넷플릭스 프라이즈
기념비적인 추천 엔진 경진 대회
넷플릭스 프라이즈(Netflix Prize) 개요
2006년부터 3년간 운영된 넷플릭스의 기념비적인 추천 엔진 경진대회
넷플릭스 추천 시스템 품질을 10% 개선하는 팀에게 $1M 수여 약속
RMSE(Root Mean Square Error)가 평가 기준으로 사용됨
네플릭스 브랜드 인지도도 올라감
프라이버시 이슈도 제기됨
이를 기폭제로 캐글과 같은 머신러닝 경진대회 플랫폼이 등장
이 대회를 통해 협업 필터링이 한 단계 발전함
SVD를 활용한 SVD++는 이후 굉장히 많은 분야에서 활용됨
앙상블 방식의 모델들이 가장 좋은 성능을 보임
너무 긴 실행시간 때문에 실제 프로덕션에서는 사용불가
다양한 알고리즘들이 논문으로 학회에서 발표됨(SVD++)
앙상블(Ensemble)과 랜덤 포레스트(Random Forest)
다수의 분류기를 사용해서 예측하는 방식
성능은 좋지만 훈련과 예측시간이 오래 걸린다는 단점 존재
추천 엔진의 발전 역사
2001년 아마존이 아이템 기반 협업 필터링 논문 발표
2006~2009년 넷플릭스 프라이즈
SVD를 이용한 사용자의 아이템 평점 예측 알고리즘 탄생
앙상블 알고리즘이 보편화됨
딥러닝의 일종이라 할 수 있는 RBM(Restricted Boltzman Machine)이 단일 모델로는 최고의 성능을 보여줌. 딥러닝 추천에서의 사용가능성을 보임
2010년 딥러닝이 컨텐츠 기반 음악 추천에 사용되기 시작
2016년 딥러닝을 기반으로한 추천이 활기를 띠기 시작
오토인코더 기바능로 복잡한 행렬 계산을 단순화하는 방식이 하나
아이템 관련 사용자 정보를 시간순으로 인코드하는 RNN을 사용하는 방식이 다른 하나
아마존에서 DSSNTE라는 알고리즘을 오픈소스화 했다가 나중에 SageMaker라는 제품으로 통합
유데미 추천 엔진 살펴보기
유데미 추천 살펴보기
문제 정의 : 학생들에게 관심있을만한 강의를 먼저 보여주는 것!
추천 UI
격자 기반의 UI
다양한 추천 유닛들이 존재
-> 몇 개의 유닛을 어느 순서로 보여줄지 결정 : 유닛 선택과 랭킹!
-> 페이지 생성 시간과 사용자 만족도는 반비례. 즉 너무 많은 유닛은 역효과를 가져옴
온라인 강의 메타 데이터
분류 체계, 태그
강사에게 태그와 분류 체계 선택하게 하기, 클릭 키워드 분석, ...
다양한 행동 기반 추천
클릭, 구매, 소비 등등
기본 아이디어
-
하이브리드 방식 추천
협업 필터링, 사용자 행동 기반 추천, 머신러닝 모델기반 추천 -
사용자별로 등록 활률을 기준으로 2천개의 탑 강의 목록 생성
배치로 시작했다가 실시간 계산으로 변경 -
홈페이지에서의 추천은 조금더 복잡(개인화되어 있음)
유닛 후보 생성
유닛 후로 랭킹 -
특정 강의 세부 페이지에서 추천은 아이템 중심
Student also bought (아이템 기반 협업 필터링)
Frequently bought together (별도의 co-occurrence 행렬 계산)
각 유닛에서의 강의 랭킹은 개인별 등록 확률로 결정
인기도 기반 추천 엔진 개발
- Cold Start 이슈가 존재하지 않음
- 인기도의 기준
평점, 매출, 최다 판매 - 사용자 정보에 따라 확장 가능
서울지역 인기 아이템 추천 - 단 개인화 되어있지는 않음(어느정도 가능)
- 아이템의 분류 체계 정보 존재 여부에 따라 쉽게 확장 가능
특정 카테고리에서의 인기 아이템 추천
분류 체계를 갖는 것이 여러모로 유리!! - 인기도를 다른 기준으로 바꿔 다양ㅇ한 추천 유닛 생성 가능
새 아이템
기타 Cold Start 이슈가 없는 추천 유닛
현재 사용자들이 구매한 아이템
현재 사용자들이 보고 있는 아이템(영화, 강좌 등등)
실습
영화 추천 데이터를 가지고 인기도 기반 추천 엔진 개발
TMDB 데이터셋을 사용
인기도의 경우 다음 카테고리를 지원
전체 인기도
장르 내 인기도(일종의 분류 체계)
유사도 측정
코사인 유사도와 피어슨 유사도 설명
다양한 유사도 측정 알고리즘
- 벡터들간의 유사도를 판단하는 방법
- 코사인 유사도란?
N차원 공간에 있는 두 개의 벡터간의 각도 (원점에서)를 보고 유사도를 판단하는 기준
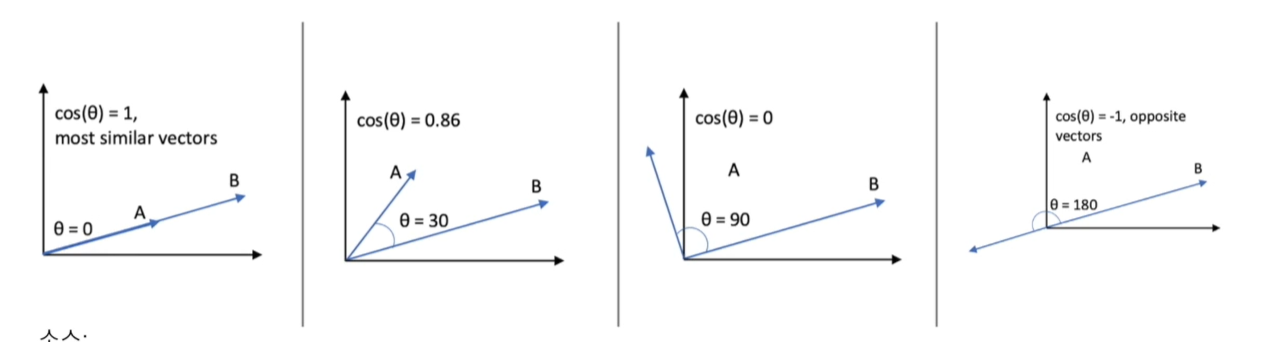
-
표적인 것은 코사인 유사도와 피어슨 유사도
평점처럼 방향 뿐만 아니라 벡터 크기의 정규화가 중요하면 피어슨 유사도를 사용
피어슨 유사도는 코사인 유사도의 개선 버전 -
피어슨 유사도란?
먼저 벡터 A와 B의 값들을 보정
각 벡터내 셀들의 평균값을 구한 뒤 평균값을 각 셀에서 빼줌
그 이후 계산은 코사인 유사도와 동일. 이를 중앙 코사인 유사도 혹은 보정된 코사인 유사도라 부르기도 함 -
피어슨 유사도의 장점
모든 벡터가 원점을 중심으로 이동되고 벡터간의 비교가 더 쉬워짐
평점이란 관점에서는 까다로운 사용자와 아닌 사용자를 정규화하는 효과를 가져옴
TF-IDF 소개와 실습
텍스트를 행렬(벡터)로 표현하는 방법
-
테그스 문서를 행렬로 표현하는 방법은 여러 가지가 존재
기본적으로 일단 단어를 행렬릐 차원으로 표현해야함
Bag of Words 방식은 문서들에 나타나는 단어수가 N개이면 N차원으로 문서 표현
딥러닝의 워드 임베딩 사용시 차원수도 축소되고 공간상에서 비슷한 단어들끼리 가깝게 위치 -
원핫 인코딩 + Bag of Words(카운트)
단어의 수를 카운트 해서 표현 -
원핫 인코딩 + Bag of Words (TF-IDF)
단어의 값을 TF-IDF 알고리즘으로 계싼된 값으로 표현, 중요도를 확인
원핫 인코딩 + Bag of Words(카운트)
먼저 stopWord 제외 (the, is, in, we, can, see)
그 뒤 단어수 계산 -> 총 5개 sky, blue, sun, bright, shining
안어별로 차원을 배정 : sky(1), blue(2), sun(3), bright(4), shining(5)
CountVectorizer
Bag of Words 카운팅 방식을 구현한 모듈
벡터로 표현이 되면 문서들 간의 유사도 측정이 가능
TF-IDF
- 카운트 방식은 자주 나오는 단어가 높은 가중치를 갖게 됨
- TF-IDF의 기본
한 문서에서 중요한 단어를 카운트가 아닌 문서군 전체를 보고 판단
어떤 단어가 한 문서에서 자주 나오면 중요하지만 이 단어가 다른 문서들에서는 자주 나오지 않는다면 더 중요
TF 단어가 문서에서 몇 번 나왔나?
DF 단어가 전체 문서군에서 몇번 나왔나?
IDF 단어가 전쳋 문서들 중 몇개의 문서에서 나왔는지 이 비율을 역으로 계산한 것이 IDF
N는 총 문서수를 나타내고 DF는 단어가 나온 문서를 말한다.
원핫 인코딩 Bag of Words(TF-IDF)
카운트 기반 과 동일한데 카운트 대신 TF-IDF 점수 사용
TF-IDF 문제점
- 정확하게 동일한 단어가 나와야 유사도 계산이 이루어짐
동의어 처리가 안 됨 - 단어의 수가 늘어나고 아이템의 수가 늘어나면 계산이 오래걸림
- 결국은 워드 임베딩을 사용하는 것이 더 좋음
아니면 LSA(Latent Semantic Analysis)와 같은 차원 축소 방식 사용
실습
개념을 이용해 실습
컨텐츠 기반 추천 엔진 개발
TF-IDF를 이용한 컨텐츠 기반 추천과 실습
TMDB 데이터셋을 이용해 비슷한 영화 추천 구현
실습
TMDB 데이터 사용
컨텐츠 기반 추천 엔진 개발
TFIDF VEXTORIZER와 cosine_siliarity를 사용
넷플릭스 프라이즈 소개
유데미 추천 방식 소개
인기도 기반 추천 방식 소개
유사도 계산(코사인과 피어슨)
TF-IDF와 이를 기반으로한 컨텐츠 기반 추천 엔진 실습
