크롤링 2일차-SELECTOR을 이용해서 정적 페이지 크롤링과 셀레니움에 대해 배웠습니다.
복습
동적페이지는 URL변경 없이 데이터가 수정되는 페이지를 말합니다. 동적페이지에서 데이터를 수집하면 JSON 데이터타입으로 데이터를 수집합니다. 그러면 이제 수집한 데이터를 request.json()을 사용합니다.
정적페이지는 URL 변경을 통해 데이터 수정이 일어나 보고 있는 페이지가 변경됩니다. 정적페이지에서 데이터를 수집하면 HTML 형태로 데이터를 수집합니다. HTML의 데이터는 BeautifulSoup을 사용해서 데이터 파싱을 합니다. 파싱 순서는 HTML -> CSS Selector -> DataFrame 순서로 변환합니다.
SELENIUM은 웹 브라우저를 파이썬으로 컨트롤해서 데이터를 수집하는 방법입니다.
※스페셜 커맨드는 %를 앞에 붙여서 사용하는 커멘드로 쥬피터 노트북에서 제공하는 커맨드입니다.
%ls를 하게 되면 현재 디렉터리 안의 파일들을 확인할 수 있습니다.
※#쉘 커멘드로 OS System에서 제공하는 커맨드입니다.
가짜 기사를 만드는 방법
네이버 뉴스 페이지에서 개발자 모드에서
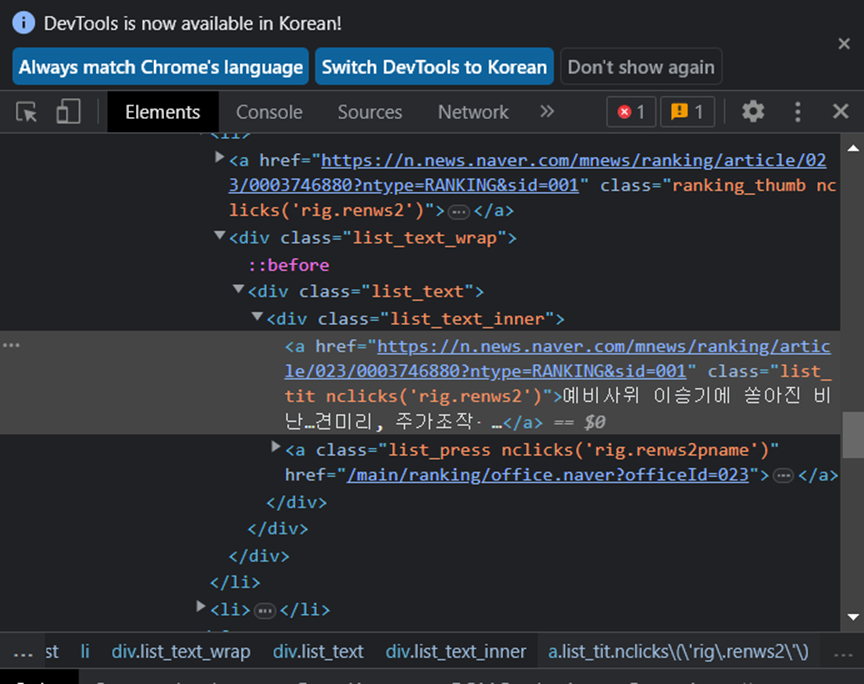
Elements텝을 누르고 왼쪽 위 마우스 모양을 클릭 후 바꾸고 싶은 기사 제목 부분을 누르게 되면 위 사진처럼 해당 기사 제목이 보입니다. 해당부분을 아래의 사진처럼 원하는 제목으로 바꾸게 되면
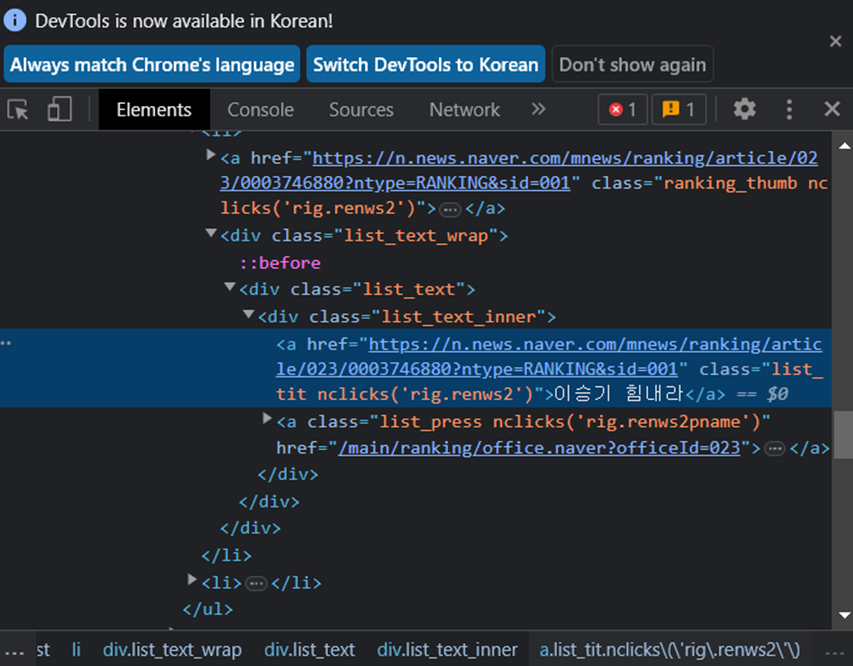
아래의 사진처럼 기사의 제목이 바뀌게 됩니다.

하지만 다른 사라들이 볼 수는 없습니다.
HTML
▶document는 한 페이지를 나타내는 단위입니다.
▶element는 시작태그와 끝태그로 구성되어 있습니다.
▶tah는 element의 종류를 정의해줍니다.
▶웹 페이지의 구성요소는 HTML(레이아웃, 문자열), JS(이벤트), CSS(스타일)로 구성합니다.
쥬피터 환경에서 HTML 문법을 사용해서 확인할 수 있습니다.
%%html
<div class = 'wrapper'>
<button class = 'btn no1' value = '1'> HTML1 </button>
<button class = 'btn no1' value = '2'> HTML2 </button>
</div>%%html을 사용하면 쥬피터 내에서도 HTML을 사용할 수 있습니다.

HTML의 정리는 전에 작성했던 블로그 링크를 걸어두겠습니다.
HTML정리1 - https://ggoalbeom97.tistory.com/2
HTML정리2 - https://ggoalbeom97.tistory.com/4
SELECTOR
선택자에 대해 알아보겠습니다. selector을 통해 원하는 태그에 접근해서 스타일을 바꾸던가 다른 작업이 가능합니다.
▶id를 기준으로 선택을 할려면 #태그id명을 사용하면 해당 id명을 가진 태그들을 선택해서 스타일을 바꿔줄 수 있습니다.
▶class를 기준으로 선택할려면 .태그class명을 사용하면 해당 class명을 가진 태그들을 선택해서 스타일을 바꿔줄 수 있습니다.
▶not slector방법은 .셀렉터:not제거하고싶은셀렉터를 사용해주면 전체 셀렉터중에 제거하고 싶은 셀렉터를 작성해서 해당 셀렉터들은 제외해줄 수 있습니다.
▶부모태그에서 하위태그로 내려가는 방법으로는 부모 태그 클레스에서 > .자식 클레스명을 사용해주면 부모 태그를 먼저 선택하고 해당 부모 태그 안에 있는 자식 태그를 최종적으로 셀렉트하게 됩니다.
정적페이지 크롤링
크롤링 첫날에는 동적 페이지 크롤링에 대해서 공부하였고 둘쨋 날에는 정적 페이지 크롤링에 대해 공부했습니다.
정적페이지 크롤링은 동적페이지 크롤링과 다르게 html태그를 선택해서 데이터를 가져옵니다.
나머지 방식은 동적 페이지 크롤링과 똑같이 웹 페이지 분석을 통해 URL을 찾습니다.
다음으로 request(url)을 통해 데이터를 받아옵니다. 이때 동적페이지와의 차이점은 html 코드 형식의 데이터를 받아옵니다.
이제 받아온 데이터를 데이터 파싱을 통해 DataFrame형태로 바꿀 예정인데 json파일 형태가 아니기 때문에 BeautifulSoup를 사용해줍니다. 먼저 사용에 앞서 아래와 같이 필요 패키지를 import합니다.
from bs4 import BeautifulSoupresponse가져온 데이터를 bs object형태로 바꾸는 방법은 아래와 같습니다.
data = BeautifulSoup(response.text, 'html.parser')
type(data)위와 같이 데이터 타입을 확인하면 bs4.BeautifulSoup가 출력됩니다.
bs object를 selector를 통해 원하는 태그를 선택하는 방법은 select(셀렉터)를 사용해주면 원하는 엘리먼트를 가져올 수 있습니다. select()를 사용하면 여러개의 엘리먼트를 선택할 수 있고 select_one()사용하면 한개의 엘리먼트만 선택합니다. 선택자를 가져오는 방법은 아래처럼 개발자 도구를 통해 가져올 수 있습니다.

이제 가져온 데이터를 pd.DataFrame()을 통해 데이터프레임 형태로 바꿔줄 수 있습니다.
셀레니움 사용
환경설정
from selenium import webdriver
from selenium.webdriver.common.by import By셀레니움을 사용하기 위해서는 본인 번전에 맞는 크롬 브라우저 드라이버를 다운 받을 필요가 있습니다.
driver = webdriver.Chrome()이제 driver을 통해 크롬 브라우저를 제어할 수 있습니다.
이제 위 코드를 실행했으면 셀레니움으로 제어가 가능한 창이 열렸을 것입니다. 그러면 해당 창을 원하는 사이트로 이동시키는 방법은 아래와 같습니다.
driver.get('https://daum.net')위와 같이 작성해주면 다음사이트로 이동이 가능합니다.
셀레니움도 마찬가지로 Selector를 통해 원하는 엘레멘트를 선택해서 제어할 수 있습니다.
예를들어 다음 사이트의 검색창에 파이썬을 입력하고 싶다면 아래와 같이 작성해주면 됩니다.
driver.find_element(By.CSS_SELECTOR, '#q').send_keys('파이썬')
그러면 보시는 거와 같이 파이썬을 자동으로 입력해줍니다.
입력뿐만 아니라 클릭도 가능합니다. 돋보기 모양의 selector를 가져와준 다음 아래와 같이 작성해주면 검색 버튼을 눌러줍니다.
selector = '.inner_search > .ico_pctop.btn_search'
driver.find_element(By.CSS_SELECTOR, selector).click()
이처럼 셀레니움을 통해 웹사이트를 제어하여 원하는 데이터들을 수집할 수도 있습니다.
추가
정규표현식
import re
price = '할인가 11,800원'
re.findall('[0-9,]+', price)[0]0-9까지의 숫자와 ,가 있으면 선택을 합니다. 결과는 11800이 출력됩니다.
웹 크롤링에 대해서 배웠는데 데이터를 가져오는 것은 이해가 되지만 해당 데이터를 파싱해서 데이터프레임으로 바꾸는 연습은 필요할 것 같습니다.
※공부하고 있어 다소 틀린점이 있을 수 있습니다. 언제든지 말해주시면 수정하도록 하겠습니다.
※용어에 대해 조금 공부 더 해서 수정하겠습니다.
