오늘은 변수중요도와 각 변수가 타겟에 대해 영향을 끼치는 가중치를 시각화해서 보았습니다.
모델 해석
모델의 목표는 비지니스 이해에 대해 잘 생각해야합니다.
모델의 변수중요도를 시각화하는 코드는 아래와 같습니다. 변수중요도의 박스플롯을 시각화하는 방법은 아래와 같습니다.
먼저 SVM모델을 만들어 줍니다.(다른 알고리즘도 가능합니다.)
model = SVR()
model.fit(x_train_s, y_train)다음으로는 전날에 배운 PFI를 구하는 코드를 작성해줍니다.
pfi = permutation_importance(model, x_val_s, y_val, n_repeats=10,
scoring = 'r2', random_state=20)위 코드의 자세한 해석은 아래와 같습니다.
model: 변수 중요도를 계산하고자 하는 모델
x_val_s: 변수 중요도를 계산하고자 하는 데이터셋의 독립 변수
y_val: 변수 중요도를 계산하고자 하는 데이터셋의 종속 변수
n_repeats: 각 변수의 중요도를 계산할 때, 샘플을 무작위로 섞는 횟수
scoring: 성능 측정 방법. 'r2'는 결정 계수를 의미합니다.
random_state: 재현성을 위한 랜덤 시드 값
다음으로 아래와 같이 작성해주면 박스플롯 시각화 그래프를 얻을 수 있습니다.
sorted_idx = pfi.importances_mean.argsort()
plt.figure(figsize = (10, 8))
plt.boxplot(pfi1.importances[sorted_idx].T, vert=False, labels=x.columns[sorted_idx])
plt.axvline(0, color = 'r')
plt.grid()
plt.show()
해당 코드를 통해 아래와 같은 결과를 얻을 수 있습니다.
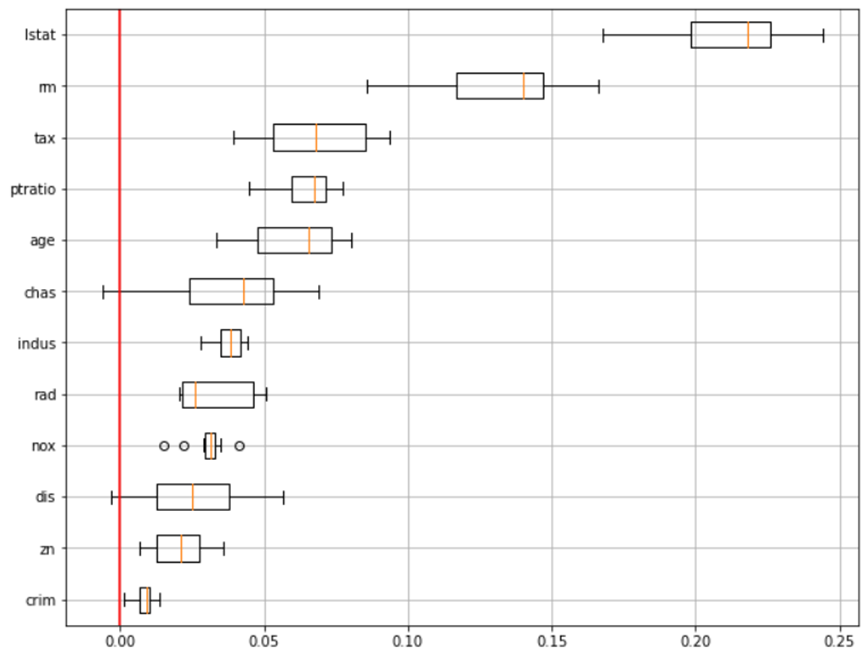
위와 같은 코드 순서로 작성하면 해당 모델의 변수중요도를 알 수 있습니다. 박스플롯이 아닌 다른 시각화도 그릴 수 있습니다.
실습(트리 알고리즘)
실습으로 전체적인 코드를 트리모델과 트리모델이 아닌 모델들의 변수중요도를 살펴보겠습니다.
먼저 데이터 수집과 전처리 까지 완료되었다는 가정하에 진행하겠습니다.
▶변수 중요도를 그려주는 함수입니다.
def plot_feature_importance(importance, names, topn = 'all'):
feature_importance = np.array(importance)
feature_names = np.array(names)
data={'feature_names':feature_names,'feature_importance':feature_importance}
fi_temp = pd.DataFrame(data)
fi_temp.sort_values(by=['feature_importance'], ascending=False,inplace=True)
fi_temp.reset_index(drop=True, inplace = True)
if topn == 'all' :
fi_df = fi_temp.copy()
else :
fi_df = fi_temp.iloc[:topn]
plt.figure(figsize=(10,8))
sns.barplot(x='feature_importance', y='feature_names', data = fi_df)
plt.xlabel('importance')
plt.ylabel('feature names')
plt.grid()
return fi_df이제 위의 코드를 통해 변수중요도를 그릴 수 있습니다.
▶모델 생성
저는 xgb부스터로 모델을 만들겠습니다.
params = {'max_depth':range(1, 21)}
model = GridSearchCV(XGBClassifier(), params, cv = 5)
model.fit(x_train, y_train)
▶결과확인
pred = model3.predict(x_val)
print(confusion_matrix(y_val, pred ))
print(classification_report(y_val, pred ))▶변수중요도 확인
result = plot_feature_importance(model.best_estimator_.feature_importances_, list(x))해당 코드를 작성해주어 변수 중요도를 시각화해주면 아래와 같은 결과를 확인할 수 있습니다.
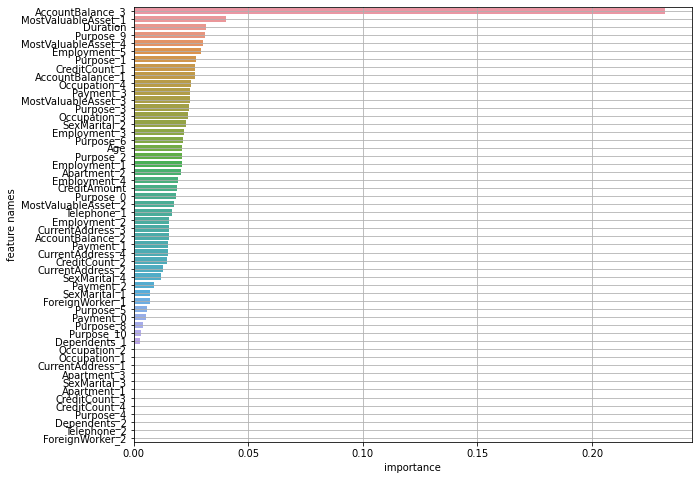
위 코드는 전체적으로 트리 알고리즘을 사용했을 때의 예시입니다. 트리 알고리즘에서는 변수중요도를 알려주는 feature_importances_를 제공해주어서 위와 같이 사용할 수 있습니다. 그럼 이제 변수중요도를 제공해주지 않는 알고리즘에 대해서는 PFI를 활용해서 변수중요도를 알아보겠습니다.
실습(트리가 아닌 알고리즘)
변수 중요도를 제공해주지 않는 SVM에 대해 실습해보겠습니다.
마찬가지로 데이터 수집과 전처리가 완료됐다는 가정하에 모델링부터 시작하겠습니다.
트리알고리즘이 아닌 알고리즘으로 모델을 만들면 변수중요도를 제공해주지 않기 때문에 함수를 하나 호출합니다.
▶함수 호출
from sklearn.inspection import permutation_importance해당 함수는 트리 알고리즘에도 사용이 가능합니다. 해당 함수는 모델에서 각 feature가 얼마나 중요한지를 계산하는데 사용되는 Scikit-learn 라이브러리의 함수입니다.
▶모델링
params = {'C':[0.1,0.5,1,2,5,10]}
model = GridSearchCV(SVC(), params, cv = 5)
model.fit(x_train_s, y_train)모델의 하이퍼파라미터까지 동시에 시작합니다.
▶변수중요도 추출
위에 호출한 함수를 통해 변수 중요도를 뽑아냅니다.
pfi = permutation_importance(model, x_val_s, y_val, n_repeats=10, scoring = 'accuracy', random_state=2022)해당 코드를 사용하고 시각화 코드를 작성해줍니다.
▶시각화 코드 작성
sorted_idx = pfi.importances_mean.argsort()
plt.figure(figsize = (10, 8))
plt.boxplot(pfi.importances[sorted_idx].T, vert=False, labels=x.columns[sorted_idx])
plt.axvline(0, color = 'r')
plt.grid()
plt.show()위와 같이 코드를 작성해주면 아래와 같은 시각화 결과를 얻을 수 있습니다.
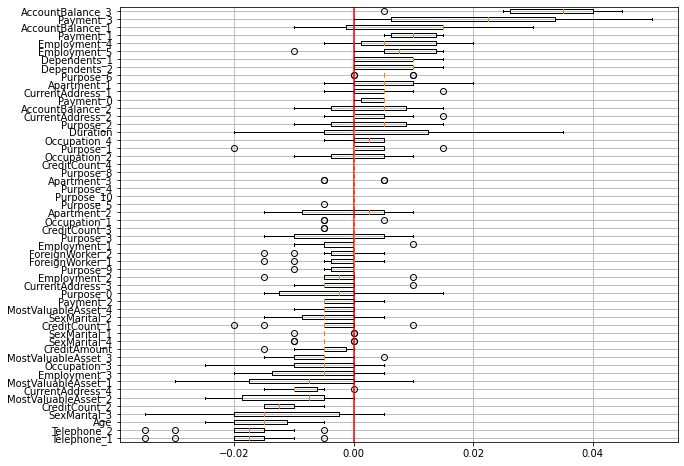
이 이외에도 여러가지 시각화하는 방법이 있습니다.
SHAP
개별 데이터(분석단위)에서 어떤 Feature의 값이 예측값에 영향을 끼친 정도를 확인하는 방법입니다. 각 변수의 중요도에 따라 타겟값이 어떻게 달라졌는지에 대해 설명하기 위해 SHAP를 사용합니다. 예를들어 대출 여부에 대해서 대출 거부가 된 고객이 왜 대출이 거부가 되었는지 알고 싶을 때 어떤 변수가 어떤 영향을 끼쳤는지에 대해 설명해 줄 수 있습니다.
각 변수들의 기여도를 계산하기 위해서는 하나의 변수를 고정해놓고 나머지 변수들로 조합을 구하는데 조합의 수는 2나머지 변수들의 수입니다.
기여도는 조합의 예측값 - (조합 - 고정된 변수)의 예측값입니다.
이런 차이값들이 나왔다면 Shaplet Value 계산식을 거치게 됩니다.
Tree 기반 알고리즘으로 한번 알아보겠습니다.
▶성능이 좋은 모델을 만듭니다.
항상 그렇지만 모델의 변수중요도나 해석에 앞서서 좋은 모델을 만드는 것은 기본 베이스 입니다.
▶explanier선언
모델의 예측 결과를 해석 가능한 형태로 변환해주기 위해서 선언합니다.
▶SHAP값을 추출
SHAP 값을 추출해줍니다.
▶그래프 그리기
마지막으로 그래프를 그려줍니다.
해당 SHAP을 사용해서 해석하기에 앞서 변수가 긍정적이 값이 나왔다는 것은 해당 변수가 높아진다고 예측값에 대한 결과를 올린다 라는 것을 의미하는 것은 아닙니다. 해석에 주의해야합니다.
위의 가정을 걸치고 나면 아래와 같은 결과값을 얻을 수 있습니다.

해당 그래프를 분석하자면 빨간색으로 표시된 변수들은 해당 분석단위(하나의 데이터)가 y(타겟값)를 갖는데 상승하는 것을 기여한 변수이고 파란색으로 표시된 변수는 반대로 하락을 기여한 변수들입니다. 이런 시각화를 통해 분석 단위 한건 한건, 변수 하나 하나에 대해 해석이 가능해집니다. 예를들어 어떤 분석단위가 평균보다 높게 나왔다면 어떤 변수가 상승 혹은 하락에 영향을 끼쳤는지 확인할 수 있습니다.
SHAP 실습코드
먼저 데이터의 수집관 전처리 x, y데이터 분리, train, val 데이터 셋이 분리되는 과정까지 모두 되었다는 가정하에 모델링부터 진행하겠습니다.
▶모델링
#필요패키지도 모두 호출했다고 가정하겠습니다.
model = RandomForestClassifier()
model.fit(x_train, y_train)
pred = model.predict(x_val)
print(confusion_matrix(y_val, pred))
print(classification_report(y_val, pred))여기서 XGboost나 LightGBM은 SHAP을 사용할려면 버전문제나 다른 코드를 작성해주어야한다고 합니다. 그리고 일단은 RandomForest로 실습코드를 진행했습니다.
▶변수중요도 계산
explainer = shap.TreeExplainer(model) # 선언
shap_values = explainer.shap_values(x_val) # shap 값 뽑기모델의 트리 구조를 기반으로 SHAP 값을 계산하는 객체를 생성하고 shap_values는 x_val에 대해서 SHAP을 구해줍니다.
▶ expect_value 구하기
explainer.expected_value해당 코드를 사용하면 예를들어 결과가 array([0.299775, 0.700225])이런식으로 나오는데 해당 결과는 첫 번째 클레스에 대한 확률이 0.299775라는 값이고 두 번째 클레스에 대한 확률이 0.700225라는 결과를 알려줍니다.
▶시각화하기
shap.initjs() # javascript 시각화 라이브러리 --> colab에서는 모든 셀에 포함시켜야 함.
idx = 74
# force_plot(전체평균, shapley_values, input)
display(shap.force_plot(explainer.expected_value[1], shap_values[1][idx, :], x_val.iloc[idx,:]))
display(x_val.iloc[idx:idx+1,:])이 코드를 보게되면 explainer.expected_value[1]라고 사용을 해줬는데 이를 사용해준 이유는 배열로 결과값이 나오기 때문에 이진 분류일 경우 0혹은 1에대한 확률이 나옵니다. 만약 해당 단위 변수에서 1에대한 예측값에 대한 기대값을 알기 위해 explainer.expected_value[1]을 사용해주었습니다. 예를들어 왜 대출이 허용이 됬는지 알고 싶을 때 explainer.expected_value[1]을 사용해주어 해당 확률에 대한 변수들의 기여도를 확인할 수 있습니다.

이런식으로 각 변수의 기여도를 시각화를 통해 알 수 있습니다.
모델 설명에 대한 순서
모델 설명에 있어 순서에 대해 정리를 한번해보자면
1. 모델을 최적화 해준 후의 최고의 성능을 갖춘 모델을 만들어야합니다
성능이 낮은 모델에 있어서 설명하는 것은 잘못되었습니다. 왜냐하면 애초에 답이 잘모되었는데 그거에 대해 설명하는 것은 의미가 없습니다.
2. 설명을 위해 시각화와 분석을 진행합니다.
최상의 모델을 만들었다면 해당 모델의 변수중요도를 시각화하여 어떤 변수가 해당 모델을 만드는데 큰 영향을 끼쳤는지 분석을 하고 설명을 할 수 있어야 합니다.
3. 고객에게 설명할 수 있어야합니다.
분석단위 하나 하나에 대해 변수 기여도를 시각화 하여 분석을 한 후에 설명을 할 수 있어야됩니다. 예를들어 대출이 반려되었다면 어떤 하강 변수의 영향이 컸는지에 대해 분석하고 고객한테 설명할 수 있어야합니다.
기대가치 평가
모델을 만들었을 때 해당 모델을 비용으로 평가하는 것입니다. 분류모델에 있어서 기대가치 평가하는 방법에 대해서 알아보겠습니다.
▶방법
예측값에 대해서 해당 혼동행렬을 비율로 바꾸어줍니다. 그럼 비율로 바꾼 혼동행렬과 예측값의 혼동행렬이 있을 것입니다. 그 두개의 혼동행렬을 곱한 후에 모든 요소의 값을 더해준 것이 1인당의 기대 수익입니다.
추가적인 이론
▶Partial Dependence Plot(PDP)
변수의 영향을 y(타겟값)에 대한 평균적인 영향력으로 나타내는 시각화 방법입니다.
▶수요량 예측 평가
수요량 혹은 판매량을 예측하는 회귀 모델이라면 시뮬레이션을 돌려서 재고회전률을 평가합니다.
변수중요도와 해당 변수들이 결과에 미치는 기여도에 대해 알아보았습니다. 고객에게 설명하기 위해서 변수를 분석하고 설명하는 것이 중요하다고 생각하게 되었습니다.
※공부하고 있어 다소 틀린점이 있을 수 있습니다. 언제든지 말해주시면 수정하도록 하겠습니다.
※용어에 대해 조금 공부 더 해서 수정하겠습니다.
