오늘은 미니프로젝트(2)의 마지막 날이였습니다.
실습
오늘은 어제에 이어 같은 데이터를 가지고 데이터 튜닝을 진행하면서 캐글에 제출해보는 기회를 가졌습니다.
전처리
이번 실습에서 전처리가 매우중요하다고 생각합니다. 제가 총 캐글에 제출한 것은 3가지 방법입니다.
▶첫 번째 방법
결측치 값을 모두 0으로 처리했습니다. 알고리즘은 LightGBM을 사용했습니다. 결측치를 모두 0으로 처리했을 때는 0.855로 거의 꼴찌 수준에 가까운 점수가 나와서 많이 당황했음과 동시에 역시 모델링에 앞서 전처리는 매우 중요하다고 생각했습니다.
▶두 번째 방법
결측치를 KNN 선형 보간법을 사용해서 결측치를 채워줬습니다. 제가 사용한 코드는 아래와 같습니다.
from sklearn.impute import KNNImputer
x_test_cols_t = x_test_f_1.columns
imputer=KNNImputer(n_neighbors=4)
x_test_f_1=imputer.fit_transform(x_test_f_1)
x_test_f_1=pd.DataFrame(x_test_f_1, columns=x_test_cols_t)해당 방법을 사용했을 때는 성능이 많이 향상되어 0.924로 그냥 무작정 0으로 채우는 것보다 성능이 많이 향상됨을 확인할 수 있었습니다.
▶세 번째 방법
필요없는 컬럼이라고 판단되는 컬럼들을 삭제해주는 방법을 가졌습니다. 해당 방법은 먼저 모델링을 진행한 후에 . model.best_estimator_.feature_importances_를 사용하여 아래와 같이 변수 중요도를 시각화했습니다.
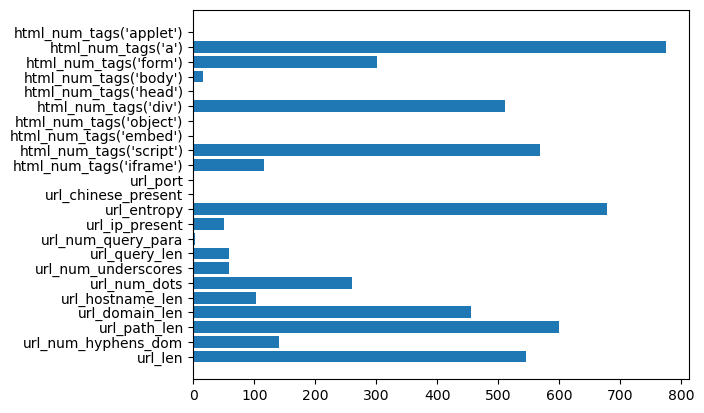
변수중요도를 보게 되면 0에 가까운 중요도를 가지는 변수들을 한번 삭제한 후에 진행해 봤습니다. 그런데 오히려 더 줄어드는 경향을 보여서 일단 변수 제거는 하지 않고 진행했습니다.
알고리즘 선택
알고리즘을 RandomForest와 LightGBM을 이용해서 더 높은 알고리즘을 선택했습니다. 2개만 사용한 이유는 그저 당연히 LightGBM이 최고라 생각하고 바로 튜닝으로 돌려서 진행하는 불상사를 저질러서 두 개의 알고리즘밖에 진행하지 못했습니다. 최종 선택은 train테스트로 검증했을 때 가장 높게 나왔던 LightGBM을 선택해서 캐글에 제출용 CSV를 만들었습니다.
보완 및 공부할 점
조금 아쉬웠던 점은 다들 변수의 상관계수를 찾아서 지우니깐 모델의 성능이 향상되었는데 저도 corr()를 통해 상관계수 분석하는데 시간을 더 투자했으면 좋았을 텐데라는 아쉬움이 남았습니다. 또한 머신의 튜닝도 물론 성능향상에 큰 도움이 되지만 전처리와 결측치 처리가 정말 중요한 것 같다고 한번더 느낄 수 있었습니다.
다른 조 에이블러분들이 발표하는 것을 보고 굉장히 공부하면 좋은 것들을 메모해두겠습니다.
AutoML이라고 자동으로 모든 알고리즘에 대해 평가를 해주는 Open API가 있다고 알게 되었습니다. 그중에서 많은 에이블러분들이 pycaret을 사용한 것 같아서 한번 저도 써볼려고 합니다.
프로젝트를 통해 수업 내용이 아닌 다양한 것을 배울 수 있는 기회가 주어지는 것 같습니다. 프로젝트 조원, 동기 에이블러분들을 통해 정말 많은 것을 배운 프로젝트 기간이였던 것 같습니다.
※공부하고 있어 다소 틀린점이 있을 수 있습니다. 언제든지 말해주시면 수정하도록 하겠습니다.
※용어에 대해 조금 공부 더 해서 수정하겠습니다.
