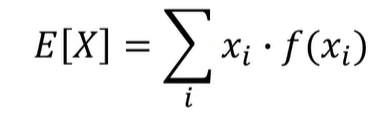
연속확률변수에 대한 기댓값
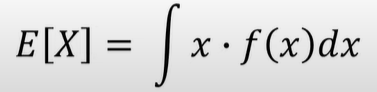
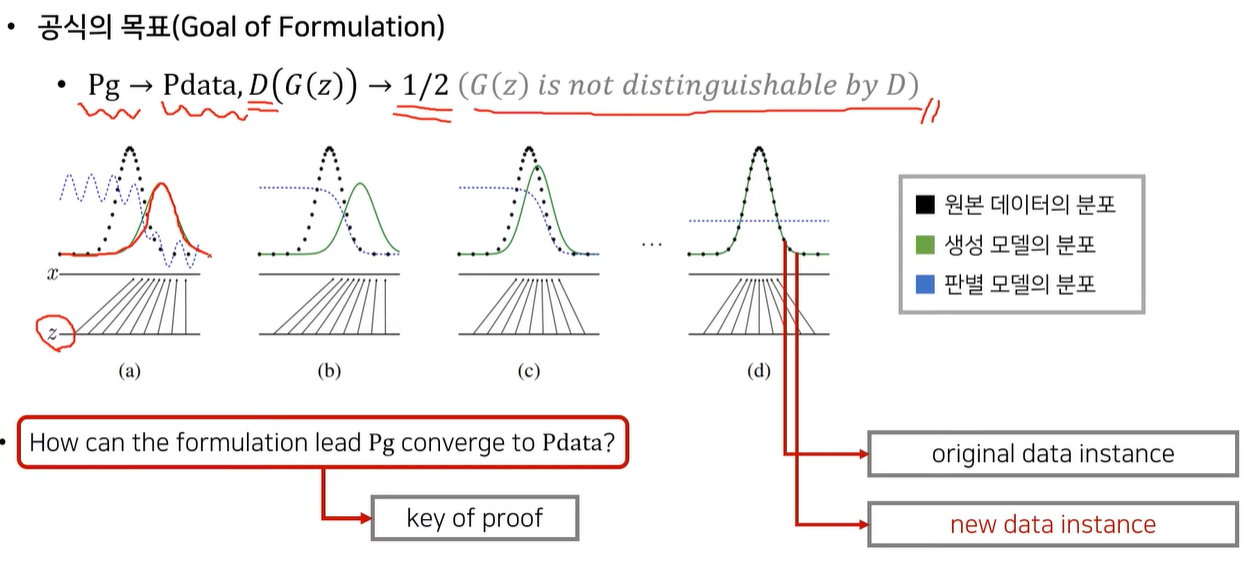
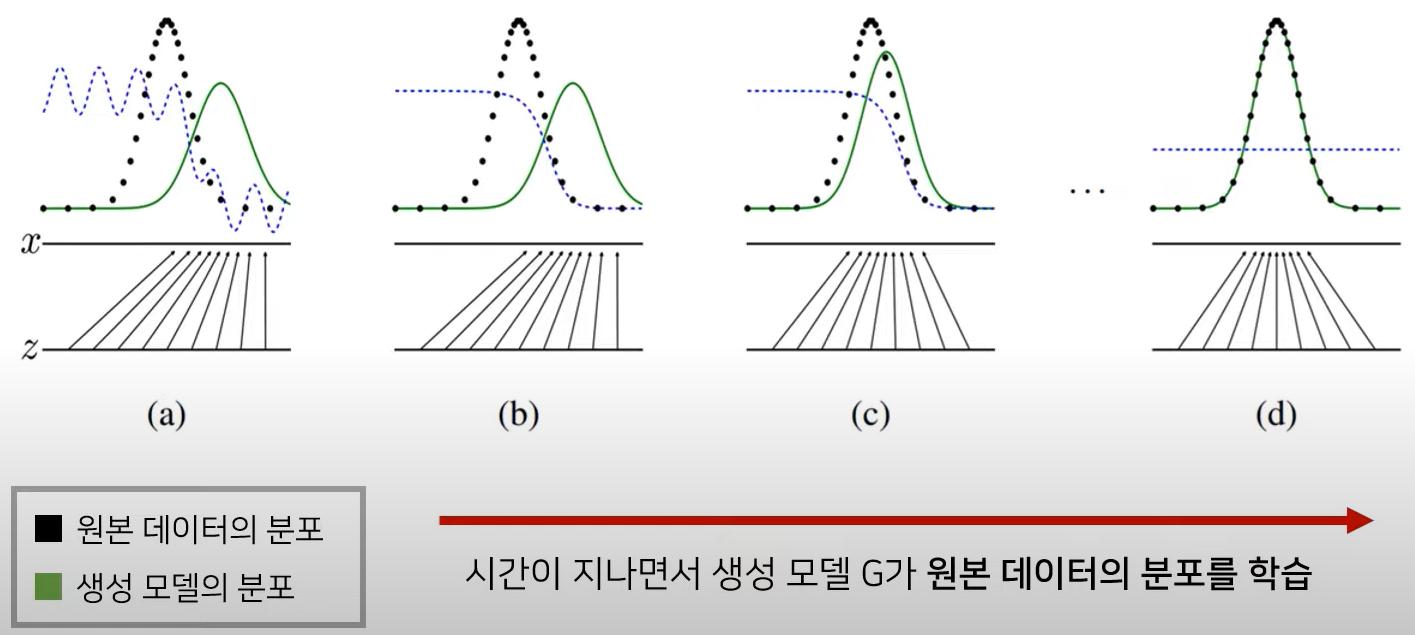
GAN의 수렴과정