오늘은 어제 코드 구조 분석에 이어 LSTM과 GRU를 배웠습니다.
코드 구조 분석 추가
어제 포스팅했던 코드 구조에 대해 분석을 이어하겠습니다.
return_sequences를 어제 다뤘는데 어제 코드 같은 경우 둘다 False로 설정하게되면 에러가 발생하게 되는데 해당 에러는 shape문제로 발생하는 에러로 keras구조 문제로 생기는 에러입니다.
파라미터 계산
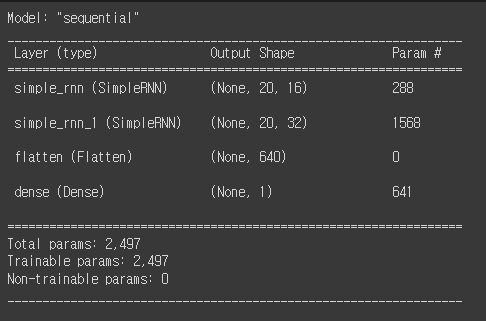
어제 포스팅한 모델의 구조를 보면 파라미터를 볼 수 있는데 해당 파라미터를 계산하는 방법은 아래와 같습니다.
먼저 첫번째 레이어 인풋 레이어는 (20, 6)이고 다음 레이어인 simple_rnn의 파라미터를 계산하면 (이전 레이어의 노드수 + RNN의 노드 수 + bias편향) * (RNN의 노드 수)로 구할 수 있습니다. 현재 코드를 보게 되면 첫 번째 RNN의 층수는 model.add(keras.layers.SimpleRNN(16, return_sequences=True))로 작성했기 때문에 RNN의 히든스테이트 수는 16입니다. 이전 레이어의 노드 수는 6개로 편향은 1인데 정말 가끔 다른 수로 설정할 수 있지만 대부분의 경우가 1입니다. 따라서 계산을 해보면 (6+16+1)*16으로 최종 값은 288입니다. 다음 층의 파라미터도 아래와 같은 계산으로 구해준다면 (16+32+1)*32로 1568이 나오는 것을 확인할 수 있습니다.
만약 RNN의 노드가 16개이고 인풋노드가 6개 이전 시점의 히든 스테이트가 16개라면 아래와 같이 계산할 수 있습니다.
히든스테이트 총 16개의 간선 인풋의 간선 6개 bias(편향) 1개 그래서 1층 RNN레이어의 파라미터 값은 (16 + 6 + 1) * 16(레이어의 총 히든스테이트 수) = 368이 나옵니다.
LSTM(Long Short Term Memory)
LSTM은 기본적으로 RNN의 구조적 특징 + 메모리 + Memory Managing으로 이루어져 있습니다. Long Term은 보존을 Short Term은 손실을 의미합니다.
LSTM은 여러 Gate가 존재하는데 하나씩 알아보겠습니다.
Forget Gate는 LSTM의 구성 요소 중 하나이며, 현재 입력과 이전 상태의 값을 기반으로 어떤 정보를 잊을 것인지를 결정하며, 이전 시점 단계에서의 기억 값을 일부분 삭제하는 역할을 합니다. 시점과 무관하게 일관된 규칙을 적용합니다.
여기서 히든스테이트는 기억 관리 보조 정보를 가지고 있습니다.
Input Gate는 과거의 정보와 현시점의 정보를 가지고 일관된 규칙을 적용하여 섞는 게이트를 생성하고, 이를 이용하여 어떤 정보를 추가할 지 결정하고 이를 tanh로 스케일링을 하는 과정을 진행합니다.
Update Cell State는 과거로부터 온 기억(Forget Gate)와 현재 기억할만한 가치가 있는 기억(Input Gate)으로 부터 온 기억들을 통합하여 현시점의 새로운 기억을 만듭니다.
New Hidden State는 통합된 기억을 가지고 과거로부터 온 정보를 가지고 Output Gate를 만듭니다. 만들어진 Output Gate의 값을 가지고 sigmoid를 통해 규격을 맞춰주는 과정이 발생합니다.
최종적인 LSTM를 작성하기 위한 코드를 보게 되면 (히든스테이트의 수, activation(tanh, sigmoid가 기본 탑재, return_squences) 형태를 가집니다. RNN과 큰 차이가 없습니다.
LSTM은 RNN 대비 동일 조건(히든스테이트 수가 같다는 조건) 하에 가중치가 RNN보다 4배 더 큽니다. 메모리도 RNN에는 존재하지 않지만 LSTM에는 존재합니다. 즉, RNN보다 조금 더 똑똑하고 무거운 금붕어 모델입니다.
GRU
LSTM의 무겁다는 문제를 해결하면서 Gating 기법을 정돈합니다. 전체적인 틀은 LSTM과 비슷합니다. GRU에서는 Cell State와 Hidden State를 통합했습니다. Gate를 1- 라는 것을 이용해서 재활용을 해서 8대 2 비율을 조절했습니다.
추가 정리
backpropagation 출력값과 실제값의 차이인 오차를 이용하여 각 층의 가중치를 업데이트하고, 이를 반복하여 학습을 진행하는 알고리즘입니다.
transformer는 attention라는 강제 집중 기억 장치를 통해서 순간 순간 중요한것을 뽑아서 문제해결을 합니다.
코드 구조를 파악하는게 아직은 익숙하지 않습니다만 열심히 파악해볼려고 노력중입니다.
※공부하고 있어 다소 틀린점이 있을 수 있습니다. 언제든지 말해주시면 수정하도록 하겠습니다.
※용어에 대해 조금 공부 더 해서 수정하겠습니다.
