오늘은 CNN 미니프로젝트가 시작되는 날입니다.
문제 정의
이번 프로젝트의 문제는 차량 대여 회사에서 소비자가 차량을 반납했을 때 차량의 사진을 찍어서 제출해주는데 해당 차량에 사고가 있었는지 없었는지를 파악해주는 시각딥러닝을 만들어주는 것을 목표로 프로젝트를 시작했습니다.
주어진 데이터를 보면 normal과 abnormal이 있습니. normal은 정상적인 자동차의 사진이고 abnormal은 흠집 혹은 사고가 있는 자동차의 사진입니다. 따라서 해당 데이터를 가지고 이진분류를 통해 사고가 있는 사진인지 아닌지를 분류해주는 ML을 만들도록 하는 것이 목표입니다.
환경설정
먼저 프로젝트의 작업환경은 코랩으로 진행했습니다. 그리고 구글 드라이브에 데이터셋을 저장하고 사용하기 위해서 코랩과 드라이브를 먼저 연동하겠습니다.
▶코랩과 드라이브 연동
from google.colab import drive
drive.mount('/content/drive')다음으로는 데이터 셋을 불러오도록 하겠습니다. 저는 제공 받은 파일을 먼저 압축을 해제하고 드라이브에 넣어서 압축 해제를 코랩에서 진행해주지는 않았습니다. 그래도 데이터셋 경로를 편하게 사용하기 위해서 변수로 지정했습니다.
▶데이터셋 변수 설정
dataset_path = '/content/drive/MyDrive/경로/Car_Images'그래도 나중에 압축 해제 코드를 찾아볼 수 있기 때문에 포스팅에 남겨두겠습니다.
▶압축 해제하기
# 압축 해제
# 압축 파일 경로 설정
zip_file_path = '/content/drive/MyDrive/Datasets/Car_Images.zip'
# 압축 해제할 디렉토리 경로 설정
extract_path = '/content/drive/MyDrive/Datasets/Car_images_train/'
# 압축 해제
!unzip {zip_file_path} -d {extract_path}예를들어 드라이브에 바로 Datasets라는 폴더에 Car_Images.zip있다면 해당 파일을 Datasets/Car_images_train/ 경로에 압축 해제하라는 의미입니다.
▶이미지 관리를 위한 파일 생성
이미지를 이제 관리해주기 위해 각 데이터셋 별로 파일을 만들어주기 위해 폴더를 생성하겠습니다.
import os
# train 폴더는 압축을 해제하면서 이미 생성 되어 있습니다.
# test 폴더 만들기 os.mkdir()
os.mkdir('/content/drive/MyDrive/경로/Car_Images/test_normal')
os.mkdir('/content/drive/MyDrive/경로/Car_Images/test_abnormal')
# validation 폴더 만들기
os.mkdir('/content/drive/MyDrive/경로/Car_Images/val_normal')
os.mkdir('/content/drive/MyDrive/경로/Car_Images/val_abnormal')os 패키지를 이용해서 각 train, test, val 데이터셋 폴더를 만들어주었습니다. train 데이터셋은 이미 압축해제했을 때 생성되었기 때문에 생략했습니다.
전처리
이제 앞선 환경설정이 끝났으면 전처리를 시작해줍니다.
▶데이트 셋 별로 나누어주기
해당 프로젝트는 하나의 train데이터 셋으로부터 test와 val 데이터 셋을 나누어주어야합니다. 따라서 train 데이터 셋으로부터 랜덤하게 나누어주도록 하겠습니다.
먼저 test 데이터 셋을 추출하겠습니다.
import random
import shutil
tr_n_path = '/content/drive/MyDrive/경로/Car_Images/normal'
te_n_path = '/content/drive/MyDrive/경로/Car_Images/test_normal'
# 디렉토리 내 파일 리스트 생성
file_list = os.listdir(tr_n_path)
# 파일 리스트를 무작위로 섞음
random.shuffle(file_list)
# 이동할 파일 개수 계산
num_files = int(len(file_list) * 0.2)
# 파일 이동
for i in range(num_files):
src_path = os.path.join(tr_n_path, file_list[i])
dst_path = os.path.join(te_n_path, file_list[i])
shutil.move(src_path, dst_path)먼저 정상적인 자동차 사진이 있는 train normal폴더에서 test_normal폴더를 새로 만들어서 해당 파일로 옮기는 작업입니다.
코드를 살펴보면 file_list라는 변수에 os.listdir함수를 통해 train데이터셋의 normal폴더의 파일드를 리스트화해주는 작업물을 저장합니다.
다음으로 file_list를 랜덤으로 random.shuffle()을 통해 무작위로 섞어줍니다.
그리고 나서 이제 train 데이터 셋에서 총 20%를 test 데이터 셋으로 사용할 것이기 때문에 파일의 수를 계산 해주는 코드를 작성합니다.
마지막으로 파일이동을 위한 코드를 작성해줍니다. 반복문을 통해 위에 설정해준 옮기고자하는 수만큼 반복을 진행하는데 os.path.join(tr_n_path, file_list[i])는 랜덤으로 섞인 파일의 명과 경로를 합쳐주어 원본 파일의 경로를 src_path에 저장해주고 옮기고자하는 위치의 경로와 파일명을 dst_path에 저장해주고 마지막으로 shutil.move(src_path, dst_path)코드를 통해 옮겨줍니다.
tr_ab_path = '/content/drive/MyDrive/경로/Car_Images/abnormal'
te_ab_path = '/content/drive/MyDrive/경로/Car_Images/test_abnormal'
# 디렉토리 내 파일 리스트 생성
file_list = os.listdir(tr_ab_path)
# 파일 리스트를 무작위로 섞음
random.shuffle(file_list)
# 이동할 파일 개수 계산
num_files = int(len(file_list) * 0.2)
# 파일 이동
for i in range(num_files):
src_path = os.path.join(tr_ab_path, file_list[i])
dst_path = os.path.join(te_ab_path, file_list[i])
shutil.move(src_path, dst_path)
이번에는 abnormal파일을 옮겨주는 작업을 진행해줍니다. 위와 코드 내용은 같습니다.
마지막으로 잘 이동이 되었는지 확인해줍니다.
te_n_path = '/content/drive/MyDrive/경로/Car_Images/test_normal'
te_ab_path = '/content/drive/MyDrive/경로/Car_Images/test_abnormal'
num_normal_images = len(os.listdir(te_n_path))
num_abnormal_images = len(os.listdir(te_ab_path))
print(f"파일 내 이미지 수: {num_normal_images}")
print(f"파일 내 이미지 수: {num_abnormal_images}")몇 개의 사진이 이동되었는지 알 수 있습니다.
val 데이터 셋도 위와 같은 방식으로 train으로부터 파일을 옮겨주면 됩니다.(코드는 생략하겠습니다.)
▶데이터 복사하기
지금까지 만들어준 폴더들을 폴더를 하나 생성 후 해당 폴더로 복사해주겠습니다.
os.mkdir('/content/drive/MyDrive/경로/Car_Images/copy_images')copy_images폴더를 새로 만들어주고 해당 폴더로 옮겨주는 작업을 진행하겠습니다.
먼저 그냥 옮기기만 하는 것이 아니라 abnormal 이미지는 ab_라는 접두어를 붙여서 옮겨주도록 하겠습니다.
# 복사할 데이터 경로
src_dir = "/content/drive/MyDrive/경로/Car_Images/abnormal"
# 복사할 데이터를 저장할 새로운 경로
dst_dir = "/content/drive/MyDrive/경로/Car_Images/copy_images/trainset"
# src_dir 디렉토리에 있는 파일 목록 가져오기
files = os.listdir(src_dir)
# 파일을 dst_dir에 복사하기
for file in files:
# 파일 경로 지정
src_file = os.path.join(src_dir, file)
# 새로운 파일명 생성
if file.startswith('ab_'):
dst_file = os.path.join(dst_dir, file)
else:
dst_file = os.path.join(dst_dir, 'ab_' + file)
# 파일 복사
shutil.copy2(src_file, dst_file)해당 코드는 위에 작성한 코드와 전체적인 구조는 비슷한데 조건과 복사이기 때문에 세부적인 코드가 다릅니다. 먼저 ab_ 라는 접두사를 붙이기 위해서 if file.startswith('ab_'): 조건을 걸어주어서 만약 ab로 시작한다면 바로 파일명을 가져와주고 아니라면 ab라는 접두사를 붙여 최종경로와 파일명을 완성시킨 변수를 가지고 shutil.copy2(src_file, dst_file)를 사용해서 복사를 해줍니다.
일반 normal 이미지 파일을 복사하는 코드는 아래와 같습니다.
# 복사할 데이터 경로
src_dir = "/content/drive/MyDrive/경로/Car_Images/normal"
# 복사할 데이터를 저장할 새로운 경로
dst_dir = "/content/drive/MyDrive/경로/Car_Images/copy_images/trainset"
for file_name in os.listdir(src_dir):
src_file = os.path.join(src_dir, file_name)
dst_file = os.path.join(dst_dir, file_name)
shutil.copy(src_file, dst_file)normal파일은 파일명을 따로 변경해줄 필요 없기 때문에 반복문과 os.listdir(src_dir)을 통해서 원본 경로에 있는 이미지파일들의 이름을 리스트화 해주고 파일명 하나하나를 가지고 복사를 해주면 됩니다.
모델링
원래 목표는 전처리까지였지만 모델링 하나를 만들었어서 모델링 하나만 예시로 같이 작성하겠습니다.
최종적으로 이제 전처리까지 완료가 되었지만 모델링에 앞서서 x와 y에 대해서 데이터 구조를 변환해주어야 합니다.
▶x에 대한 구조 변환
먼저 이미지 파일이름에 대한 리스트를 만들어줍니다.
# 이미지 목록 저장
img_train_list = os.listdir(dataset_path+'copy_images/trainset/')
img_valid_list = os.listdir(dataset_path+'copy_images/validset/')
img_test_list = os.listdir(dataset_path+'copy_images/testset/')먼저 각 데이터셋의 파일들의 이름을 img_... 변수에 각각 저장해 줍니다.
이제 x에 대한 요구사항에 맞게 작업을 진행해줍니다. 이미지 크기는 280*280*3으로 설정해줍니다.
from tensorflow.keras.preprocessing.image import load_img, img_to_array
import numpy as np
# 메모리, 처리시간을 위해서 이미지 크기 조정
img_size = 280
# Training set
x_train = []
for img_file in img_train_list:
img = load_img(dataset_path+'copy_images/trainset/'+img_file, target_size=(img_size, img_size))
img_array = img_to_array(img)
x_train.append(img_array)
x_train = np.array(x_train)
# Validation set
x_val = []
for img_file in img_valid_list:
img = load_img(dataset_path+'copy_images/validset/'+img_file, target_size=(img_size, img_size))
img_array = img_to_array(img)
x_val.append(img_array)
x_val = np.array(x_val)
# Test set
x_test = []
for img_file in img_test_list:
img = load_img(dataset_path+'copy_images/testset/'+img_file, target_size=(img_size, img_size))
img_array = img_to_array(img)
x_test.append(img_array)
x_test = np.array(x_test)해당 코드를 보게되면 각 데이터 셋 별로 np.array로 만들어주는 작업입니다. 먼저 파일의 이름을 불러오고 load_img()함수를 통해 경로에 있는 파일을 다운받아줍니다. 받을 때 target_size 옵션을 이용해서 앞서 x데이터의 조건이였던 280*280을 맞춰줍니다.
다음으로 이제 img_to_array()함수를 이용해서 3차원 배열로 만들저 줍니다.
그리고 나서 x_train에 작업한 img를 추가해준 후에 모든 반복을 진행하고 최종적으로 x_train을 4차원 배열로 변환해주게 되면 x에 대한 구조 변경이 끝나게 됩니다.
▶x에 대한 구조 확인
x에 대한 구조 변경이 끝났으면 아래 코드를 통해 결과를 확인합니다.
print("x_train shape:", x_train.shape)
print("x_valid shape:", x_val.shape)
print("x_test shape:", x_test.shape)▶y에 대한 라벨링
이진분류 모델이기 때문에 abnormal 이미지는 1로 라벨링 normal 이미지는 0으로 라벨링을 해줍니다.
# Training set
y_train = []
for img_file in img_train_list:
if img_file.startswith('ab_'):
y_train.append(1) # abnormal 이미지는 1로 라벨링
else:
y_train.append(0) # normal 이미지는 0으로 라벨링
y_train = np.array(y_train)
# Validation set
y_val = []
for img_file in img_valid_list:
if img_file.startswith('ab_'):
y_val.append(1)
else:
y_val.append(0)
y_val = np.array(y_val)
# Test set
y_test = []
for img_file in img_test_list:
if img_file.startswith('ab_'):
y_test.append(1)
else:
y_test.append(0)
y_test = np.array(y_test)▶y reshape
라벨링이 끝나면 바로 reshape를 해주어 구조를 맞춰줍니다.
y_train = y_train.reshape(-1, 1)
y_val = y_val.reshape(-1, 1)
y_test = y_test.reshape(-1, 1)모델링
이제 진짜 모든 사전 준비가 끝났으므로 모델링 작업을 시작합니다.
▶필요패키지 호출
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.callbacks import EarlyStopping
from tensorflow.keras.preprocessing import image
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.layers import GlobalAveragePooling2D, Dense
from sklearn.model_selection import train_test_split
import random
import numpy as np
import matplotlib.pyplot as plt 모델링에 필요한 패키지들을 호출합니다.
▶모델선언
keras.backend.clear_session()
model = keras.models.Sequential()
model.add(keras.layers.Input(shape=(280,280,3)))
model.add(keras.layers.Conv2D(filters=32, kernel_size=(3,3), padding='same', activation='relu'))
model.add(keras.layers.BatchNormalization())
model.add(keras.layers.Conv2D(filters=32, kernel_size=(3,3), padding='same', activation='relu'))
model.add(keras.layers.BatchNormalization())
model.add(keras.layers.MaxPool2D(pool_size=(2,2)))
model.add(keras.layers.Dropout(0.25))
model.add(keras.layers.Conv2D(filters=64, kernel_size=(3,3), padding='same', activation='relu'))
model.add(keras.layers.BatchNormalization())
model.add(keras.layers.Conv2D(filters=64, kernel_size=(3,3), padding='same', activation='relu'))
model.add(keras.layers.BatchNormalization())
model.add(keras.layers.MaxPool2D(pool_size=(2,2)))
model.add(keras.layers.Dropout(0.25))
model.add(keras.layers.Flatten())
model.add(keras.layers.Dense(512, activation='relu'))
model.add(keras.layers.BatchNormalization())
model.add(keras.layers.Dense(1, activation='sigmoid'))
model.compile(loss = keras.losses.binary_crossentropy, metrics=['accuracy'], optimizer='adam')
model.summary()저는 Sequential모델로 CNN을 만들었습니다.
▶모델학습(w.EalySttoping)
from keras.callbacks import EarlyStopping
es = EarlyStopping(monitor='val_loss', patience=5, min_delta=0, verbose=1, restore_best_weights=True)EarlyStopping을 선언해주고 이제 진짜로 학습을 시작합니다.
model.fit(x_train, y_train, callbacks=[es], verbose=1, validation_data=(x_val, y_val), epochs=1000)▶모델평가
이제 마지막으로 모델평가를 진행하면 아래와 같은 결과를 얻었습니다.
from sklearn.metrics import confusion_matrix
from sklearn.metrics import classification_report
y_pred = model.predict(x_test)
y_pred = np.round(y_pred).astype(int)
cm = confusion_matrix(y_test, y_pred)
print(cm)
cr = classification_report(y_test, y_pred)
print(cr)
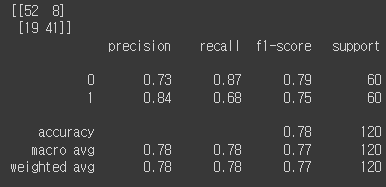
from sklearn.metrics import accuracy_score
test_acc = accuracy_score(y_test, y_pred)
print(f'테스트셋 정확도 : {test_acc*100:.2f}%' )
이상으로 시각지능_딥러닝 미니프로젝트 1일차 진행현황을 포스팅했습니다.
처음에 미니프로젝트를 받고 많이 당황해서 구글링과 GPT에게 물어보느라 시간 절반을 보낸거 같습니다. 막상 또 정리해보니 다음에 할 수 있을꺼 같기도하고 오묘한 생각이 많이들었습니다. 일단 빨리 더 복습하면서 익숙해져야겠습니다.
※공부하고 있어 다소 틀린점이 있을 수 있습니다. 언제든지 말해주시면 수정하도록 하겠습니다.
※용어에 대해 조금 공부 더 해서 수정하겠습니다.
