에이블스쿨
1.KT 에이블스쿨 1일차

에이블 스쿨에 합격하고 1일차로는 OT를 진행했다.내일부터 본격적인 수업이 진행된다는데 블로그에 매일 빠짐없이 정리하도록 해야겠다.아자아자 화이팅
2.KT 에이블스쿨 2일차(1)
2일차 실질적으로 오늘 수업이 첫 수업이였습니다.. git의 사용법에 대해 공부했는데 오늘 수업 내용을 정리해보겠습니다. 깃허브에 대해 깃허브는 드롭박스와 다르게 코드를 저장할 때 이전코드를 Overwrite하는 형식이 아닌 버전을 관리해준다. Split을 누르게
3.KT 에이블스쿨 2일차(2)
2일차 수업 깃허브(2)VSCODE를 사용하면 더 유저 친화적으로 GUI를 통해 깃 상황을 볼 수 있습니다. 확장프로그램 중Git Graph를 설치해줘서 깃의 bench나 현황을 볼 수 있습니다.VSCOD를 보게 되면 왼쪽에 확장프로그램 설치나 프로젝트의 파일들을 볼
4.KT 에이블스쿨 2일차(3)
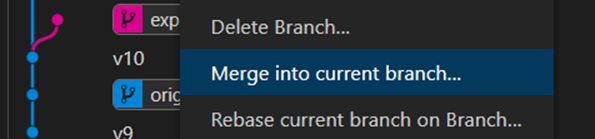
2일차 수업 깃허브(3)프로젝트를 진행하다보면 실험을 위하거나 협업을 위해 브랜치를 나누기도 합니다. 그때 나누어진 브랜치를 합쳐주는 것이 merge입니다.브랜치를 나누고 여러 사람들이 프로젝트 내에 같은 이름의 파일을 수정 후에 해당 브랜치들을 merge하게 된다면
5.KT 에이블스쿨 3일차(1)
파이썬 기초를 배운 오늘파이썬은 input()를 사용하면 사용자에게 직접 입력을 받아 처리할 수 있습니다.출력은 print()를 사용하면 출력이 가능합니다.을 하게 되면 위에 입력한 값이 n에 대입되었다가 print함수를 통해 출력됩니다.파이썬의 print()는 자동
6.KT 에이블스쿨 4일차(1)
파이썬 자료구조와 배열 그리고 검색 알고리즘에 대해 배운 하루배열을 통해 어떻게 자료를 담을지, 어떻게 활용할지에 대해서는 매우 다양한 방법이 있습니다. 파이썬의 리스트 선언은 아래와 같습니다.a = \[] 라고 선언해주면 그냥 빈 리스트를 하나 만들어주는 것입니다.
7.KT 에이블스쿨 5일차(1)
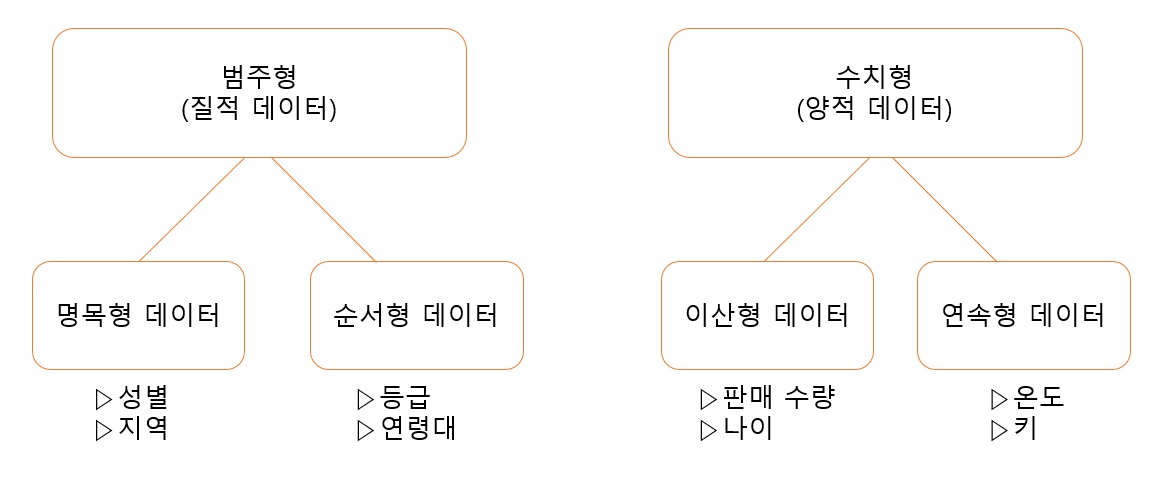
파이썬 라이브러리 Numpy 와 Pandas 사용법 익힌 하루데이터 분석의 큰 그림 : CSISP-DM비지니스 이해(문제 이해) => 데이터 이해 => 데이터 전처리 => 모델링(검증) => 평가 => 배포※큰 틀만 설명을 들었고 자세한 세부사항은 다음 블로그 포스팅할
8.KT 에이블스쿨 5일차(2)
판다스의 라이브러리 가져오기넘파이 라이브러리를 가져오는 것처럼 판다스도 마찬가지로 별칭을 주어 코드를 줄입니다.데이터 분석에서 가장 중요한 것은 데이터 구조입니다. 데이터프레임은 관계형 데이터베이스의 테이블 또는 엑셀과 같은 2차원 구조를 가집니다. 변수들의 집합을 각
9.KT 에이블스쿨 6일차(1)
데이터프레임 변환하는 방법에 대해 학습했습니다.판다스와 넘파이를 import하여 실습환경을 만들어줍니다.데이터 전처리에는 두 가지 과정이 있습니다.1) 데이터 구조 만들기2) 모델링을 위한 전처리데이터를 분석하기 위해서는 우리가 row data를 깔끔하게 분석하기 좋게
10.KT 에이블스쿨 7일차(1)
데이터 처리와 데이터 방법론과 분석한 데이터를 시각화 하는법에 대해 알아보겠습니다. 데이터분석 방법론과 시각화를 분리하여 포스팅하기 위해 방법론을 먼저 포스팅하겠습니다.▶1단계 : 비지니스 이해문제에 대해 정의하는 단계입니다. 분석에 대해 목표를 설정하고 가설을 수립합
11.KT 에이블스쿨 7일차(2)
7일차에 배운 데이터 시각화 방법과 도구들에 대해 포스팅하겠습니다.수 많은 양의 데이터를 확인하기 위한 방법으로 시각화나 통계량을 사용하여 데이터를 확인합니다. 그 중에 데이터를 그래프로 만드는 것을 시각화라고 합니다.우리가 다루는 데이터에는 비지니스가 담겨 있습니다.
12.KT 에이블스쿨 8일차(1)
8일차는 다양한 시각화 수치화 도구들과 함께 데이터의 해석력을 기르는 공부를 했습니다.x와 y의 관계에 대해 그래프로 분석하기 위한 도구가 많이 있습니다. 하지만 도구들마다 한계가 있으니 꼭 그래프가 정답이라고 생각해서는 안됩니다.시각화하는 방법을 먼저 알아보겠습니다.
13.KT 에이블스쿨 9일차(1)

9일차는 전날에 이어 이변량분석 도구들과 데이터를 어떻게 분석하는지에 대해 배웠습니다.데이터를 파악할 때 통계량을 내서 요약을 보고 파악하거나 시각화해서 눈으로 파악하는 방법이 있습니다. 이런 과정을 통해 내가 비지니스이 이해 단계에서 세운 가설이 맞는지를 확인합니다.
14.KT 에이블스쿨 10일차(1)
오늘부터 3일간 미니프로젝트가 진행됩니다혹시 미니 프로젝트 코드를 올려도 된다고 허락을 받으면 코드를 올리면서 복습해보도록 하겠습니다.미니 프로젝트를 들어갔는데 시간이 예상 외로 너무 많이 걸려서 당황했던 하루였습니다.※공부하고 있어 다소 틀린점이 있을 수 있습니다.
15.KT 에이블스쿨 11일차(1)
오늘은 미니프로젝트 2일차!데이터및 CSV파일을 올리지 못하는 관계로 미니프로젝트를 하면서 사용한 코드 리뷰하겠습니다.데이터프레임의 모양(형태)를 알고 싶을 때 .shape()를 사용해주면 데이터프레임의 행과 열을 반환해줍니다.CSV형태의 데이터가 주어지면 pd.rea
16.KT 에이블스쿨 12일차(1)
오늘은 미니프로젝트1의 마지막 날로 앞서 2일의 과정을 하루만에 하는 그런 하루였습니다.오늘은 앞서 이틀과는 다른 데이터를 가지고 분석하는 시간을 가졌습니다.금일 프로젝트의 순서는 가설을 설정하고 단변량 분석, 이변량 분석 후 인사이트를 도출해내는 순서였습니다. 하지만
17.KT 에이블스쿨 13일차(1)
오늘은 미니프로젝트가 끝나고 다시 이론을 공부하는 날이였습니다. 오늘은 미니프로젝트에 대해서 공부했습니다.클라이언트가 URL요청을 하면 웹 서버에서는 request(요청)을 받아서 데이터를 클라이언트에게 response(응답) 해줍니다. 그러면 해당 데이터를 가지고 컴
18.KT 에이블스쿨 14일차(1)
크롤링 2일차-SELECTOR을 이용해서 정적 페이지 크롤링과 셀레니움에 대해 배웠습니다. 복습
19.KT 에이블스쿨 15일차(1)
오늘부터 머신러닝에 대해 본격적으로 들어갔습니다.인간은 경험을 토대로 예측을 합니다. 인간의 경험이 머신러닝에서는 데이터라고 불립니다. 방대한 양의 데이터를 예측 혹은 분류하고자 할 때 기계를 학습시키는데 그것을 머신러닝이라고 부릅니다.머신러닝 즉, 기계가 학습하기 위
20.KT 에이블스쿨 16일차(1)
오늘은 머신러닝의 성능평가와 알고리즘에 대해 배웠습니다. 성능평가 ▶회귀모델 성능평가 회귀모델 평가는 얼마나 그 값과 근사한지를 평가하므로 오차가 존재합니다. 예측 값이 얼마나 실제 값에 가까운지에 따라 성능이 좋은 모델이라고 평가할 수 있습니다. 즉 회귀모델의 평
21.KT 에이블스쿨 17일차(1)
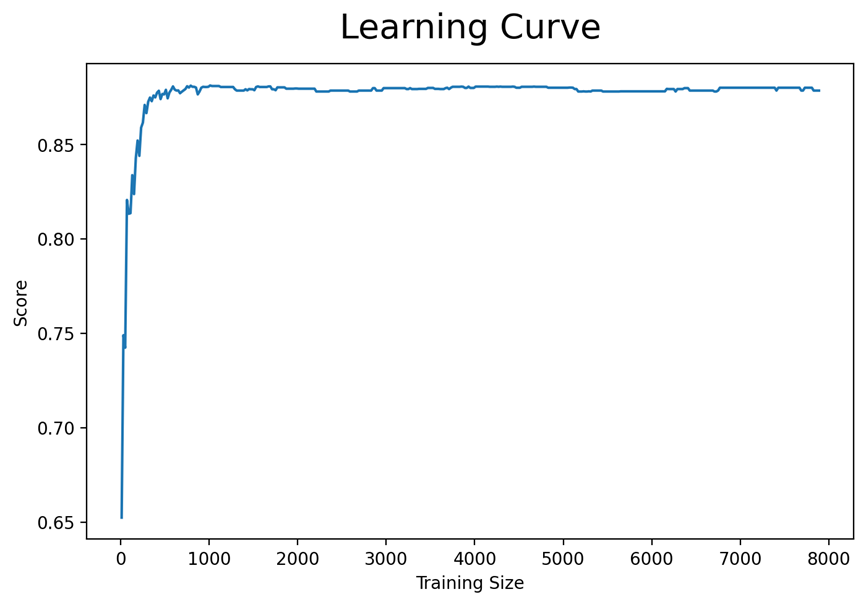
오늘은 머신러닝 3일차로 어제에 이어 여러 알고리즘을 더 배운 날이였습니다.어제에 이어 머신러닝에서 사용되는 다양한 알고리즘에 대해 계속 알아보는 날이였습니다.▶학습곡선데이터가 많으면 성능이 항상 좋은지에 대해 의문이 있을 것입니다. 학습곡선을 통해 이를 알아보고자 학
22.KT 에이블스쿨 18일차(1)
오늘은 머신러닝 4일차로 알고리즘과 머신러닝 성능 향상 방법에 대해 배웠습니다.모델이 복잡하다는 것은 학습데이터에 너무 치중한 나머지 실제 평가데이터로 평가를 진행하면 머신러닝의 성능이 좋지 않은 것을 의미합니다. 즉, 과적합 위험이 있다는 것을 의미합니다.Linear
23.KT 에이블스쿨 19일차(1)
오늘은 머신러닝의 마지막 날이였습니다. 머신러닝 성능 향상을 위한 앙상블에 대해 배웠습니다.Grid Search는 파라미터 조합수 x CV값 만큼 실행을 합니다.Random Search는 전체 파라미터 조합 중에 일부만 성능에 대해 확인합니다.하이퍼파라미터의 최적화된
24.KT 에이블스쿨 19일차(2)
머신러닝의 최종실습을 통해 최종정리를 하겠습니다.▶데이터 가져오기처음으로는 필요한 패키지를 불러옵니다.warings은 오류는 아니지만 경고를 알려주는 해당 경고를 안띄우게 해주는 설정입니다.다음으로는 데이터를 가져옵니다.▶데이터 분석데이터를 불러왔다면 다음으로는 데이터
25.KT 에이블스쿨 20일차(1)
오늘부터 딥러닝에 대해 공부를 시작했습니다.선형회귀를 Neural Network관점에서 이해를 해보았습니다. 변수 하나하나를 노드라고 지칭하고 서로 연결된 선을 연결 혹은 엣지라고 부릅니다. 인풋노드(InputNode)는 입력층(InputLayer)이라고도 하며 하나의
26.KT 에이블스쿨 21일차(1)
오늘부터 딥러닝의 2일차입니다. 복습 loss는 내 예측값을 무엇과 비교할려는지 선택하는 옵션입니다. optimizer는 에러값을 어떻게 줄여나가는지 방법을 선택하는 옵션입니다. 은닉층(히든 레이어) 은닉층 또는 히든레이어라 부르는 해당 레이어는 입력층과 출력층 사
27.KT 에이블스쿨 22일차(1)
오늘은 딥러닝 3일차로 여러옵션과 Function API에 대해 배웠습니다.argmax()는 각 축에서 가장 높은 값을 뽑아주는 함수입니다.mnist는 숫자를 손글씨로 나타낸 데이터들 입니다. 해당 데이터는 2차원 데이터이지만 reshape를 통해 1차원 데이터로 바꾸
28.KT 에이블스쿨 23일차(1)
오늘은 딥러닝 4일차로 딥러닝 학습 마지막 날이였습니다. 복습 scailing(스케일링)은 범위를 균일하게 해줌으로써 한 변수가 영향력을 과하게 행사할 수 있는 것을 방지해줍니다. 머신러닝에서는 타겟값을 건들면 안된다고 배웠지만 딥러닝에서는 각 문제에 맞게 나누었습
29.KT 에이블스쿨 24일차(1)
오늘부터 3일간 머신러닝&딥러닝의 실습시간 입니다.실습에서 사용했던 중요 전처리 밑 코드에 대해 포스팅하겠습니다.시계열 데이터에 있어서 날짜 데이터 formating은 매우 기본적인 거 같습니다.(물론 저는 엄청 해맸습니다,) 예를들어 시계열 데이터로 바꾸자할 때 in
30.KT 에이블스쿨 25일차(1)
오늘은 미니프로젝트(2) 2일차로 row데이터처리와 데이터분석, 모델링까지 진행했습니다.오늘은 row데이터부터 시작해서 모델링까지 프로젝트를 진행했습니다. HTML코드의 데이터를 BeautifulSoup을 통해 데이터를 처리해서 모델링 전 데이터로 가공하는 법을 익혔습
31.KT 에이블스쿨 26일차(1)
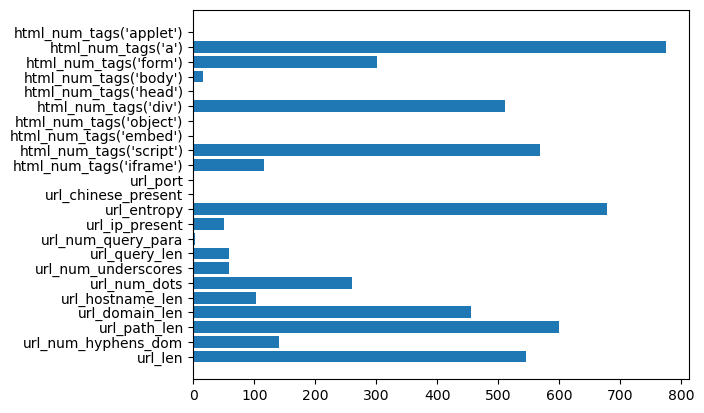
오늘은 미니프로젝트(2)의 마지막 날이였습니다.오늘은 어제에 이어 같은 데이터를 가지고 데이터 튜닝을 진행하면서 캐글에 제출해보는 기회를 가졌습니다.이번 실습에서 전처리가 매우중요하다고 생각합니다. 제가 총 캐글에 제출한 것은 3가지 방법입니다. ▶첫 번째 방법결측치
32.KT 에이블스쿨 27일차(1)
오늘은 머신러닝 평가와 변수의 평가에 대해 공부했습니다. 복습 가변수화를 해주는 조건은 단순히 데이터타입이 Object인 경우에만 해주는 것이 아니라 int형 타입이라도 범주형이라면 가변수화를 진행해줍니다. 예를들어 1등급은 0, 2등급은 1 이런식으로 숫자로 범주를
33.KT 에이블스쿨 28일차(1)
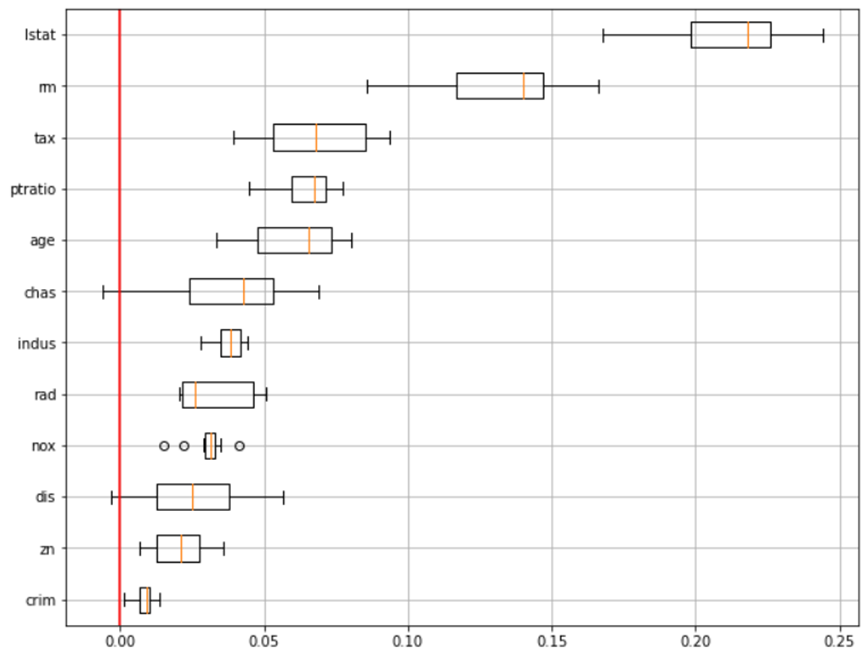
오늘은 변수중요도와 각 변수가 타겟에 대해 영향을 끼치는 가중치를 시각화해서 보았습니다.모델의 목표는 비지니스 이해에 대해 잘 생각해야합니다.모델의 변수중요도를 시각화하는 코드는 아래와 같습니다. 변수중요도의 박스플롯을 시각화하는 방법은 아래와 같습니다.먼저 SVM모델
34.KT 에이블스쿨 29일차(1)
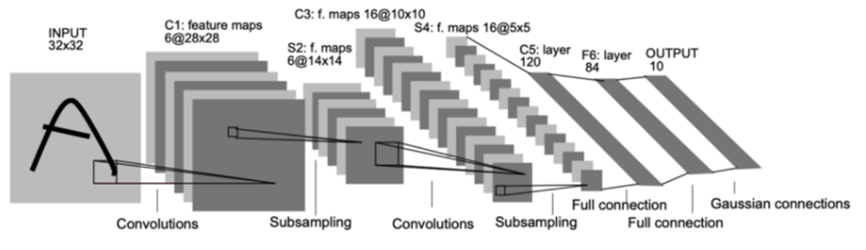
오늘부터 시각지능 딥러닝에 들어갔습니다.지난 딥러닝시간에 tensorflow의 keras를 가지고 딥러닝을 공부했었습니다. keras에는 두 가지의 모델을 배웠습니다. 딥러닝의 모델로는 Sequential API와 Funtional API를 배웠습니다. Sequenti
35.KT 에이블스쿨 30일차(1)
오늘은 CNN 2일차로 CNN 코드 구조 복습과 이미지 데이터가 적을 때 데이터를 늘리는 방법에 대해 학습했습니다.어제에 이어 오늘도 CNN구조에 대해 복습을 했습니다. CNN이란 computer vision을 좀 더 효과적으로 분류하기 위해 사용된 구조입니다.원본인
36.KT 에이블스쿨 31일차(1)

오늘은 시각지능\_딥러닝 3일차로 CNN복습과 모델 저장, InceptionV3 모델 가져오기, YOLO를 실습해보았습니다.kernel_size는 필터의 사이즈입니다. 근데 코드 작성시 kernel_size = (3,3)이런식으로 필터의 크기만 작성했는데 원래는 dep
37.KT 에이블스쿨 31일차(2)

이전 포스팅에 이어서 욜로 사용과 Object Detection에 대해서 포스팅하겠습니다.Object Detection은 Object의 위치와 종류를 동시에 파악하는 기술입니다. 먼저 Localization 단계에서 바운더리 박스안에 문체가 존재하는 알아내고 만약 존재
38.KT 에이블스쿨 32일차(1)
벌써 시각\_딥러닝의 4일차를 보냈습니다. 오늘은 비디오를 Detection 연습을 진행했습니다.Pascal과 MS COCO 데이터 셋이 있는데 요즘은 학습용이나 검증용으로 MS COCO 데이터 셋을 많이 이용합니다.Object Detection를 사용하게 되면 Obj
39.KT 에이블스쿨 33일차(1)
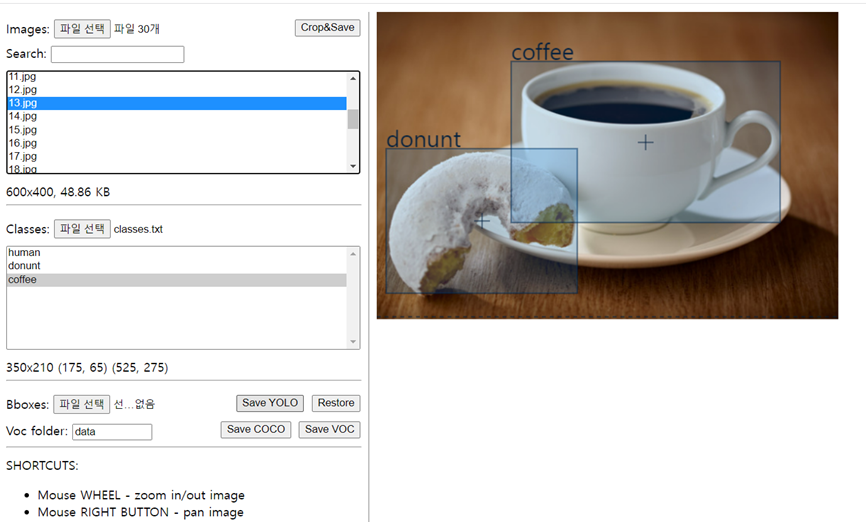
오늘은 시각지능\_딥러닝의 마지막 날이였습니다.YOLO의 특징이라 하면 One Stage Detector라는 특징을 가지고 있습니다. 해당 특징으로 말하자면 위치를 찾는 것과 클레스 구분을 동시에 진행해주는 것을 의미하면 YOLO의 버전이 높아질 수록 실시간 Detec
40.KT 에이블스쿨 34일차(1)
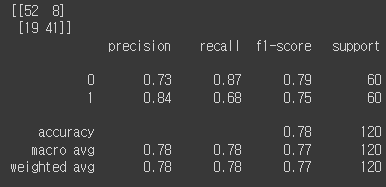
오늘은 CNN 미니프로젝트가 시작되는 날입니다. 문제 정의 이번 프로젝트의 문제는 차량 대여 회사에서 소비자가 차량을 반납했을 때 차량의 사진을 찍어서 제출해주는데 해당 차량에 사고가 있었는지 없었는지를 파악해주는 시각딥러닝을 만들어주는 것을 목표로 프로젝트를 시작했
41.KT 에이블스쿨 35일차(1)
오늘은 미니프로젝트 2일차와 제 멘탈이 붕괴된 날입니다.오늘의 프로젝트는 Data Augmentation과 모델링을 같이 진행했습니다.먼저 부족한 데이터를 증가시키기 위한 Data Augmentation을 진행하겠습니다.Data Augmentation을 위한 패키지를
42.KT 에이블스쿨 36일차(1)

어제에 이어 같은 주제로 미니프로젝트를 이어갔습니다.오늘은 실습 모델인 VGG16모델을 불러와서 실습을 진행하겠습니다. 그리고 추가적으로 어제 0.5에 고정되던 문제 해결 방안을 같이 서술하겠습니다.모델링에 앞서 어제 포스팅에서 0.5로 계속해서 val_accuracy
43.KT 에이블스쿨 37일차(1)
오늘은 새로운 주제로 CNN 프로젝트를 시작했습니다.오늘의 주제는 동전과 지폐 단위를 알아내는 Detection 모델을 만드는 것입니다. 오늘 포스팅은 전처리까지만 하고 내일 모델링을 진행하면 내일 포스팅에 모델링까지 작성하도록 하겠습니다.이제는 코랩에서 구글드라이브
44.KT 에이블스쿨 38일차(1)
어제에 이어서 오늘 모델링까지 진행했습니다.어제는 가이드 라인에 맞춰 전처리를 진행했었고 오늘은 해당 데이터를 가지고 모델링을 진행하겠습니다.먼저 해당 프로젝트는 YOLO을 활용해서 진행하기 때문에 먼저 YOLO를 설치해줍니다.욜로 설치에 앞서 에러가 발생할 수 있으니
45.KT 에이블스쿨 39일차(1)
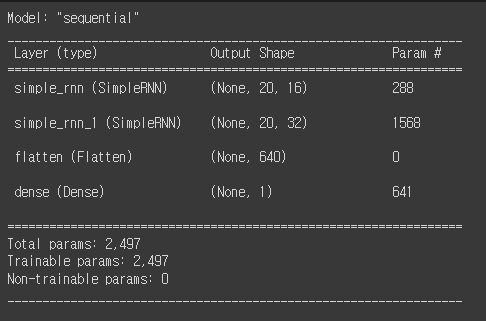
오늘부터 자연어처리에 대해 배우기 시작했습니다.텍스트 마이닝이란 텍스트 데이터로부터 유용한 정보를 추출하여 의사결정에 도움을 받을 수 있는 결과를 도출하는 행위를 의미합니다. 수학 자체도 어떻게 보면 기호를 사용하는 언어 체계이며 인산이 사용하는 언어 체계를 구체적으로
46.KT 에이블스쿨 40일차(1)
오늘은 어제 코드 구조 분석에 이어 LSTM과 GRU를 배웠습니다.어제 포스팅했던 코드 구조에 대해 분석을 이어하겠습니다. return_sequences를 어제 다뤘는데 어제 코드 같은 경우 둘다 False로 설정하게되면 에러가 발생하게 되는데 해당 에러는 shape문
47.KT 에이블스쿨 41일차(1)
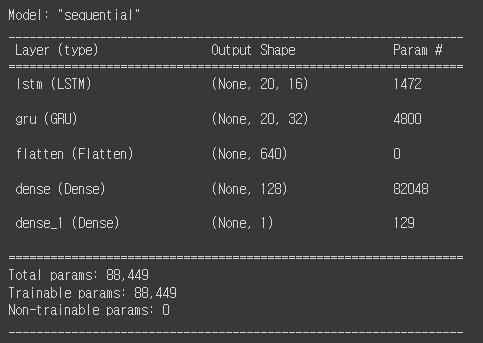
오늘은 코드 구조 분석과 Bidirectional에 대해 배웠습니다.먼저 LSTM 실습코드 부터 보겠습니다.코드를 실행하면 아래와 같은 모델 구조를 확인할 수 있습니다. 파라미터수를 보게 되면 RNN과 차이가 있는데 어제 설명 드린거와 같이 LSTM은 RNN보다 4배
48.KT 에이블스쿨 42일차(1)
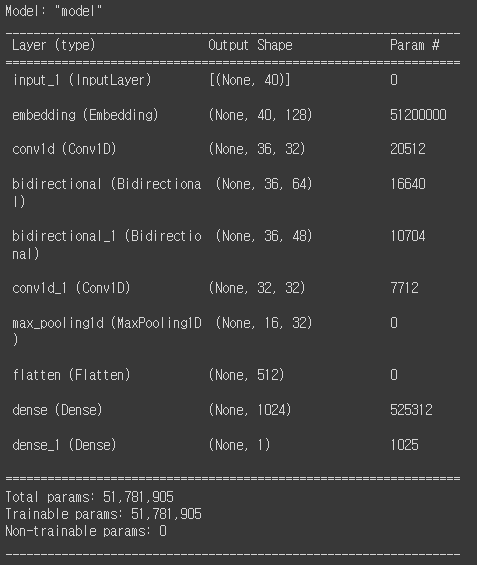
오늘은 문자 분류와 임베딩에 대해서 배웠는데 하루가 정신없이 흘러간 것 같습니다.과거 테크닉으로 Bag of Word가 있습니다. raw 데이터를 가지고 모든 단어마다 인덱스를 할당하고 인덱스만큼의 공간을 확보하고 단어가 나온 횟수만큼 숫자를 주어주는 기술입니다. 문자
49.KT 에이블스쿨 43일차(1)
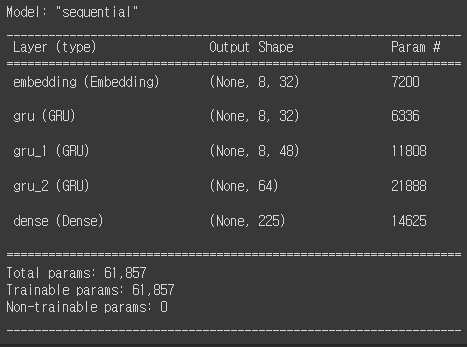
오늘은 자연어처리의 여러가지 예제와 Attention에 대해서 배웠습니다. 가사 예측하기 오늘 여러가지 자연어처리 예제와 Attention에 대해 학습했습니다. 먼저 어제에 이은 예제라 한번에 오늘 포스팅에 작성하겠습니다. 가사를 가지고 다음 나올 가사를 예측하는 자
50.KT 에이블스쿨 44일차(1)

오늘부터 5일간 자연어처리 미니프로젝트가 진행합니다.아직 실습이 모두 끝난 것이 아니라 실습 중에 사용한 코들르 좀 정리하겠습니다..솔직히 아직 이론적으로 부족해서 최대한 이해한 코드 위주로 정리하겠습니다.강사님이 지원해준 코드로도 한글깨짐 방지가 안되서 전에 사용했던
51.KT 에이블스쿨 45일차(1)
자연어처리 NLP의 2일차 프로젝트를 진행했습니다.어제는 주로 주어진 데이터에 대해 분석을 진행했다면 오늘은 데이터 전처리를 중심으로 이루어졌습니다. 특수문자를 제거하기 위해 아래와 같은 코드를 작성했습니다.해당 코드를 사용해서 특수문자 대신에 띄어쓰기로 대체해 주었습
52.KT 에이블스쿨 46일차(1)
자연어처리 NLP의 3일차 프로젝트를 진행했습니다.1-2일차에는 데이터 분석 위주로 진행했고 오늘은 이제 분석을 토대로 어떻게 tokenizer를 진행할 것이고 모델링을 할 것인지에 대해 진행했습니다.오늘은 전체적인 코드를 한번 작성하겠습니다. 어제 포스팅과 중복된 코
53.KT 에이블스쿨 47일차(1)
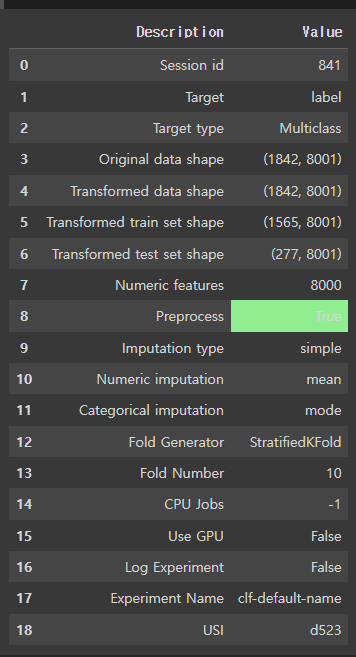
자연어처리 NLP의 4일차 프로젝트를 진행했습니다. Pycaret 어제에 이어 오늘 모델링을 더 진행했습니다. 오늘은 AutoML을 사용해서 모델링을 진행했습니다. AutoML중에 Pycaret을 사용하여 진행했으며 간단하게 코드를 작성하겠습니다. ▶pip ins
54.KT 에이블스쿨 48일차(1)
자연어처리 NLP의 5일차 프로젝트를 진행했습니다.전에 전처리에 문제가 있는거 같아서 팀원이 제공해준 KLUR-BERT의 모델과 tokenizer을 사용했습니다.전처리에 대해서 다양한 에이블러님들의 방식을 볼 수 있는 기회가 있었는데 저는 단순하게 이제 특수문자만 제거
55.KT 에이블스쿨 49일차(1)
오늘은 미니프로젝트 5차로 오랜만에 머신러닝으로 돌아갔습니다오늘은 오랜만에 머신러닝을 사용한 날이었습니다. 전처리부터 머신러닝까지 다뤘고 오랜만에 전처리 코드를 포스팅하겠습니다.데이터 전처리부터 정리하겠습니다.물론 모델링과 전처리 과정에서 더 많은 패키지를 불러와야하지
56.KT 에이블스쿨 50일차(1)
오늘은 미니프로젝트5 2일차로 머신러닝을 이어 진행했습니다.오늘도 마찬가지로 머신러닝을 진행했습니다. 크게 다른 점은 없지만 어제와 다른 코드 사용을 정리하겠습니다.시각화 그래프로 jointplot을 다뤄봤습니다.결과를 보는 코드로 오늘은 회귀모델로 작성해서 위와 같이
57.KT 에이블스쿨 51일차(1)
오늘은 미니프로젝트5 3일차로 다른 주제를 가지고 머신러닝을 진행했습니다. 실습 내용 오늘은 다른 데이터를 가지고 머신러닝을 진행했습니다. 컬럼수가 563개로 지금까지 데이터의 행은 많았지만 오늘처럼 많은 양의 컬럼을 다뤄본 적은 처음이였던 것 같습니다. 실습 코드
58.KT 에이블스쿨 52일차(1)
오늘은 미니프로젝트5 4일차로 어제 주제를 가지고 모델링을 진행했습니다.어제는 컬럼 분석과 컬럼 중요도를 알아보는 시각화에 중점을 두었고 오늘은 모델링을 진행했습니다.데이터를 불러오는거와 기타 전처리는 어제와 같아서 생략하겠습니다.오늘의 모델링에 있어서 목표는 다중 레
59.KT 에이블스쿨 53일차(1)
오늘은 미니프로젝트5 5일차로 캐글을 진행했습니다.어제와 비슷한 주제이지만 제공된 컬럼만 가지고 분류모델을 진행했습니다.저는 AutoML인 PyCaret을 사용했습니다. 원래는 이제 PyCaret을 통해 나온 상위 3개의 모델을 가지고 soft보팅을 한 후 해당 모델을
60.KT 에이블스쿨 54일차(1)
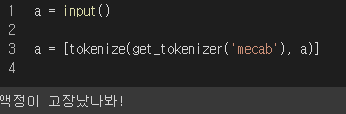
오늘은 미니프로젝트6 1일차로 자연어처리 프로젝트를 진행했습니다.오늘부터 또 새롭게 미니푸로젝트가 들어갔습니다. 오늘은 자연어처리를 활용한 챗봇 만들기였습니다.주어진 데이터를 활용해서 자동으로 답변해주는 모델을 만드는 것이 오늘 목표였습니다.먼저 필요 패키지를 불러옵니
61.KT 에이블스쿨 55일차(1)

오늘은 미니프로젝트6 2일차로 어제에 이어 자연어처리 프로젝트를 진행했습니다.어제는 간단한 모델을 통해서 챗봇을 진행했다면 오늘은 LSTM과 pre-trained된 모델을 가지고 챗봇을 만들어 보았습니다만 pre-trained 모델은 FastText를 사용했는데 잘못
62.KT 에이블스쿨 56일차(1)
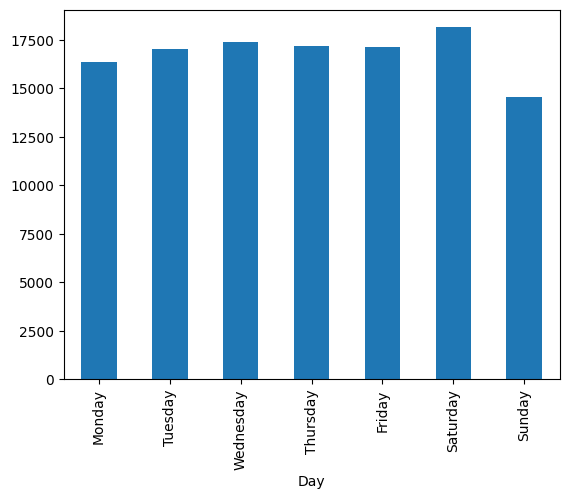
오늘은 미니프로젝트6 3일차로 머신러닝을 새롭게 진행했습니다.어제까지는 자연어처리를 진행했지만 오늘부터는 시계열 데이터의 머신러닝을 진행했습니다.오늘 진행한 데이터는 시계열 데이터입니다. 시간에 따른 타겟값을 예측하는 문제를 진행했습니다.rename을 통해 컬럼명을 변
63.KT 에이블스쿨 57일차(1)
오늘은 미니프로젝트6 4일차로 머신러닝을 이어서 진행했습니다.실질적으로 어제 미니프로젝트를 모두 끝내서 오늘은 대망에 내일 있는 AICE 자격시험을 공부했습니다. 자격시험 공부하면서 공부한 코드 위주로 작성하겠습니다.해당 컬럼에 '\_'값이 있는지 알고 싶을 때는 df
64.KT 에이블스쿨 58일차(1)
오늘은 에이블데이로 자격시험과 특강 그리고 반 모임이 있었습니다. 오늘은 지금까지 에이블스쿨을 토대로 학습한 내용을 토대로 KT인공지능 시험인 AICE의 Associate 단계의 자격시험을 치뤘습니다. 헷갈리는 단어나 사용해본적 없는 옵션이 문제로 나와 당황했지만 침착
65.KT 에이블스쿨 59일차(1)
오늘은 긴 미니프로젝트의 여정이 끝나고 다시 이론 학습을 시작으로 Step2의 여정이 시작되었습니다.금일 수업은 IT인프라에 전반적인 내용을 학습했습니다.서버란 클라이언트에게 네트워크를 통해 정보나 서비스를 제공하는 장치를 의미하고 클라이언트는 네트워크를 통해서 서버에
66.KT 에이블스쿨 60일차(1)
오늘은 웹 개발에 대해 배운 하루였습니다.! 만 누르고 엔터를 누르면 HTML의 전체 틀이 완성됩니다.ctrl + n 을 누르면 새로운 파일이 만들어집니다.ctrl + s 는 파일 저장인데 이때 확장자를 설정해주면 해당 파일이 생성됩니다.ctrl + alt + n을 사
67.KT 에이블스쿨 61일차(1)

오늘은 어제에 이어 웹 개발을 진행했으며 자바스크립트와 jQuery에 대해 배웠습니다.자바스크립트의 사용목적은 CPU, RAM, SSD(HDD) 장치를 활용해서 웹을 개발하는 도구입니다.변수는 RAM을 사용해서 저장 공간을 만들어 데이터를 저장하는 것을 의미합니다.데이
68.KT 에이블스쿨 62일차(1)
오늘은 어제에 이어 웹 개발과 AWS를 이용한 서버 컴퓨팅 그리고 DB에 대해 배웠습니다.해당 코드는 input태그에 name속성이 addr이고 체크된 값의 value를 가져오는 코드입니다.보안상 익명함수로 사용하면 보안성이 향상됩니다. 이런 형태로 사용해주면 됩니다.
69.KT 에이블스쿨 63일차(1)
오늘은 Flask사용과 MongoDB연동을 진행했습니다.MongoDB의 IDE중 하나인 Studio 3T를 사용했고 접속한 후에 IntellShell을 누르면 MySQL과 같이 작성을 할 수 있는 코드창이 하나 나옵니다.위와같이 js 기반으로 코드를 작성할 수 있습니다
70.KT 에이블스쿨 64일차(1)
3일간의 달콤한 휴일이 끝나고 오늘 수업을 진행했습니다.가상화란 물리적인 물질에서 더 다양한 물질을 만들기 위해 가상화 기술을 통해서 분리하여 가상머신에 할당하는 기술을 의미합니다.가상화를 사용하면 물리적인 서버의 대수를 감소하고 전체적인 전력과 관리 비용을 절감할 수
71.KT 에이블스쿨 65일차(1)
어제는 AWS에 관해 배웠고 오늘은 클라우드를 관리하기 위한 쿠버네티스에 대해 배웠습니다.컨테이너는 OS 가상화 기술로 프로세스를 격리하고 리눅스 커널을 공유하는 기술을 말합니다. 즉, 나눠서 사용할 수 있게 해줘서 컨테이너라는 이름이 붙었습니다. AWS에서는 EC2를
72.KT 에이블스쿨 66일차(1)
어제에 이어 쿠버네티스의 개념에 대해 배웠습니다. 그리고 자격증 결과 발표가 있었습니다.쿠버네티스의 가장 작은 최소 단위의 Object입니다. 하나 이상의 컨테이너 그룹을 가지고 있으며 네트워크와 볼륨을 공유합니다Pod yaml파일을 만들때 항상 들여쓰기를 조심해야합니
73.KT 에이블스쿨 66일차(2)

오늘 Associate 결과가 나왔습니다.KT 인공지능 자격시험 중 Associate 단계의 인공지능 자격시험을 에이블스쿨에서 지원해줘서 시험을 치뤘다고 2주전 블로그 포스팅에 작성했습니다.오늘 그 결과가 나왔습니다.결과는...합격했습니다. 시험 끝나고 다시 복기했을때
74.KT 에이블스쿨 67일차(1)
또 황금같은 3일의 연휴가 끝나고 이론 수업이 돌아왔습니다. SQL SQL은 Structured Query Language의 약자로 구조화된 쿼리문입니다. 데이터베이스에서 데이터를 조회하거나 조작을 할 때 사용되는 구문입니다. 관계형DB을 조작할 때 사용하고 NoS
75.KT 에이블스쿨 68일차(1)
어제에 이어 마저 MySQL에 대해서 공부했습니다.그룹별 집계집계 기준열을 지정해 그룹별 집계(SUM, AVG 등등)하는 것입니다.부서별, 남녀별, 지역별, 연도별 등등 '별'을 기준으로 그룹화 해줍니다.해당 코드를 보게 되면 집계는 NULL을 무시하기 때문에 IFNU
76.KT 에이블스쿨 69일차(1)
오늘부터 이제 5일간 에이블스쿨의 마지막 이론 수업 Django를 배웁니다.장고는 파이썬으로 만든 웹 프레임워크로 빠르고 효율적인 웹 개발이 가능합니다. MVT 패턴을 가지고 있습니다. M은 Model, V는 View, T는 Template의 약자입니다. Model은
77.KT 에이블스쿨 70일차(1)
오늘은 장고2일차로 템플릿과 데이터베이스 연결에 대해 배웠습니다.이미지 영상을 Dynamic하게 처리하는 것보다 그냥 Static File로 연결만 하면 어떨까 라는 생각을 가지게 되었습니다.setting.py를 보게 되면 STATIC_URL = "static/"이라
78.KT 에이블스쿨 71일차(1)
오늘은 장고3일차로 ORM과 모델에 대해 배웠습니다.어제에 이어 추가로 작성하겠습니다. django-extensions 라이브러리 설치합니다.settings.py에 INSTALLED_APPS 등록합니다.shell_plus 에 진입해서 코드를 사용합니다.생산성, 가독성,
79.KT 에이블스쿨 72일차(1)
오늘은 장고4일차로 Admin페이지와 Cookie & Session에 대해 배웠습니다.장고는 관리자 페이지인 Admin 페이지를 제공합니다. 관리툴이 제공되기 때문에 금방 수정할 수 있습니다. admin.py에 모델을 설정해두면 admin페이지에서 해당 모델의 테이블을
80.KT 에이블스쿨 73일차(1)

오늘은 장고5일차로 API와 딥러닝을 활용한 간단한 애플리케이션을 만들었습니다.웹 상에서 HTTP 프로토콜을 이용해서 다른 곳의 자료를 이용하는 것을 RESTful API라고 합니다. API란 프로그래밍할 수 있는 인터페이스를 뜻합니다.RESTful API의 규칙은 아
81.KT 에이블스쿨 74일차(1)
오늘부터 마지막 미니프로젝트에 들어갔습니다.CRISP-DM비지니스 문제 이해데이터 이해데이터 전처리모델링평가배포ML코드만으로 시스템을 구축할 수 없어서 주변에 방대하고 복잡한 인프라가 있습니다.MLOps란 기계 학습 운영을 위한 프로세스, 도구 및 방법론입니다. 기계
82.KT 에이블스쿨 75일차(1)
오늘은 MLflow에 대해 배웠습니다. MLflow는 사기입니다.사이킷런에서 MinMax 스케일링을 사용할려면 reshape 전에 스케일링을 하고 reshape를 해야합니다.머신러닝을 진행하면 모델의 관리와 모델 배포에 대한 고민이 있습니다. 추적이란 중요한 정보를 기
83.KT 에이블스쿨 76일차(1)
오늘은 STEP2에서 배웠던 AWS를 전반적으로 다시 한번 사용했던 시간이였습니다.미니프로젝트가 본격적으로 시작하면서 지금까지 배운 step2의 과정을 진행했습니다.클라이언트 환경에 있는 파이썬 소스를 넘겨주는 프로그램중 하나로 이번 미니프로젝트에서는 winscp를 설
84.KT 에이블스쿨 77일차(1)
오늘은 STEP2에서 배웠던 장고를 MVT에 맞게 구성하는 시간과 OpenAI을 적용해보는 시간을 가졌습니다.장고 프로젝트의 생성 순서는 아래와 같습니다.앱 생성설정 (settings.py -> INSTALLED_APPS )라우터 (urls.py) 구현 , 브라우저부터
85.KT 에이블스쿨 78일차(1)
오늘은 지금까지 프로젝트에 이제 CSS를 첨가하여 보이는 화면을 꾸몄습니다.오늘은 따로 수업이 있던 것이 아니라 사실 포스팅할 것이 없습니다.장고는 CSS를 적용하는 방법이 {% load static %}을 활용해서 css와 같은 정적 파일을 관리하는 폴더를 만들어서
86.KT 에이블스쿨 79일차(1)

오늘은 어제에 이어 CSS를 활용해서 화면을 꾸몄습니다.팀원 별로 각각 화면 꾸미기를 진행했는데 감기기운 때문에 너무 정신을 못차리고 진행해서 완성도가 많이 낮습니다.메인 화면은 이렇게 꾸몄습니다. 각 메뉴별로 쉽게 이동할 수 있게 부트스트랩을 사용했습니다.OpenAI
87.KT 에이블스쿨 80일차(1)
오늘은 다른 팀들의 프로젝트를 구경한 날이였습니다.오늘은 프로젝트 마무리 짓고 다른 팀들의 프로젝트도 보는 날이었습니다. 사실 그래서 쓸 내용이 없습니다.. 감사합니다.아 그리고 이제 모든 미니프로젝트와 이론이 끝났고 남은 한달 반 동안의 기간 동안 빅프로젝트를 들어갑
88.KT 에이블스쿨 81일차(1)
오늘은 STEP2가 끝나고 에이블데이 2차를 진행했습니다.오전 10-12시까지는 코딩테스트를 진행했습니다. 결과는 제출하자마자 확인할 수 있었는데 3번 째 문제 안 고쳤으면 점수가 더 높았을텐데 아쉬움이 남았습니다.오후 시간중 1시부터 4시까지는 자소서 컨설팅 특강을
89.KT 에이블스쿨 빅프로젝트 1주차
빅프로젝트 1주차 정리하겠습니다. 1등 워크숍 오프라인으로 수도권에 속한 저는 분당 KT 본사에서 오프라인 모임을 진행했습니다. 오르라인으로 조원들을 만나며 아이스브레이킹 시간과 프로젝트 관리 조별 모임이 시작하기 전에 짧게 30분간 GIT과 프로젝트 관리 방법 애
90.KT 에이블스쿨 빅프로젝트 2주차

빅프로젝트 2주차 정리하겠습니다. 2주차 산출물 정리 2주차로 제출해야되는 서류로 요구사항 정의서, 서비스 Flow, ERD, UIUX 설계서를 작성해서 제출해야 했습니다. 서비스 Flow와 UIUX 설계서는 피그마를 통해 팀원들과 함께 작성하였고 ERD는 ERD
91.KT 에이블스쿨 빅프로젝트 3주차
빅프로젝트 3주차 정리하겠습니다.3주차부터는 직접적인 설계와 개발을 해야함으로 따로 제출하는 제출물은 없어 개발에 신경을 많이 사용했습니다. 2주차에 이어 로그인 회원가입뿐만 아니라 더 필요한 테이블을 생성하고 view를 1차로 개발했습니다. 저는 1차 적으로 view
92.KT 에이블스쿨 빅프로젝트 4주차
빅프로젝트 3주차 정리하겠습니다.4주차는 3주차에 이어서 개발을 계속 진행했습니다.장고의 DB를 추가하거나 제거하는 작업을 반복적으로 진행했습니다. 프로젝트가 진행하면서 처음에 계획했던 거와 다르게 수정사항이 항상 있기 때문에 DB에서도 테이블을 제거하거나 필드를 수정
93.KT 에이블스쿨 빅프로젝트 5주차
빅프로젝트 5주차 정리하겠습니다.빅프로젝트의 마지막 주인 5주차가 시작되었습니다.5주차 이후로는 이제 제가 진행한 DB 생성한 동작 확인을 한번 더 점검하고 프론트 부분에서 연결이 잘 안되는 부분을 체크하기 시작했습니다. 또한 프로젝트 부분에 있어서 의사와의 상담하기
94.KT 에이블스쿨 빅프로젝트 6주차_마지막
빅프로젝트 6주차 마지막 주에 대한 내용을 정리하겠습니다.빅프로젝트의 제출 기간이 있는 마지막 주인 6주차가 시작되었습니다.이제 개발이 어느 정도 끝난 저라서 저는 CAPCUT이라는 무료 영상편집 프로그램을 사용하여 프로젝트의 소개와 발표영상을 컷 편집하고 간단하게 자
95.에이블스쿨 잡페어 및 최종수료 후기
빅프로젝트 끝났고 이제 우리의 시간입니다.에이블스쿨에서 이제 빅프로젝트가 끝나고 취업준비생인 에이블러들을 위해 취업특강을 진행하고 면접의 노하우가 많은 분들이 참여하여 피드백을 해주었다고 했지만 전 예비군으로 인하여 참여하지 못하였습니다....모든 에이블러분들이 모여서