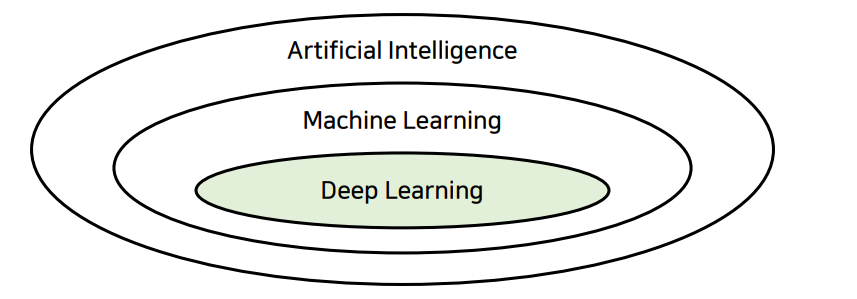
인공지능
인공지능이란 기계를 통해 인공적으로 구현된 지능을 의미
기계학습 : 데이터를 반복적으로 학습하여 데이터에 잠재된 특징을 발견
딥러닝 : 깊은 인공 신경망을 화룡하여 더 높은 정확도를 얻음
1. 지도학습(Supervised Learning)
지도학습은 명시적인 정답을 제공하면서 학습시키는 유형
회귀(Regression)
특정한 데이터가 주어졌을 때 결과를 연속적인 값으로 예측
ex) 영어 공부를 7시간 했다면, 몇 점 나올까?
학습에 따른 영어점수 예측
거리에 따른 이동시간 예측
업무에 따른 매출 예측
분류(Classification)
종류에 따라서 데이터를 분류한다.
ex) 이 이미지는 고양이인가 강아지인가
손글씨 분류
강아지/고양이 분류
배경 분류
2. 비지도 학습(Unsupervised Learning)
비지도 학습은 명시적인 정답을 제공하지 않으면서 학습시키는 유형
클러스터링(Clustering)
데이터를 특정한 기준으로 묶는다
비슷한 유형의 사용자끼리 그룹화
ex) 사용자들을 3가지 집단으로 나누자
차원축소(Dimensionality Reduction)
차원을 줄여 데이터 내 유의미한 특징을 추출
고차원 데이터의 차원을 축소하여 새로운 차원의 데이터를 생성
ex) 이 이미지들을 2차원 공간에 투영시켜서 시각화 할 수 있을까?
데이터 시각화, 데이터 압축을 통한 복잡도 개선
도구
파이토치
PyTorch는 빠르고 유연한 딥러닝 연구 플랫폼
GPU를 활용한 연산 가속을 지원
Google Colab
나만의 머신 러닝 개발 환경을 1초 만에 가질 수 있도록 해주는 서비스
PyTorch를 포함한 머신 러닝 관련 라브러리가 기본적으로 설치
무료 서비스일 뿐 아니라 GPU 런타임 지원
다른 사람과 함께 코드를 공유하며 협업하기 좋은 개발 환경
벡터
크기와 방향을 모두 가진 물리적인 양을 나타낼때 사용
변위벡터: 점 a와 점 b로 구성됨
동치: 두 벡터의 길이와 방향이 같을 때 동치라고 함
어떤 경우에는 좌표계를 도입하고 벡터를 대수적으로 다루는 것이 최선인 경우가 있ㅇㅁ
변위벡터 대신에 위치벡터를 효과적으로 사용할 수 있다.
성분
직교 좌표계의 원점에 벡터의 시점을 놓을 때의 종점
일반적으로 평면에 있는 점을 (x1,x2)형태로 표현
성분의 경우<x1,x2>로 표현
위치벡터
원점으로 부터 점에 이르는 벡터
행렬(Matrix)
행렬이란, M행 N열로 나열된 2차원 배열이다.
프로그래밍에서는 2차원 배열을 행렬처럼 이용
필요성: 현실 세계의 많은 문제는 행렬을 이용해 해결할 수 있다.
행렬의 연산
행렬의 덧셈과 뺄셈
두 행렬의 합이나 차를 계산할 때는 동일한 위치에 상응하는 원소끼리 계산
기본적으로는 두 행렬의 크기가 같을 때 사용할 수 있다.
행렬과 스칼라의 연산
행렬은 상수(스칼라)와 연산할 수 있다
스칼라 연산을 할 대는 각 원소에 대하여 연산을 수행한다.
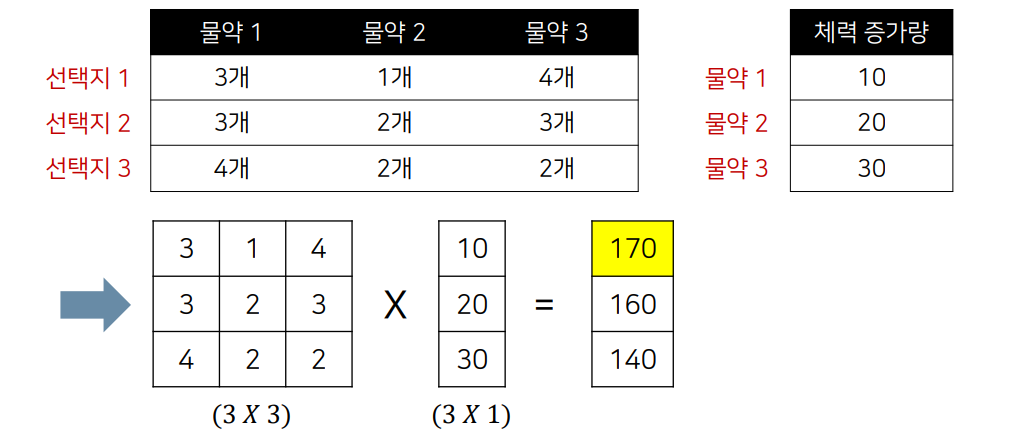
행렬의 곱셈
행렬과 스칼라의 연산
두 행렬 A와 B는 곱할 수 있다
행렬 A의 열의 개수와 행렬 B의 개수가 같아야한다
두 행렬의 곱 AB에서 행렬 AB의 크기는 A의 행과 B의 열의 개수
pyTorch 의 Tensor
서로다른 형태의 Tensor 연산
브로드캐스트 : 형태가 다른 행렬을 연살할 수 있도록 행렬의 형태를 동적으로 변환
형태 변경
Tensor는 인덱싱 표기법을 사용할 수 있다
다양한 방법으로 형태를 변경할 수 있다
선형 회귀
현실 세계의 많은 데이ㅓ는 선형적인 구조를 내재한다
ex) 많은 시간을 공부할수록 그 시간에 비례하여 실력이 늘지 않을까
ex) 많은 돈을 투자할수록, 더 성능이 좋은 제품을 살 수 있지 않을까?
선형회귀(Linear regression)
주어진 데이터를 학습시켜서 가장 합리적인 선형 함수를 찾아내는 접근 방법을 의미한다.
데이터는 3개 이상일 때 의미가 있다
데이터를 가장 잘 나타내는 선형함수는?
좋은 가설의 기준
선형함수를 이용해 직선을 표현할 수 있다
가설함수(파라미터)를 수정해나가면서 가장 함리적인 식을 찾아낼 수 있다.
가설함수: H(x) = Wx + b
학습 개요
선형 회귀에서의 학습은 주어진 데이터를 이용해 선형 함수를 수정해 나가는 것이다
학습을 거쳐 가장 합리적인 파라미터를 도출한다.
학습을 많이 해도 완벽한 식을 찾아내지 못할 수도 있다.
하지만 실제 사례에서는 근삿값을 찾는 것만으로도 충분할 때가 많다
딥러닝은 함수를 적절히 근사해주는 소프트웨어이다.
비용함수(Cost Function)
비용
가설이 얼마나 정확한지 판단하는 기준
가설이 정확하지 않다면, 비용이 많이 발생
비용을 줄이는 방향으로 학습을 진행
일반적으로 비용을 계산할 때는 실제값과 예상값이 얼마나 다른가를 기준으로 설정
MSE(Mean Squared Error)
모든 데이터에 대한 (실제값 - 예상값)^2의 합으로 비용을 계산
비용구하기
y = 2x
데이터의 수가 작을 때 선형함수를 간단히 찾을 수 있다
데이터의 수가 많을 때도 쉽게 계산 가능한가?
비용을 기계적으로 줄이는 방법 필요

미분(Ordinary Derivative)
입력 x에 대하여, 함수f의 기울기를 알려주는 함수
입력 x에 대하여, 함수 f가 알마나 민감하게 변화하는지 (순간변화율)을 알려주는 함수
미분이란?(Differentiation) 도함수 f'(x)를 계산하는 작업
어떠한 함수 f(x)가 있을 때 , 특정한 점 a의 위치에서의 기울기 혹은 순간 변화율 값을 구하고 싶다면 f'(a)를 계산
f(x)의 변화량 / x의 변화량
특정함수에서 x가 h만큼 변할 때의 기술기 계산
h / f(x+h) - f(x)
도함수란 x에서의 순간 변화율을 알려주는 함수,h = 0일 때의 값을 계산해야한다.
미분은 인고지능 분야에서 뉴럴 네트워크를 학습(training)을 학습 시키기 위한 과정에서 사용된다
뉴럴 네트워크의 파라미터를 기울기 값을 기준으로 학습을 시키는 방법을 주로 이용
실제로 h를 0.0001 정도로 설정하여 근사할 수도 있으나 기계학습 라이브러리에서는 실제로 도함수를 계산하여 학습을 진행하며, 레이어가 많으므로 연쇄법칙(chain-rule)을 이용하게 된다
편미분(Partial Derivative)
편미분: 다변수 함수(multivariate function)에서 하나의 변수를 기준으로 미분하는 작업
미분할 때 다른 변수는 모두 상수(constant) 취급
실제로 딥러닝 모델에서 입력(input)이나 가중치(weight)값들이 다변수 벡터 형태이다
딥러닝 모델에서 학습(training) 과정은 편미분을 통해 이루어진다
딥러닝 모델은 다수의 레이어로 구성되어 있기 때문에 연쇄법칙(chain-rule)을 이용
경사하강(Gradient Descent)
미분을 이용하면 특정 값에서의 기울기를 구할 수 있다
경사하강 : 기울기를 구하여 비용을 줄이는 방법
ex) 현재 기울기 + -> 가중치를 - 방향으로 이동
현재의 기울기(gradient)를 통해 업데이트 방향을 결정한다
실제함수에서는 여러 극소점(local minimum)이 존재 할 수 있다
극소점: 기울기가 0인 낮은 지점을 의미
최소점(global minimum)을 찾지 못해도 (혹은 없어도) 최소점에 가까운 지점까지 비용을 낮추기 위해 파라미터를 업데이트한다
선형 회귀(H(x) = Wx)
linear regression
(Wx - y)^2의 합을 어떻게 하면 가장 작게 할 수 있을까
가중치 (W)에 대한 비용함수의 기울기를 구한 뒤에 기울기의 반대 방향으로 W를 업데이트
어느정도 크기로?
너무 많이 이동하면 튕겨나갈 수 있으므로, 학습률(learning rate)을 곱하여 이동
학습률이 0.01이라면, -7x0.01만큼 이동
미분을 수행하지 않고 수치적으로 근사하여 기울기를 계산 할 수 있다
실제 딥러닝 프레임워크는 미분을 수행하여 계산한다.

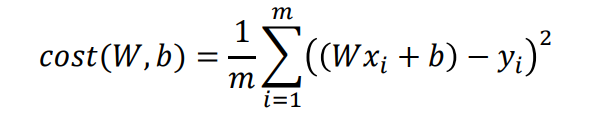

다변수 선형 회귀
한 번에 여러 개의 입력이 들어오면 행렬 곱 이용
H(x) = XW
pytorch 를 이용한 다변수 선형 회귀
분류(Classification)
선형 회귀를 이용해 분류 문제 해결
합격 불합격
-> 결과 값을 0부터 1사이로 제한해야 분류 문제 해결에 효과적
로지스틱 회귀(Logistic Regression)
회귀를 사용하여 데이터가 어떤 클래스에 속할 확률을 0부터 1사이의 값으로 예측
ex) 공부시간에 따른 합격/불합격 분류기
ex) 이미지 특징에 따른 강아지/고양이 분류기
이진 분류와 Sigmoid
sigmoid 함수
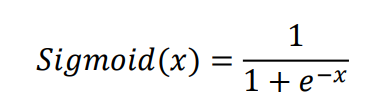
모든 위치에서 미분 가능
0부터 1사이의 확률 값 반환
로지스틱 회귀에 적합
실제 결과 값을 뽑기 전에 Sigmoid 함수에 넣으면?
결과는 항상 0부터 1사이의 확률 값으로 한정된다
다만 기존에서 사용했던 MSE 비용 함수를 그대로 사용하기 어렵다(non-convexity)
엔트로피(Entropy)
엔트로피는 특정 시스템이 얼마나 불안정한지 알려주는 근거로 사용될 수 있다.
예측 확률이 0.1이고, 실제 확률이 1이라고 생각
이는 예측이 많이 틀린 것
매우 큰 값(정보량)이 도출된다.
Logistic Regresstion의 비용 함수
Convex를 보장할 수 있는 비용 함수를 새롭게 정의
y = 1일 때와 y = 0일 때를 나누어서 분류 문제의 비용 함수를 설정할 수 있다
판단 결과가 틀리게 되면 log 함수에 의해 큰 피드백이 가해진다.
결과 적으로 c(H(x),y) = -ylog(H(x))-(1-y)log(1-H(x))
Multinomial Classification
클래스가 여러 개인 문제를 해결하는 방법
Sigmoid를 쓴다면?
아웃풋 뉴런 각각 0부터 1사이의 값을 가짐
모델의 결과를 모두 합쳤을 때 1이 되면 더 좋음
Softmax Function
모델의 결과(Output)을 모두 합한 값이 1이 되도록 만들기 위해 Softmax를 사용
Binary classification -> Sigmoid 사용
Multinomial classification -> softmax 사용
Cross-entropy 비용 함수
마지막 레이어에서 Softmax를 사용할 때
크로스 엔트로피(Cross-entropy)비용함수 이용
딥러닝 개요 : 뉴런 (Neuron)
뉴런은 뇌를 구성하는 기본 단위
뉴런을 수학적으로 모델링할 수 있다
활성화 함수를 이용하여 비 선형성(non-linearity)을 추가한다.
XOR문제
선형적으로 분리되지 않은 문제
Universal Approximation Theorem
하나의 은닉층(hidden layer)를 가지는 뉴럴 네트워크는 임의의 연속인 다변수 함수를 근사할 수 있다.
역전파(Backward-propagation)
앞에서 뒤로만 순전파를 시키는 경우 앞쪽의 가중치는 학습되지 않는다
따라서 역전파가 필요하다
합성함수의 미분(Chain-rule)
인공지능 모델은 여러 개의 다수의 레이어로 구성되어 있다.
그러므로 손실함수(loss function)의 기울기를 계산하는 것은 합성함수를 미분하는 것과 같다.
따라서 합성함수의 미분법은 인공지능 분야에서 매우 중요하다
합성함수의 도함수
f(g(x))' = f'(g(x))g'(x)
대표적인 활성 함수
Sigmoid
뉴럴네트워크 초기 연구에 많이 사용되었으나 최근에는 많이 사용되지 않는다
대표적인 문제점(Gradient vanishing)
ReLU
입력 값이 0 이상일 때만 입력 값을 그대로 출력하는 함수 f(x) = max(0,x)
gradient vanishing 문제를 효과적으로 해결하며 학습 속도를 높인다.
최적화(Optimizer)
GD
전체 데이터를 한 번에 확인한 뒤에 기울기를 계산해 학습
SGD
데이터셋을 쪼갠 뒤에 미니 배치(Mini-batch)단위로 학습
Momentum : 내려오던 방향으로 (관성) 조금 더 많이 학습
Adagrad : 안 가본 곳을 초반에 빠르게 학습하고, 많이 가본 곳은 세밀하게 학습
-> RMSProp : 이전 맥락을 확인하며 세밀하게 학습
Adam : RMSProp + Momentum의 개념을 적절히 사용
DNN for MNIST
PyTorch를 이용해 손글씨 분류기 만들기
CNN
고양이 시각 피질 반응 연구 : 고양이의 시각 피질에는 사선을 인식하는 기능이 있다
다양한 패턴에 따라 뉴런이 반응하는 정도가 서로 다르다는 실험 결과가 도출 된다.
기본적으로 모든 뉴런을 완전 연결(Fully-Connected) 방식으로 연결?
-> 파라미터의 수가 많으며 학습 시간이 길어진다
어떻게 하면 이미지의 공간 정보를 적절히 유지하며 학습할 수 있을까
CNN을 이용하면 많은 파라미터를 공유하고 이미지 특성을 효과적으로 학습할 수 있다.
CNN준비물
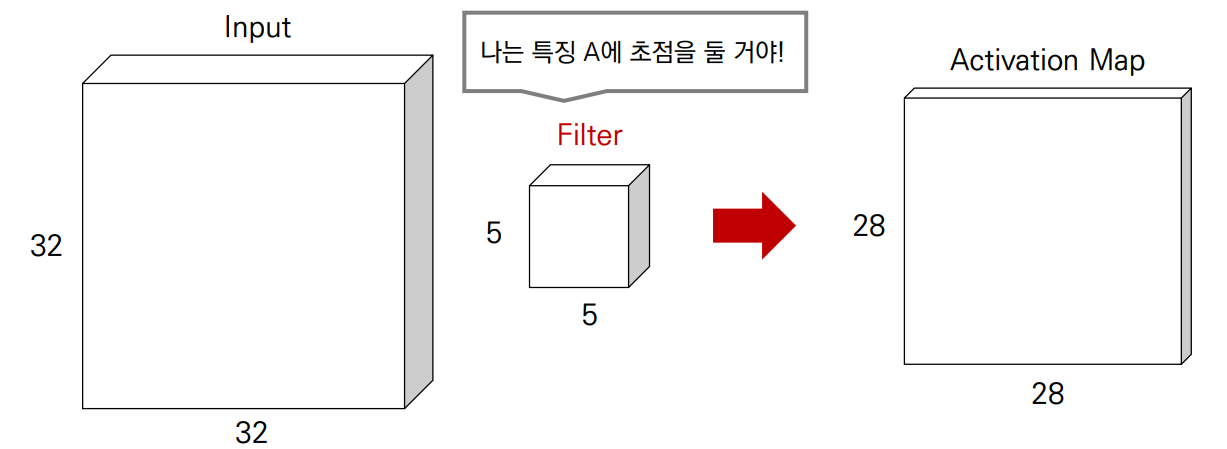
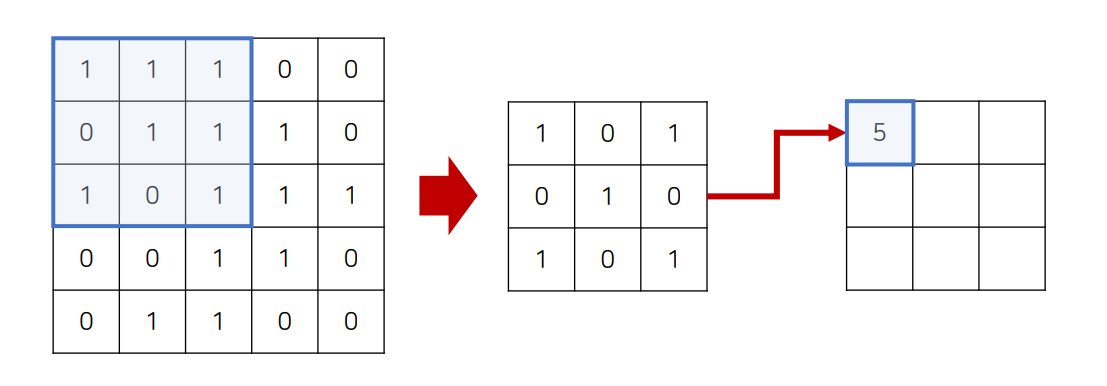
하나의 필터는 이미지에 대하여 슬라이딩 하면서 특징 맵(feature map)을 계산
CNN 모델의 특징 맵(feature Map)
일반적으로 CNN에서 레이어가 깊어질수록 채널의 수가 많아지고 너비와 높이는 줄어든다.
컨볼루션 레이어의 서로 다른 필터들은 각각 적절한 특징값을 추출하도록 학습된다.
CNN의 필터(Filter)
실제로 각 필터는 특정한 특징을 인식하기 위한 목적으로 사용된다.
각 필터는 특징이 반영된 특징 맵을 생성한다.
얕은 층에서는 local feature, 깊은 층에서는 고차원적인 global featuure를 인식하는 경향이 있다.
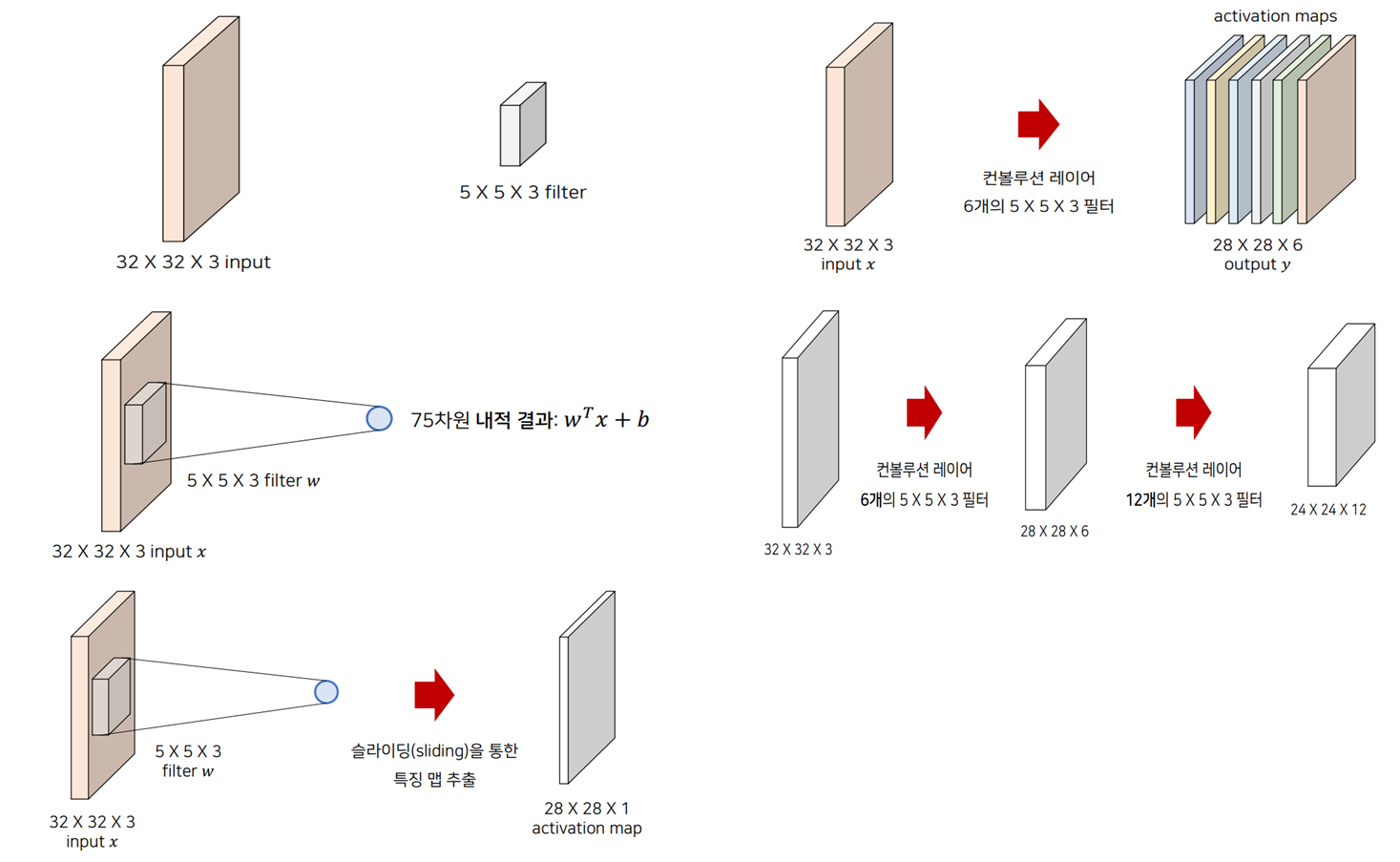
- 하나의 입력 이미지와 하나의 필터
- 입력 이미지의 로컬 영역과 필터(filter) 사이에서 내적(dot product)을 계산해 각 위치의 결과를 구한다. (내적결과 : W^T x + b)
- 각 위치에서의 콘볼루션 연산 결과를 모아서 특징 맵을 생성한다.
- 6개의 개별적인 필터를 가진 Convolution Layer를 이용
- 실제 CNN layer는 여러 번 중첩되어 사용될 수 있다.
VGG Network(ICLR2015)
VGG 네트워크는 작은 크기의 3x3 컨볼루션 필터(filter)를 이용해 레이어의 깊이를 늘려 우수한 성능을 보임
ResNet(CVPR 2016)
깊은 네트워크를 학습 시키기 위한 방법으로 잔여학습(residual learning)을 제안
잔여블록(residual block)을 이용해 네트워크의 최적화(optimization) 난이도를 낮춤.
-> 실제로 내재한 mapping인 H(x)를 곧바로 학습하는 것은 어려우므로 대신 F(x) = H(x) -x를 학습한다
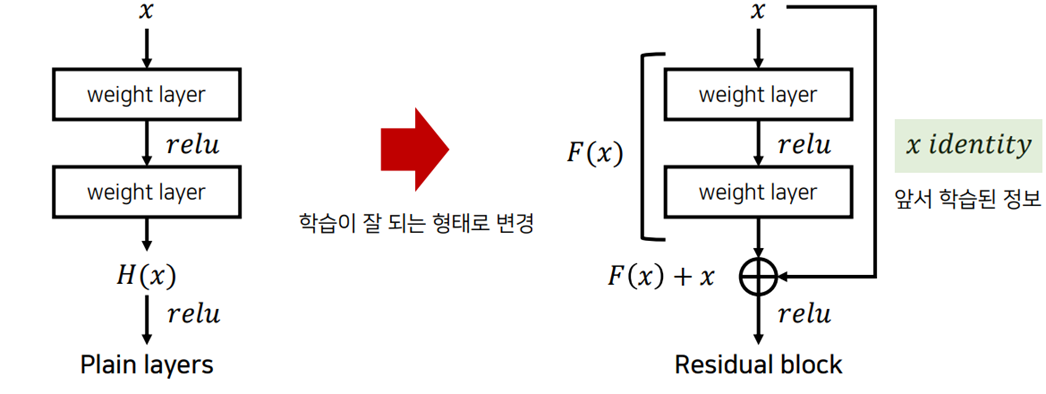
잔여블록(residual block)을 이요해 네트워크의 최적화(optimization)난이도를 낮춘다.
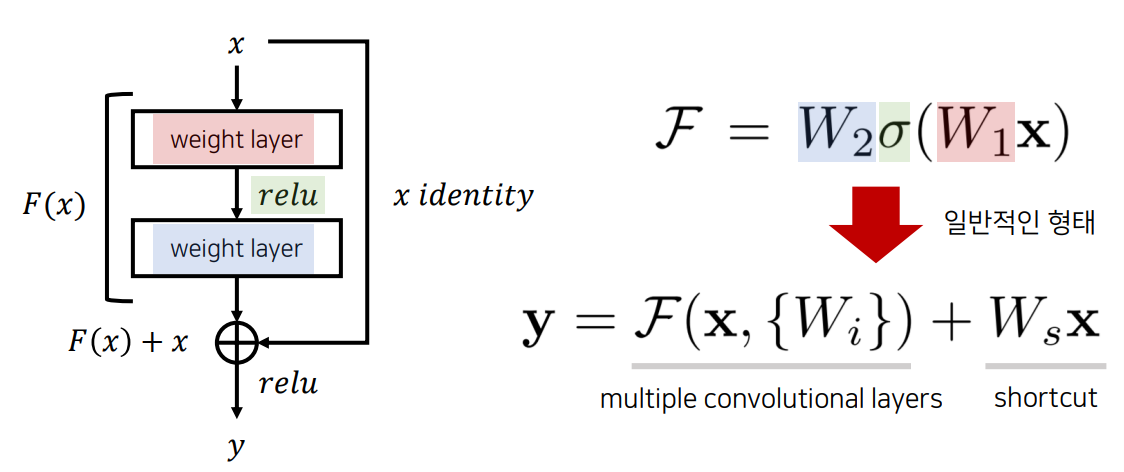
레이어가 깊어질수록 성능이 향상된다.(단, 레이어가 과도하게 깊으면 오히려 감소)
다양한 아키텍처
State-of-the-art 동향: https://paperswithcode.com/sota/image-classification-on-imagenet
Transfer Learning을 활용한 마동석 분류기 만들기
이미지 크롤링 + Transfer Learning + Web API 실습
[참고] : (프로그래머스) 딥러닝 기초 - 나동빈
