오늘은 머신러닝 평가와 변수의 평가에 대해 공부했습니다.
복습
가변수화를 해주는 조건은 단순히 데이터타입이 Object인 경우에만 해주는 것이 아니라 int형 타입이라도 범주형이라면 가변수화를 진행해줍니다. 예를들어 1등급은 0, 2등급은 1 이런식으로 숫자로 범주를 나타낸 데이터라면 모두 가변수화를 진행해줍니다.
하나의 feature가 나머지 feature로 설명이 되냐는 것을 살펴보는 것이 다중공선성입니다.
모델링을 하고 시각화하는 것은 매우 중요합니다. 시각화된 그래프를 보게 되면 모델의 성능평가 추이를 확인할 수 있고 이를 통해 예측을 할 수 있습니다.(하이퍼파라미터에 따라 어떤 성능을 가지는 지...) 추이를 보고 성능이 고점인 곳을 보고 이해할 수 있어야 합니다. 튜닝을 진행했을 경우 시각화를 통해 추이를 봐야합니다.
시각화하는 코드는 아래와 같습니다.
result = pd.DataFrame(model.cv_results_)
plt.figure(figsize = (10,6))
sns.lineplot(x='param_n_neighbors', y='mean_test_score', data = result,
marker = 'o', hue = 'param_metric')
plt.grid()
plt.show()해당 코드를 사용하면 아래와 같은 결과가 나옵니다.
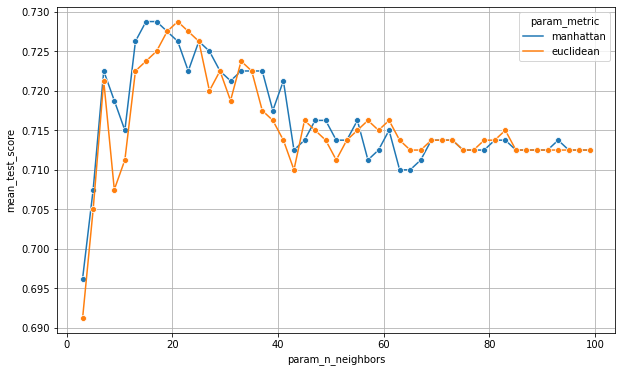
이를 통해 우리는 머신러닝이 하이퍼파라미터 튜닝에 따라 어떤 성능향상의 추이를 갖는지 확인할 수 있습니다. 해당 그래프를 보면 15~25사이일 때 모델이 제일 좋은 성능을 가졌던 것을 확인할 수 있습니다.
튜닝을 하고 원래는 그냥 튜닝 결과중 제일 잘 나온 모델(GridSeach로 학습했을 경우..)를 가지고 학습을 시켰는데 시각화를 해서 추이를 보고 좋은 모델을 선택할 수 있도록 해야된다고 강사님께서 말씀해주셨고 시각화를 해서 해당 그래프를 분석하는 것이 중요하다고 말씀해주셨습니다.
과적합된 모델은 train 데이터 셋에 너무 모델링이 된 모델을 가지고 과적합된 모델이라고 합니다. train 데이터 셋을 기준으로는 정말 좋은 성적을 기록하지만 막상 test를 해보면 비슷한 점수가 안나오기 때문에 train 데이터 셋에서 좋은 결과가 나왔다고 마냥 좋은 것은 아닙니다.
해석
만약 모델의 성능이 낮은 경우 해당 모델에 대해 분석하고 해석하는 것은 의미가 없습니다. 모델을 최적한 후에 모델을 해석하는 것이 매우 중요합니다.
모델의 Input을 보고 Output을 예측하는 것을 해석이라고 합니다. 어떤 Input에 어떤 Output이 나오는지 보이는 모델을 화이트박스 모델(White Box Model)이라고 합니다. 대표적으로 선형회귀 로지스터, 결정트리 모델이 있습니다. 반면 모델 어떤 구조인지 이해를 못하는 모델을 블랙박스 모델(Black Box Model)이라고 합니다.
해석이 왜 필요하냐면 고객에게 설명을 해주기 위해서 필요합니다. 설명이 잘되는 알고리즘은 대체로 성능이 낮다는 단점이 있습니다.
변수중요도(Featur Importance)
변수중요도는 알고리즘 별로 내부 규칙에 의해서 예측에 대해 변수 별로 영향도를 측정한 값입니다. 모델에서 변수중요도를 제공해주는 알고리즘은 Decision Tree, XGB등이 있습니다/
변수중요도가 계산이 되는 것은 여러가지 방법이 있습니다.
Decision Tree 모델에서 Information Gain은 지니 불순도가 감소하는 정도를 알려줍니다. 이 Information Gain을 가지고 평균을 계산 하는 방법 있습니다. 즉, MDI(Mean Decrease Impurity)는 트리 모델을 구성할 때 각 변수가 분기 결정에 얼마나 중요하게 작용했는지를 알려줍니다.
랜덤포레스트는 Mean Decrease GINI 계산 방법으로 변수중요도를 구합니다. Mean Decrease GINI의 계산 방법은 개별트리의 MDI로부터, feature별 Importance 평균을 계산합니다.
XGB에서 변수중요도를 계산하는 방법은 3가지가 있습니다.
▶weight는 가중치로써 모델 전체에서 해당 Feature가 split할 때 사용된 횟수의 합으로써 plot_importance을 사용해 시각화할 수 있습니다.
▶gain은 불순도로 feature별 평균의 information gaun입니다. model.feature_importances_을 사용해 시각화할 수 있습니다.
▶cover는 freature가 split할 때 샘플 수의 평균으로써 total_cover는 샘플수의 총 합을 의미합니다.
오버샘플링
전에도 포스팅한 적이 있는데 오늘도 수업에 나와서 한번 더 정리하겠습니다.
오버샘플링이란 Target값이 분류일 때 클레스가 한쪽으로 치우쳐진 것을 해결하는 방안입니다. 한쪽으로 값이 치우쳐져 있다면 한쪽만 잘 맞추는 모델이 완성되기 때문에 이런 현상을 막아주어야합니다. 방법으로는 Down, Up, Smote 방법이 있는데 거의 성능이 비슷하다고 합니다.
Smote의 방식은 아래와 같습니다.
from imblearn.over_sampling import SMOTE
smote = SMOTE()
x_train_s, y_train_s = smote.fit_resample(x_train, y_train)
print(np.bincount(y_train_s))
print(np.bincount(y_train_s) / y_train_s.shape[0])알고리즘과 상관없이 변수 중요도를 파악하는 방법(PFI)
순열(Permutatuion)은 순서가 부여된 임의의 집합을 다른 순서로 섞어버리는 연산으로 Feature하나의 데이터를 무작위로 섞을 때, model의 score가 얼마나 감소되는지를 확인할 수 있습니다. 만약 변화가 크다면 성능에 영향이 갈 정도로 중요하고 반대로 변화가 적다면 영향이 없다는 것을 의미합니다.
변수중요도를 확인하는 이유는 Feture하나를 가지고 만약 섞고 나서 모델의 성능이 더 좋아진 경우에 Feature을 아예 빼주면 성능이 좋아지겠다라는 기대감을 가지고 머신러닝이 가능하기 때문입니다. 섞어준다는 것은 해당 Feature를 무력화해주는 것을 의미합니다.
이런과정들을 걸쳐 어떤 Feature가 불필요한지 확인할 수 있습니다.
PFI도 단점이 존재합니다, 만약 다중 공선성이 있는 변수가 존재한다면 특정 변수 하나가 섞이면 관련된 변수는 그대로 있기 때문에 Score별로 안줄어들어서 해당 변수가 중요한 변수라고 오판단할 수 있습니다.
모든 알고리즘이 다중공선성을 이르키는 것은 아닙니다. 선형회귀나 로지스터회귀에서 다중공성선 문제가 생깁니다.
오랜만의 이론수업이라 그런지 이론이 들어왔다가 뇌를 거치지 않고 바로 빠져가는 느낌을 받았습니다. 복습하면서 다시 한번 더 생각해봐야겠습니다.
※공부하고 있어 다소 틀린점이 있을 수 있습니다. 언제든지 말해주시면 수정하도록 하겠습니다.
※용어에 대해 조금 공부 더 해서 수정하겠습니다.
