활성함수
선형 연산 결과인 활성값에 비선형 함수를 적용하는 과정
z = W^Tx + b
y = T(z)
활성함수 변천사
sigmoid 함수는 활성값이 커지면 포화상태가 되고 경사도가 0에 가까운 값을 출력함
-> 매개변수 갱신(학습)이 매우 느린 요인
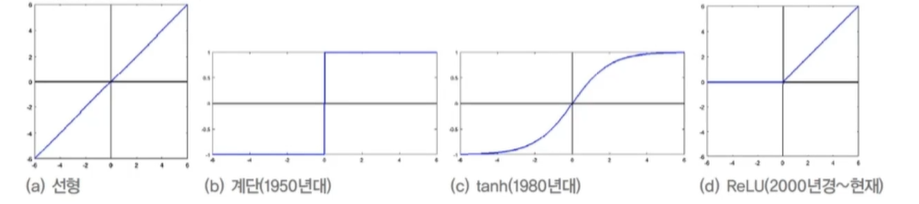
ReLU(Rectified Linear Unit) 활성함수
경사도 포화(gradient saturation)문제 해소
y = ReLU(z) = max(0, z)
변형
Leaky ReLU 보통 알파 = 0.01을 사용
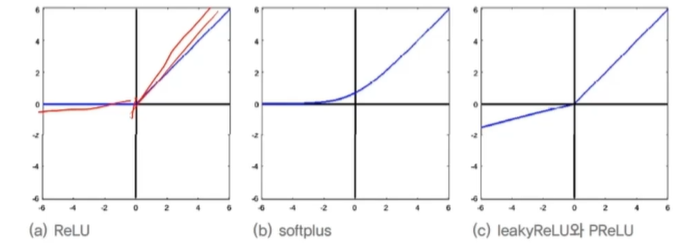
활성함수의 문제 해결
- 포화된 영역이 경사도가 작아짐
- 출력값이 영 중심이 아님
- 다소 높은 연산량(Exp()함수)
배치 정규화(데이터 전처리)
규모의 문제 해결
양 극단의 문제를 해결해야 학습을 용이 해지므로
공변량 변화(covariate shift) 현상
테스트의 양의 문제뿐 아니라 질의 문제도 중요
훈련집합과 테스트 집합의 분포가 다름
내부 공변량 변화
1. 학습이 진행되면서 첫번째 층의 매개변수가 바뀜에 따라 분포가 바뀜
-> 두번째 층 입장에서 보면 자신에게 입력되는 데이터의 분포가 수시로 바뀌는 셈
2. 층이 깊어짐에 따라 더욱 심각 -> 학습을 방해하는 요인으로 작용
특징
공변량 시프트 현상을 누그러뜨리기 위해 정규화를 층 단위 적용하는 기법
정규화를 적용하는 곳이 중요
-> 연산과정 중 식을 어디에 적용할지(적용위치)
입력 x 또는 중간결과 z중 어느 것에 적용? z에 적용하는 것이 유리
선형연산을 하고 나서 적용하는 것이 좋다.
일반적으로 완전연결층, 합성곱층 후 혹은 비 선형 함수 전 적용
훈련 집합 전체 또는 미니배치 중 어느 것에 적용?(적용단위)
-> 미니배치에 적용하는 것이 유리
과정
- 미니배치 단위로 평균과 분산 계산
- 구한 평균과 분산을 통해 정규화
- 비례와 이동 세부 조정
배치 정규화 장점
- 신경망의 경사도 흐름 개선
- 높은 학습률 허용
- 초기화에 대한 의존성 감소
- 의도하지 않았지만 규제와 유사한 행동을 하며, 드롭아웃의 필요성을 감소시킴
변환을 수행하는 코드
미니배치 단위로 노드마다 독립저그올 코드를 수행
감마와 베타는 노드마다 고유한 매개변수로서 학습으로 알아냄
후처리 작업
각 노드는 전체 훈련집함을 가지고 독립적으로 모든 값에 대한 평균과 분산을 구하는 코드를 수행
예측
전체 평균에 대한 분산 -> 정규분포
CNN은 노드단위가 아니라 특집 맵 단위로 적용
노드 == 특징맵
배치 정규화의 긍정적 효과를 측정한 실험 사례
- 가중치 초기화에 덜 민감
- 학습률을 크게 하여 수렵 속도 향상 가능
- sigmoid 활성함수로 사용하는 깊은 신경망도 학습이 이루어짐
- 규제 효과를 제공하여 드롭아웃을 적용하지 않아도 높은 성능
규제의 필요성과 원리
과잉적합에 빠지는 이유와 과잉적합을 피하는 전략
학습 모델의 용량에 따른 일반화 능력
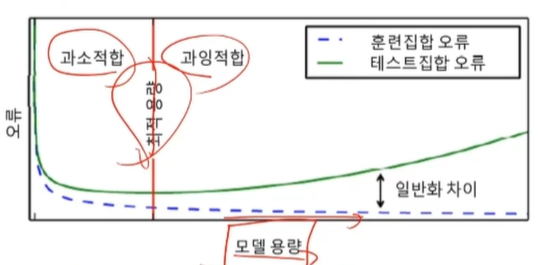
대부분 가지고 있는 데이터에 비해 훨씬 큰 용량의 모델을 사용
훈련집합을 단순히 '암기'하는 과잉적합에 주의를 기울여야함
현대 기계학습의 전략
충분히 큰 용량의 모델을 설계한 다음, 학습과정에서 여러 규제 기법을 적용
규제의 정의
규제는 오래 전부터 수학과 통계학에서 연구해온 주제
-
모델 용량에 비해 데이터가 부족한 경우의 부족조건문제를 푸는 접근법
-
적절한 가정을 투입하여 문제를 품 -> '입력과 출력 사이으이 변환은 매끄럽다' 는 사전 지식
유사한 데이터는 가깝게 매핑된다. -
대표적인 티호노프의 규제(Tikhonov's regularization) 기법는 매끄러움 가정에 기반을 둔 식을 사용
통계에서는 릿지 회귀(ridge regression), 기계학습에서는 가중치 감쇄(weight decay)등이 대표적임
현대 기계학습도 매끄러움 가정을 널리 사용함
- 가중치 감쇠 기법
-> 모델의 구조적 용량을 충분히 크게 하고, 수치적 용량을 제한하는 규제 기법 - 비지도 학습
일반화 오류를 줄이려는 의도를 가지고 학습 알고리즘을 수정
규제 기법
명시적 규제와 암시적 규제
명시적 규제 : 가중치 감쇠나 드롭아웃처럼 목적함수나 신경망 구조를 직접 수정하는 방식
암시적 규제 : 조기 멈춤, 데이터 증대, 잡음 추가, 앙상블처럼 간적적으로 영향을 미치는 방식
가중치 벌칙
규제항은 훈련집합과 무관하며, 데이터 생성 과정에 내재한 사전 지식에 해당
규제항은 매개변수를 작은 값으로 유지하므로 모델의 용량을 제한하는 역할
(수치적 용량을 제한함)
규제항 R(Θ)로 무엇을 사용할 것인가
-> 큰 가중치에 벌칙을 가해 작은 가중치를 유지하려고 주로 L2놈이나 L1놈을 사용
L2 놈(norm)
규제 항 R로 L2놈을 사용한느 규제 기법을 '가중치 감쇠'라 부름
: 루트에 제곱
가중치 감쇠는 단지 세타에 (1-2p감마)를 곱해주는 셈
최종해를 원점 가까이 당기는 효과(즉, 가중치를 작게 유지함)
== 가중치 감쇠 효과
최소 패널티와 최소값으로 가는 길의 중간 점을 찾는 것이 중요
선형 회귀에 적용
곱셈과 덧셈을 이용해 y를 만드는 것
공분산 행렬의 대각 요소가 2람다만큼씩 증가
-> 역행렬을 곱하므로 가중치를 축소하여 원점으로 당기는 효과
MLP와 DMLP에 적용
원래 가중치 -> 미분하여 갱신
규제 j = 원본 + 람다 규제항 -> 크기가 줄어듬
갱신할 때 크기가 점점 줄어듬 (원래 도달항을 하면 오버피팅이 되므로 규제항을 이용하여 범위를 적용)
L1놈
: 크기에 절대값
세타 값으로 미분(세타가 양이면 람다, 음이면 -람다)
sign으로 사용
원래에 갱신하는 가중치 - 규제가 적용된 가중치(미분한 값)
== 손실함수 - 람다sign(세타)
L1놈의 희소성(sparsity)효과(0이 되는 매개변수가 많음)
: 선형 회귀에 적용하면 특징 선택 효과
최소 패널티는 모서리 쪽으로 생길 확률이 크다
L2놈은 전체적인 크기를 다 줄임
L1놈은 하나에만 하고 나머지는 0으로
특정되어있는 것을 찾거나 의미를 찾을 때 사용
규제
- 목적함수 : 적용된 충분한 학습 모델로 훈련집합의 예측한 오차
- 규제 : 학습 모델이 훈련집합의 예측을 너무 잘 수행하지 못하도록 방지
- 람다는 선호도 정도, 클 수록 w값이 줄어듬
효과
- 가중치에 대한 선호도 표현
- 학습 모델을 단순화시킴으로 일반화 성능 향상 시킴
- 매끄럽게 하여 최적화 개선
엘라스틱 넷 = L1 + L2
조기 멈춤
학습 시간에 따른 일반화 능력
일정시간이 자나면 과잉적합 현상이 나타남 -> 일반화 능력 저하
훈련 데이터를 단순히 암기하기 시작
조기멈춤(early stopping)
검증집합의 오류가 최저인 점에서 학습을 멈춤
순진한 버전을 적용하면 t1에서 멈추므로 설익은 수렴
이에 대처하는 여러가지 방안 중에서 참을성을 반양한 버전
-> 참을성 : 연속적으로 성능 향상이 없으면 멈추는 정도
데이터 확대
과잉적합 방지하는 가장 확실한 방법은 큰 훈련집합을 사용
하지만 데이터 수집은 비용이 많이 드는 작업
데이터 확대라는 규제기법
데이터를 인위적으로 변형하여 확대함
자연계에서 벌어지는 잠재적인 변형을 프로그램으로 흉내내는 방법
MINIST에 아핀 변환
한계
1. 수작업 변형
2. 모든 부류가 같은 변형을 사용
모핑을 이용한 변형
비선형 변환으로서 아핀 변환에 비해 훨씬 다양한 형태의 확대
학습기반 : 데이터에 맞는 '비선형 변환 규칙을 학습'하는 셈
자연영상 확대
좌우반전, 생상변환
잡은 섞기
입력데이터에 잡음 섞는 기법
은닉 노드에 잡음을 섞는 기법(고급 특징수준에서 데이터를 확대하는 셈)
드롭아웃
드롭아웃 규제 기법
완전 연결층의 노드 중 일정 비율을 임의 선택하여 제거 -> 남은 부분 신경망 학습
많은 부분 신경망을 만들고, 앙상물 결합하는 기법으로 볼 수 있음
전방 계산
참거짓(boolean)배열 파이로 노트 제거 여부 표시
파이는(미니배치) 샘플마다 독립적으로 정하는데, 난수로 설정함
일반적으로 입력층 제거 비율 P input = 0.2, 은닉층 제거 비율 Phidden =0.5로 설정
예측단계
앙상블 효과 모방
학습과정에서 가중치가 (1-드롭아웃 비율)만큼만 참여했기 때문에 P만큼 보정
메모리와 계산 효율
추가 메모리는 참거짓 배열 파이, 추가 계산은 작음
실제 부다음은 신경망의 크기에 옴 : 보통 은닉 노드 수를 1/Phidden만큼 늘림
앙상블 기법
앙상블(ensemble)
서로 다른 여러 개의 모델을 결합하여 일반화 오류를 줄이는 기법
현대 기계학습은 앙상블도 규제로 여김
두 가지 일
-
서로다른 예측기를 학습하는 일
서로다른 구조의 신경망 여러 개 학습 또는 같은 구조를 사용하지만 서로 다른 초기값과 하이퍼 매개변수를 설정하고 학습
예, 배깅(bagging): 훈련집합을 여러 번 샘플링하여 서로 다른 훈련집합을 구성
예, 부스팅(boosting) : i 번째 예측기가 틀린 샘플을 i + 1번째 예측기가 잘 인식하도록 연계성을 고려 -
학습된 예측기를 결합하는 일 -> 모델 평균 (model averaging)
여러 모델의 출력에서 평균을 구하거나 투표하여 최종결과 결정
하이퍼 매개변수(parameter) 최적화
학습 모델에는 두 종류의 매개변수가 있다
- 내부 매개변수 혹은 가중치
신경망의 경우, 가중치 Θ로 표기
학습 알고리즘이 최적화함
-> 주어진 데이터로부터 결정됨 - 하이퍼 매개변수
모델의 외부에서 모델의 동작을 조정함
-> 사람에 의해서 결정됨
예, 은닉층의 개수, CNN의 필터 크기와 보폭, 학습률 등
하이퍼 매개변수 선택
- 표준 참고 문헌이 제시하는 기본값을 사용하면 됨
보통 여러 후보 값 또는 범위를 제시 - 후보 값 중에서 주어진 데이터에 최적인 값 선택 <- 하이퍼 매개변수 최적화
- 하이퍼 매개변수 조합 H를 생성
-> 구현하는 방법에 따라 수동 탐색, 격자 탐색, 임의 탐색
==> 최근 학습을 통한 자동 탐색 방법들이 연구됨(예, 자동화된 기계학습)
격자 탐색(grid search)과 임의 탐색(random search)
임의 탐색은 난수로 하이퍼 매개변수 조합을 생성함
로그 공간(log space)간격으로 탐색
어떤 하이퍼 매개변수는 로그공간을 사용해야함
예, 학습률 범위가 [0.0001~0.1]일 때
등 간경은 0.0001, 0.0002 ~ 0.0999로 총 1000개 값을 조사
로그 공간 간격은 2배씩 증가시킴
즉 0.0001, 0.0002, 0.0004,...,0.000512 를 조사
차원의 저주 문제 발생
매개변수가 m개이고 각각이 q개 구간이라면 qm 개의 점을 조사해야 함
임의 탐색이 우월함
크게 했다가 점차 세밀해지는 coarse-fine 탐색
2차 미분을 이용한 방법
손실함수가 정해졌을 때 각각 차원 축으로 미분값을 구하고 공간에 J값이 생긴다. J에 맞춰 값을 이동시킴
1차 미분을 사용하는 경사 하강법
-
현재 기계학습의 주류 알고리즘
-
두가지 개선책
- 경사도의 잡음을 줄임(미니배치 등)
- 2차비문 정보를 활용
경사 하강법을 더 빠르게?
1차 미분 정보로는 빠른 경로를 알 수 없음
1차 미분은 현재 위치에서 지역적인 기울기 정보만 알려주기 때문
-> 뉴턴 방법은 2차 미본 정보를 활용하여 빠른 경로를 알아냄
1차 미분 최적화와 2차 미분 최적화 비교
1차 미분 최적화
- 경사도 사용하여 선형 근사 사용
- 근사치 최소화
2차 미분 최적화
- 경사도와 헤시안을 사용하여 2차 근사 사용
- 근사치의 최소값
뉴턴 방법
테일러 급수: 주어진 함수를 정의역에서 특정 점의 미분계수들을 계수로 가지는 다항식의 극한(멱급수)으로 표현함
-> 미분 값을 이용하여 조합을 만듬
0차 미분 + 1차미분 + 2차 미분
델타인 미소한 양으로 미분
근사한 것이 0이면 2차의 미분 값의 최솟값
델타값 -> 2차미분에 역수 x 1차미분
뉴턴 방법의 적용
2차 함수에 뉴턴 방법을 적용했으므로, 3차 항 이상을 무시한 식을 사용했음에도 최적 경우 제시
기계학습이 사용하는 목적함수는 2차 함수보다 복잡한 함수이므로 한 번 에 최적해 도달 불가능
-> 반복하는 뉴턴 방법을 사용해야함
헤시언 H 를 구해야함
-> 매개변수ㄹ의 개수를 m이라 할 때 O(m^3)이라는 과다한 연산량 필요
-> 켤레 경사도 방법이 대안 제시
켤레 경사도 방법
직선 탐색(line search)
이동 크기를 결정하기 위해 직선으로 탐색하고 , 미분
- 방법
경사하강법은 근본적으로 이전 경사 하강법과 같음
-> 현재 직선 탐색을 할 때 이전 정보를 전혀 고려하지 않음
켤레 경사도는 직전 정보를 사용하여 해에 빨리 접근
유사 뉴턴 방법
유사 뉴턴 방법(quasi-Newton methods)
- 문제점
경사하강법 : 수렴 효율성 낮음
뉴턴방법 : 헤시안 연산 부담 -> 헤시언 H의 역행렬을 근사하는 행렬 M을 사용 - 대표적으로 점진적으로 헤시안을 근사화하는 LFGS가 많이 사용됨
- 기계학습에서는 M을 저장하는 메모리를 적게 쓰는 limited memory L-BFGS를 주로 사용함
전체 배치를 통한 갱신을 할 수 있다면, L-BFGS사용을 고려함
참고 : 기계학습 (오일석)
{kind=link}
