인공지능이란?
사전적 의미
인간의 학습 능력과 추론능력, 지각능력, 자연언어의 이해능력 등을 컴퓨터프로그램으로 실현한 기술
- 인간처럼 생각하고 행동하는 기기의 탄생!
- 학습
일상 속 인공지능
- 음성인식(siri)
- 추천시스템 (eBay, Netflix)
- 자율주행 (Waymo)
- 실시간 개체 인식 (Face ID)
- 로봇 (HUBO)
- 번역 (papago)
인!공!지!능
- AI <-> SW <-> 협업 <-> 소통
- python와 Open Source로 많이 소통이 필요
인공지능은 레고처럼 조립하여 구현이 가능하다.
- 깊은 신경망
- 주어진 문제 목표
- 최적화
인공지능 구현의 뼈대역할 (frameworks)
- 다양한 것이 있다.

기술에 집중하기 보다 인간 중심의 소통
인공지능 == 도구
-> 도구를 반드는 방법을 배우는 것도 중요하지만, 도우 사용방법도 배워야한다.
-> 같은 도구도 어떻게 사용하느냐에 따라 다름
기계학습이란
기계학습 정의
-
인공지능(artificial intelligence) 이란?
인간의 학습, 추론, 지각, 자연언어 이해 등의 지능적 능력을 기기로 실현한 기술 -
학습이란? <표준국어대사전>
경험의 결과로 나나타는, 비교적 지속적인 행동의 변화나 그 잠재력의 변화, 또는 지식을 습득하는 과정 -
기계학습이란?
인공지능 초창기 정의
Computers to learn for experience
현대적 정의
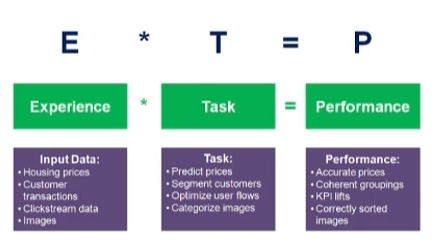
최적의 프로그램(알고리즘)을 찾는 행위
경험 E 를 통해
주어진 작업 T 에 대한
성능 P 의 향상
- 기계학습과 전통적인 프로그래밍의 비교
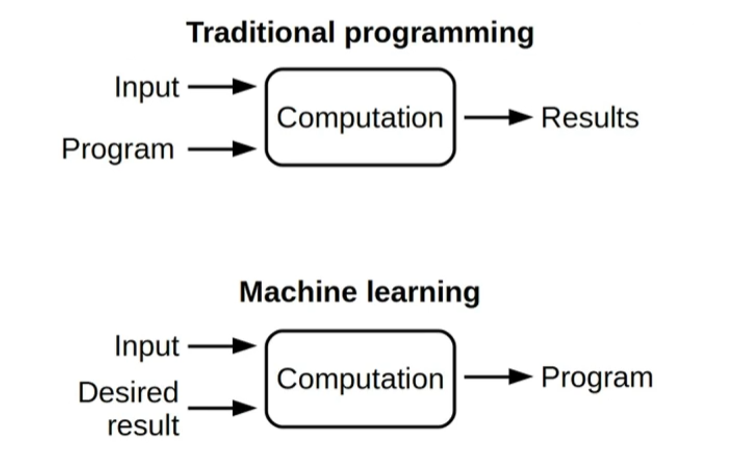
입력과 원하는 결과를 주고 원하는 규칙을 찾으라
지식기반 방식에서 기계학습으로의 대전환
- 인공지능의 탄생 == 연산 장치의 탄생
컴퓨터의 뛰어난 능력
-> 복잡한 연산을 사람보다 잘함
컴퓨터에 대한 기대감 == 컴퓨터의 능력 과신
-> 사람의 지능 행위를 컴퓨터가 모방할 수 있을까 하는 호기심
-> 1940년대 인공지능 개념 정의 및 분야 대두
-
초창기 지식기반 방식 주류
지식기반 : 경험적인 지식 혹은 사실을 인위적으로 컴퓨터에 부여하는 학습 -
큰 깨달음
지식기반의 한계
: 학습의 대상이 심한 변화 양상을 가진 경우, 모든 지식 혹은 사실의 나열은 불가능 -
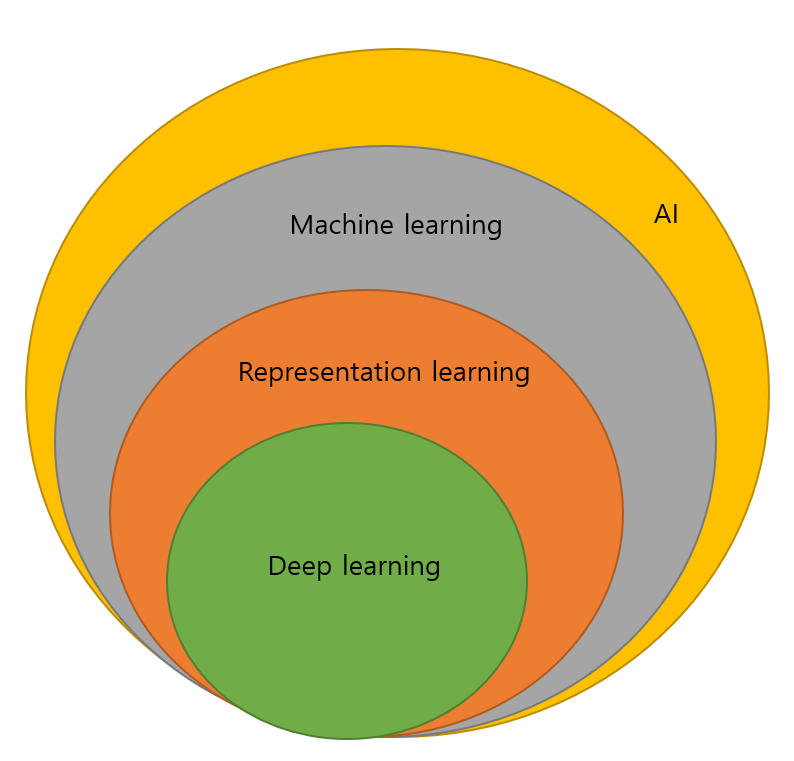
인공지능의 주도권 전환
지식기반 -> 기계학습 -> 심층학습(deep learning, 표현학습 representation learning)
데이터 중심 접근 방식으로 전환
기계학습 개념
-
간단한 기계학습 예제
모든 데이터는 정량화된 형태로 표현(예, 벡터) -
문제(task) : 예측(prediction)
임의의 시간이 주어지면 이때 이동체의 위치는?
예측은 회귀(regression) 문제와 분류(classification) 문제로 나뉨
-> 회귀는 목표치가 실수, 분류는 부류 혹은 종류의 값 -
훈련집합 (training set)
가족축은 특징, 세로축은 목표치
과측한 4개의 점이 훈력집합 을 구성함
-
관찰된 데이터들을 어떻게 설명할 것인가?
가설. 눈대중으로 데이터 양상이 직선 형태를 보임 -> 모델을 직선으로 선택가성
가설인 직선 모델의 수식
-> 2개의 매개변수 parameter
-> y = ax + b -
기계학습의 훈련(train)
주어진 문제인 예측을 가장 적확하게 할 수 있는 최적의 매개변수를 찾는 작업
처음은 임의의 매개변수 값에서 시작하지만, 개선하여 최적 성능(performance)에 도달
-
훈련을 마치면, 추론(inference)을 수행
새로운 특징에 대응되는 목표치의 예측에 사용 -
기계학습의 궁극적인 목표
훈련직합에 없는 새로운 데이터에 대한 오류를 최소화(새로운 데이터 = 테스트 집합)
테스트 집합에 대한 높은 성능을 일반화(generalization)능력이라함 -
기계학습 필수요소
- 학습할 수 있는 데이터가 있어야함
- 데이터 규칙 존재
- 수학적으로 설명 불가능
특징 공간에 대한 이해
1차원과 2차원 특징 공간
-
모든 데이터 정략적으료 표현되며, 특징공간 상에 존재
-
1차원 특징 공간
-
2차원 특징공간
-> 특징 벡터 표기(x = x1,x2)^T
-> x = (몸무게, 키)^T, y = 장타율 , x = (체온, 두통)^T, y = 감기여부
다차원 특징 공간
-> 차원에서 여러가지 규칙이 있을 것이고 그 규칙을 찾는 것이 목표이다.
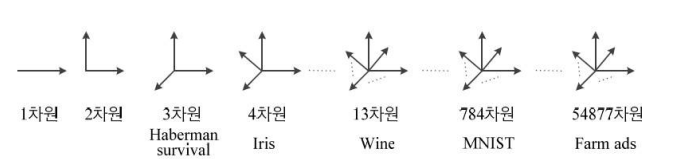
- d-차원 데이터
특징 벡터 표기 : x = (x1,x2,x3...,xd)^T
d-차원 데이터를 위한 학습모델
-> 직선 모델을 사용하는 경우 매개변수 수 = d+1
-> y = w1x1 + w2x2 + ... + wdxd +b
-> 2차 곡선 모델을 사용하면 매개변수 수가 지수적으로 증가, 매개변수 수 = d2+d+1
특징공간 변환과 표현학습
-
차원의 저주(curse of dimensionality = number of features)
차원이 높아짐에 따라 발생하는 현실적이 문제들
차원이 높아질수록 유의미한 표현을 찾기 위해 지수적으로 많은 데이터가 필요함 -
선형 분리 불가능한 원래 특징공간
직선 모델을 적용하면 75% 정확도 한계
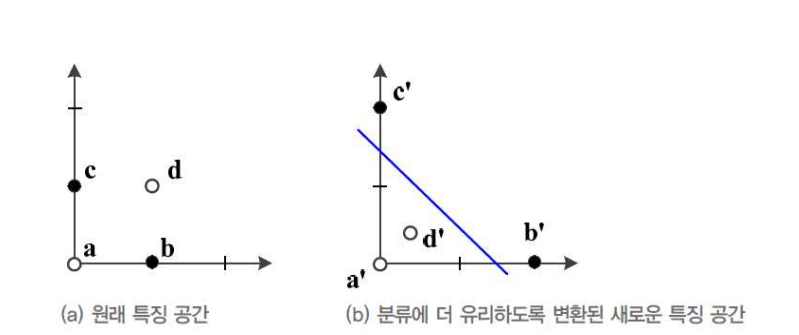
공간 변환을 통해 직선모델로 100% 정확도 -
표현문제(representations matter)
원통 좌표로 만들어진 문제를 직선으로 변환하면 풀리는 문제들이 있음 -
표현학습(representation learning)
좋은 특징 공간을 자동으로 찾는 작업 -
심층학습(deep learning)
표현학습의 하나로 다수의 은닉층을 가진 신경망을 이용하여 최적의 계층적인 특징을 학습
기계 학습의 과거와 현재, 미래
인공지능과 기계학습의 간략한 역사
- Ada Lovelace 여사의 통착력
- 200년이 지난 지금,
-> 인간 수준의 사진 인식 능력
-> 알파고는 바둑으로 사람의 능력을 압도
-> 구슬사의 듀플렉스는 인간과 대화 - 인공신경망의 역사
-> 1940-1960 : 인공두뇌학
-> 1980-1990 : 결합설
-> 2006-현재 : 심층학습
기술 추세
- 기계학습 알고리즘과 응용의 다양화
- 표현 학습이 중요해짐
- 심층 학습이 기계학습의 주류
- 심층학습은 현대 인공지능 실현에 핵심기술
데이터에 대한 이해
-
과학 기술의 정립과정
데이터 수집 -> 모델 정립 -> 예측 -> 데이터 수집 -
기계학습
기계학습은 복잡 문제/과업을 다룸
-> 지을적 범주의 행위들은 규칙의 다양한 변화 양상을 가짐
단순한 수학 공식으로 표현 불가능함
데이터를 설명할 수 있는 학습모델을 찾아내는 과정
데이터 생성 과정
-
데이터 생성 과정을 완전히 아는 인위적 상황의 예제
예) 두개 주사위를 던져 나온 눈의 합을 x라 할 때 , y = (x-7)^2+1점을 받는 게임
이런 상황을 '데이터 생성과정을 완전히 알고 있다'고 말함
-> x를 알면 정확히 y을 예측할 수 있음
-> x의 발생 확률 p(x)를 정확하게 알 수 있음
-> P(x)를 알고 있으므로, 새로운 데이터 생성가능 -
실제 기계학습 문제
- 데이터 생성 과정을 알 수 없음
- 단지 주어진 훈련집합 X,Y로 가설 모델을 통해 근사 추정만 가능
데이터의 중요성
- 데이터의 양과 질
- 주어진 과업에 적합한 다양한 데이터를 충분한 양만큼 수집 -> 과업 성능향상
-> 주어진 과업에 관련된 데이터 확보는 아주 중요함 - 데이터의 양과 학습모델의 성능 경향성 비교
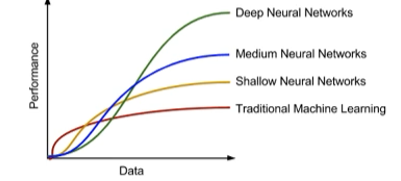
- 공개 데이터
- 기계 학습의 대표적인 3가지 데이터 : Iris, MNIST, ImageNet
- UCI 저장소
데이터베이스 크기와 기계학습 성능
- 데이터의 적은 양 -> 차원의 저주와 관련
- 적은 양의 데이터베이스로 어떻게 높은 성능을 달성하는가?
- 방대한 공간에서 실제 데이터가 발생하는 곳은 매우 작은 부분 공간임
-> 데이터 희소 특성 가짐 - 매니폴드(마니+끼다) 가정
-> 고차원 데이터는 관련된 낮은 차원의 매니폴드에 가깝게 집중되어있음
데이터 가시화
- 4차원 이상의 초공간은 한꺼번에 가시화 불거능
- 여러가지 가시화 기법
-> 2개씩 조합하여 여러개의 그래프 그림
간단한 기계학습의 예
-
선형 회귀 문제
: 직선모델(가설)을 사용하므로 두 개의 매개변수 오메가 = (w,b)^T -
목적함수 (또는 비용함수)
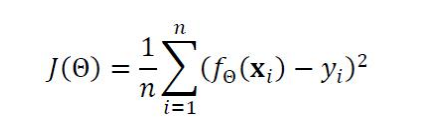
- 위 식은 선형 회귀를 위한 목적함수
-> 평균제곱오차 라고 부른다.
-> f(x) 예측 함수의 예측출력,y 예측함수가 맞추어야 하는 실제 목표치
-> f(x) - y 오차 혹은 손실 - 처음에는 최적 매개변수 값을 알 수 없으므로 임의의 난수로 오메가 = (w,b)^T 설정
-
기계학습이 하는 일을 공식화하면,
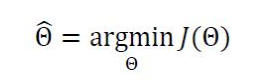
파라미터 값을 최적화 하는 것이다.
-> 기계학습은 작은 개선을 반복하여 최적의 해를 찾아가는 수치적 방법이다. -
좀 더 현실적인 상황
- 지금까지는 데이터가 선형을 이루는 아주 단순한 상황을 고려함
- 실제 세계는 선형이 아니며 잡음이 섞임 -> 비선형 모델이 필요
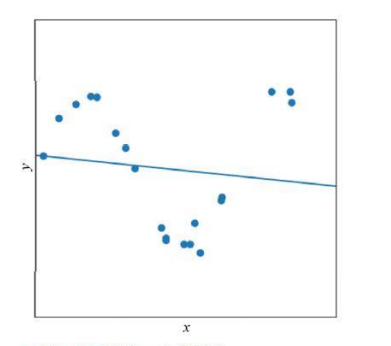
모델 선택
과소적합과 과잉적합
-
과소 적합 (underfitting)
-> 모델의 '용량이 작아' 오차가 클 수 밖에 없는 현상 -
대안 : 비선형 모델을 사용
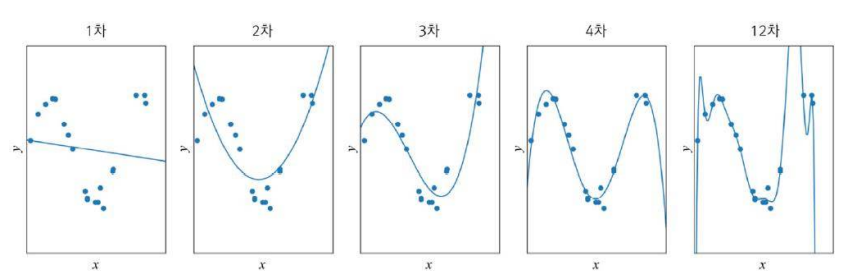
-
과잉 적합 (overfitting)
-> 12차 다항식 곡선을 채택한다면 훈련집에 대해 거의 완벽하게 근사화함
-> 하지만 '새로운'데이터를 예측한다면 큰 문제 발생
-> '모델의 용량'이 크기 때문에 학습과정에서 잡음까지 수용 -> 과잉적합현상
-> 훈련집합에 과몰입해서 단순 암기 했기 때문임
-> 적절한 용량의 모델을 선택하는 모델 선택 작업이 필요 -
1차 ~ 12차 다항식 모델의 비교 관찰
- 1~2차는 훈련집합과 테스트집합 모두 낮은 성능 : 과소적합
- 12차는 훈련집합에 높은 성능을 보이나 테스트집합에서는 낮은 성능 -> 낮은 일반화 능력 : 과잉적합
- 3~4차는 훈련집합에 대해 12차보다 낮겠지만 테스트집합에는 높은 성능 -> 높은 일반화 능력 : 적합 모델 선택
- 모델의 일반화 능력과 용량 관계
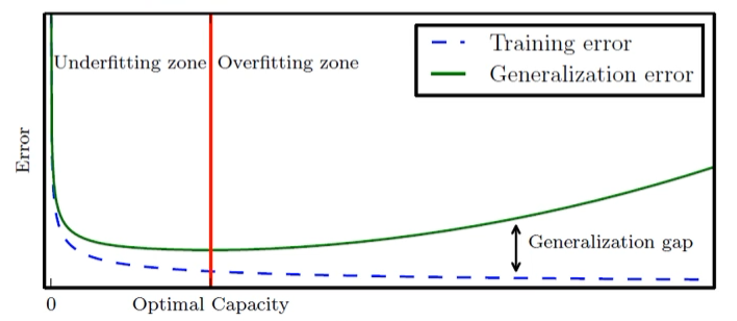
편향(bias)와 분산(변동, variance)
-
훈련집합을 여러 번 수집하여 1~12차에 반복 적용하는 실험
-> 2차는 매번 큰 오차 -> 편향이 큼. 하지만 비슷한 모델을 얻음 -> 낮은 변동
-> 12차는 매번 작은 오차 -> 편향이 작음. 하지만 크게 다은 모델을 얻음 -> 높은 변동
-> 일반적으로 용량이 작은 모델은 편향이 크고 분산이 작음
-> 복잡한 모델은 편향이 작고 분산이 큼
-> 편향과 분산은 상충관계(trade-off) -
기계학습 목표
-> 낮은 편향과 낮은 분산을 가진 예측 모델을 만드는 것이 목표
-> 하지만 모델의 편향과 분산은 상충 관계
-> 편향을 최소로 유지하며 분산도 최대로 낮추는 전략 필요
-
편향과 분산의 관계
-> 용량 증가 -> 편향감소, 분산 증가 경향
-> 일반화 오차 성능 (=편향+분산)은 U형의 곡선을 가짐
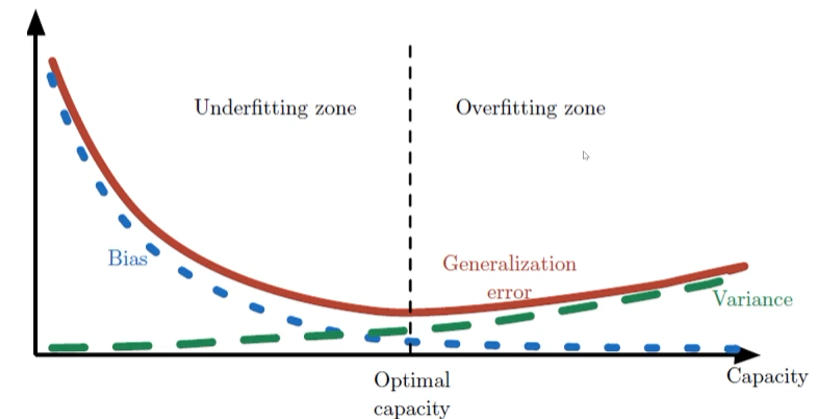
-
검증 집합을 이용한 모델 선택
-> 훈련 집합과 테스트집합과 다른 별도의 검증집합(calidation set)을 가진 상황(데이터양 많음)
- 교차 검증(cross validation)
-> 비용 문제로 별도의 검증집합이 없는 상황에 유용한 모델 선택 기법(데이터 양 적음)
-> 훈련집합을 등분하여, 학습과 평가 과정을 여러 번 반복한 후 평균 사용
- 부트스트랩(boot strap)
-> 임의의 복원추출 샘플링 반복
-> 데이터 분포가 불균형일 때 적용
모델 선택의 한계와 현실적인 해결책
-
모델 집합에서 선택
-> 현실에서는 학습모델들이 아주 다양함
-신경망
-신경망도 mlp, deep mlp, cnn, rnn 등 아주 많음
-support vector machine(svm)
-decision trees -
현실에서는 경험으로 큰 틀(가설) 선택한 후
-> 모델 선택 알고리즘으로 세부 모델 선택 -
현대 기계 학습의 전략
-> 용량이 충분히 큰 모델을 선택 한 후, 선택한 모델이 정상을 벗어나지 않도록 여러 규제 기법을 적용함
규제
데이터 확대
-
데이터를 더 많이 수집하면 일반화 능력 향상됨
-
데이터 수집은 많은 비용이 듦
-> 실측자료(ground truth)를 사람이 일일이 표식(labelling)을 해야함 -
인위적으로 데이터 확대(data augmentation)
-> 훈련집합에 있는 샘플을 변형(transform)함
-> 약간 회전 또는 왜곡

가중치 감쇠
- 가중치를 작게 조절하는 기법
-> 12차 곡선은 가중치가 매우 큼
-> 가중치 감쇠는 개선된 목적함수를 이용하여 가중치를 작게 조절하는 규제기법
-> 두번째 항은 규제항으로서 가중치 크기를 작게 유지해줌

기계학습 유형
지도 방식에 따른 유형
-
지도학습(supervised learning)
-> 특징 벡터 X와 목푯값 Y가 모두 주어진 상황
-> 회귀와 분류 문제로 구분 -
비지도 학습(unsupervised learning)
-> 특징 벡터 X는 주어지는데 목푯값 Y가 주어지지 않는 상황
-> 군집화 과업 (고객 성향에 따른 맞춤 홍보 응용 등)
-> 밀도 추정, 특징 공간 변환 과업 -
강화 학습(reinforcement learning)
-> (상대적)목표치가 주어지는데, 지도 학습과 다르나 형태임(보상 reward) -
준지도 학습 (semi-supervised learning)
-> 일부는 X와Y를 모두 가지지만, 나머지는 X만 가진 상황
-> 최근, 대부분의 데이터가 X의 수집은 쉽지만, Y는 수작업이 필요하여 최근 중요성을 부각
다양한 기준에 따른 유형
-
오프라인 학습과 온라인 학습
-> 보통은 오프라인 학습을 다룸
-> 온라인 학습은 IoT 등에서 추가로 발생하는 데이터 샘플을 가지고 점증적 학습 수행 -
결정론적 학습(deterministic)과 확률적 학습(stochastic)
-> 결적론적에서는 같은 데이터를 가지고 다시 학습하면 같은 예측 모델이 만들어짐
-> 확률적 학습은 학습 과정에서 확률 분포를 사용하므로 같은 데이터로 다시 학습하면 다른 예측 모델이 만들어짐 -
분별 모델(discriminative)과 생성 모델(generative)
-> 분별 모델은 부류 예측에만 관심. 즉 P(y|x)의 추적에 관심
-> 생성 모델은 P(x) 또는 P(x|y)를 추정함
-따라서 새로운 샘플을 '생성'할 수 있음
참고) 기계학습 (오일석)
{kind=link}
