Motion Generation 논문 리뷰
1.[논문] StableMoFusion: Towards Robust and Efficient Diffusion-based Motion Generation Framework
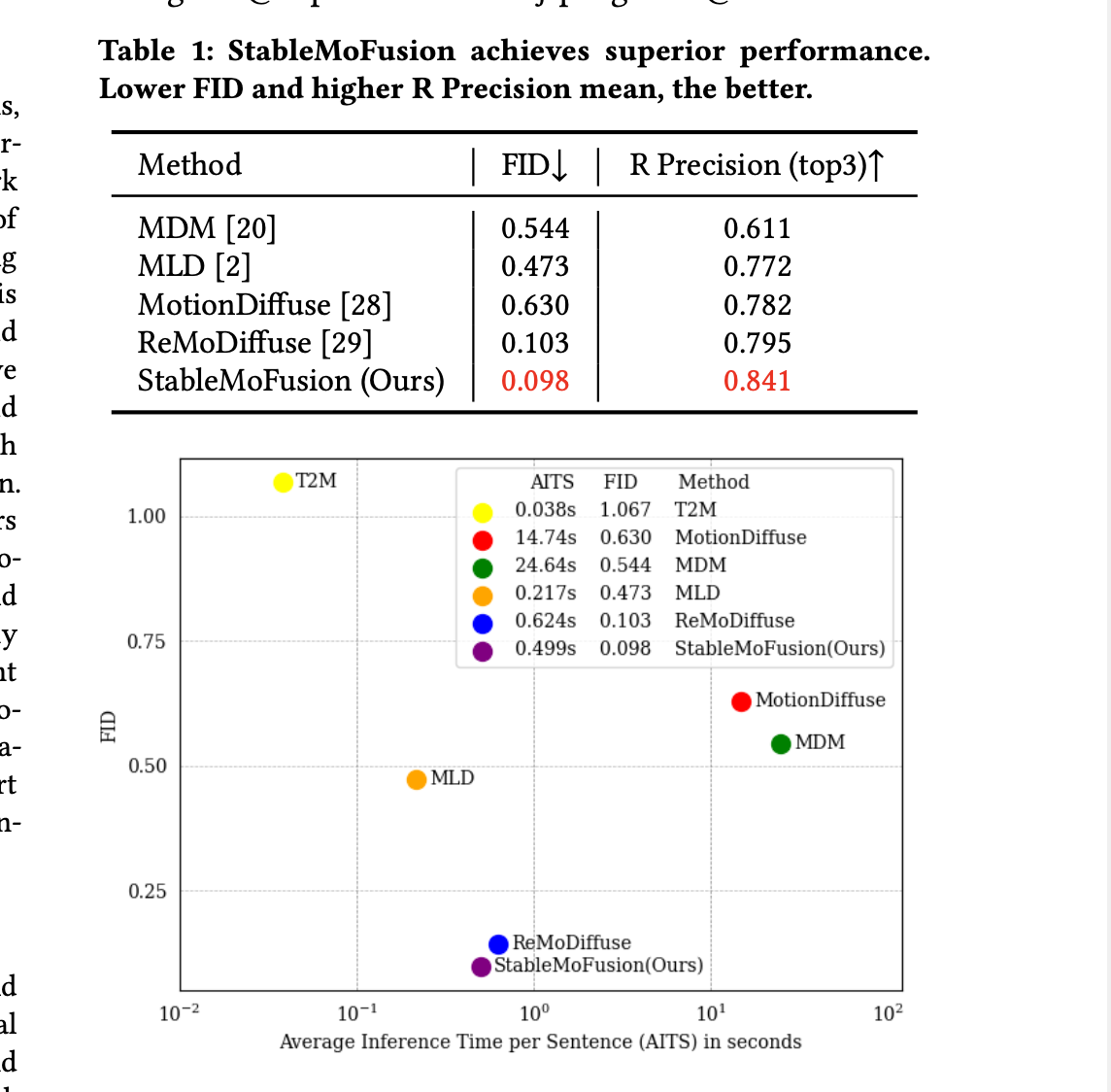
Introduction diffusion을 이용한 text-to-motion 연구들이 나왔지만, 아래와 같은 문제들이 아쉬움이 있다고 합니다. 체계적인 분석 부족: 서로 다른 모델 구조와 학습 파이프라인으로 인한 다양한 방법 통합 불가 긴 추론 시간: 반복적인 샘플링으
2.[논문] MMM: Generative Masked Motion Model
이전 논문에서 Mask를 사용하는 tranformer를 사용하여 퀄리티를 높이는 text-to-motion 연구를 봤었는데요. 그 논문보다 성능이 좋지는 못하지만 굉장히 유사한 방법을 사용했길래 살펴보게되었습니다. 이전 논문이 정말 세심한 기법들을 사용해서 그런지 이
3.[논문] MoMask: Generative Masked Modeling of 3D Human Motions
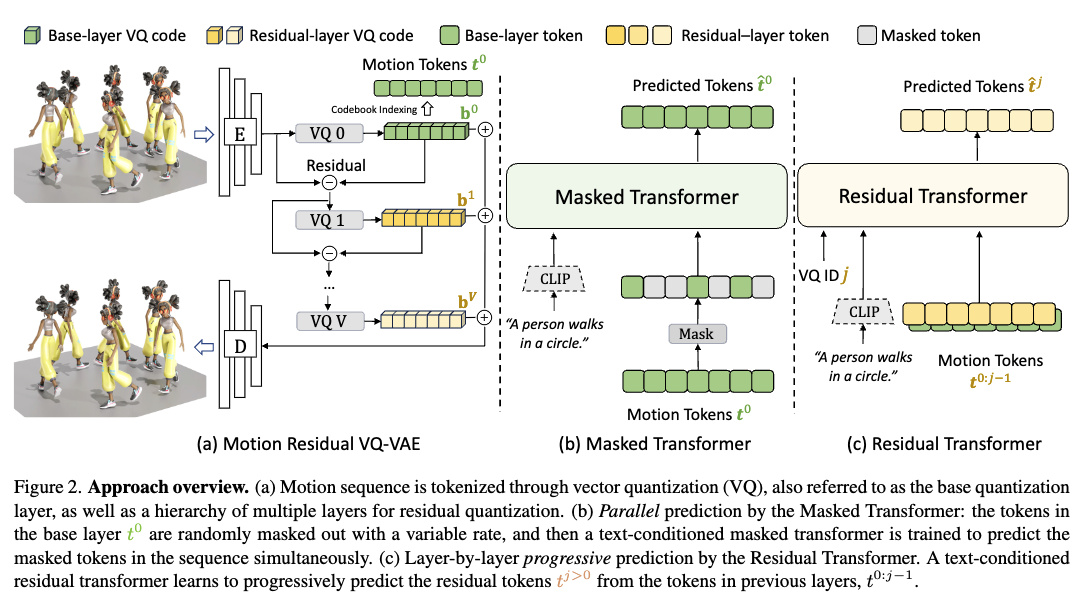
Text-to-Motion 분야로 많은 가능성이 제기됐지만, 여전히 아쉬운 부분들이 많이 있죠. 요청하고자하는 text가 너무 길거나 복잡하면 디테일함이 빠지거나 잘 만들어지지 않는 것들을 많이 보셨을 수 도 있을거에요. 이번 논문에서는 그런 문제가 token을 만들
4.[논문] MDM, Motion Diffusion Model

모션 생성은 many-to-many 매핑 문제로 봐야합니다. 논문의 예를 인용하자면, "kick"은 축구의 발차기를 의미할 수도 있지만, 카라테의 발차기가 될 수 도 있기 때문이죠(위 그림 참조). 하지만, text-to-motion 연구들의 대부분은 Auto-Enco
5.[논문] MotionGPT: Human Motion as a Foreign Language

LLM은 방대한 양의 데이터를 사용하여, 포괄적인 언어 표현에 대해 학습하고, 이를 통해서 번역, 요약, 질의 응답과 같은 다양한 작업을 수행합니다. 다른 연구들은 이 LLM을 활용해서 vision, audio, robotics 영역에도 활용하고 있고, 저자들은 모션
6.[논문] UniMotion: Unifying 3D Human Motion Synthesis and Understanding
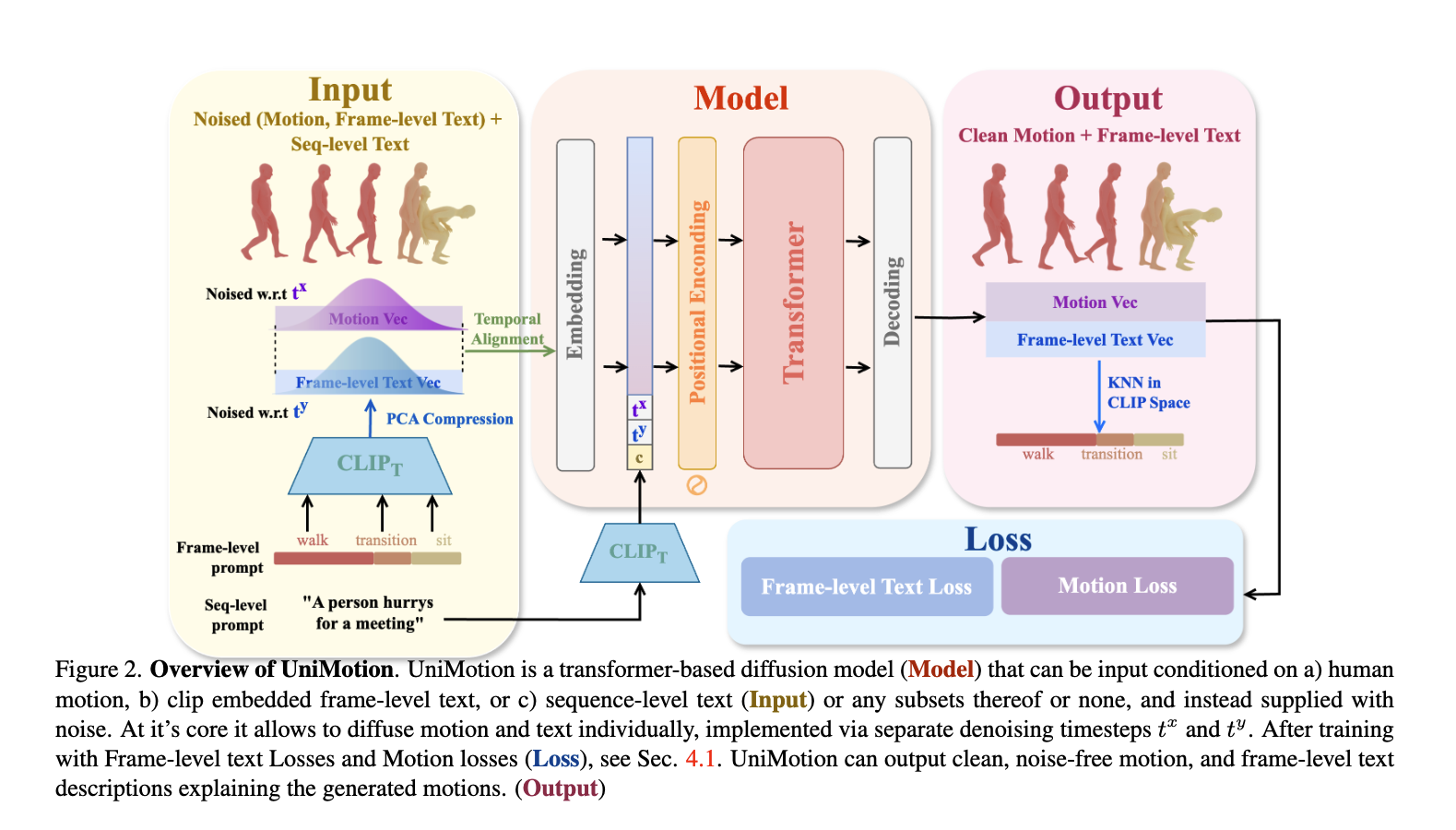
재가 좋아하는 Real Virtual Human 연구소에서 새로운 UniMotion 논문을 발표했습니다. 이미 많은 분야에서 사용하고 있는 Diffusion모델을 Motion쪽에도 적용하였습니다. 물론, 벌써부터 Text to Motion은 많이 연구되어오긴했는데, 아
7.[논문] OmniMotionGPT: Animal Motion Generation with Limited Data
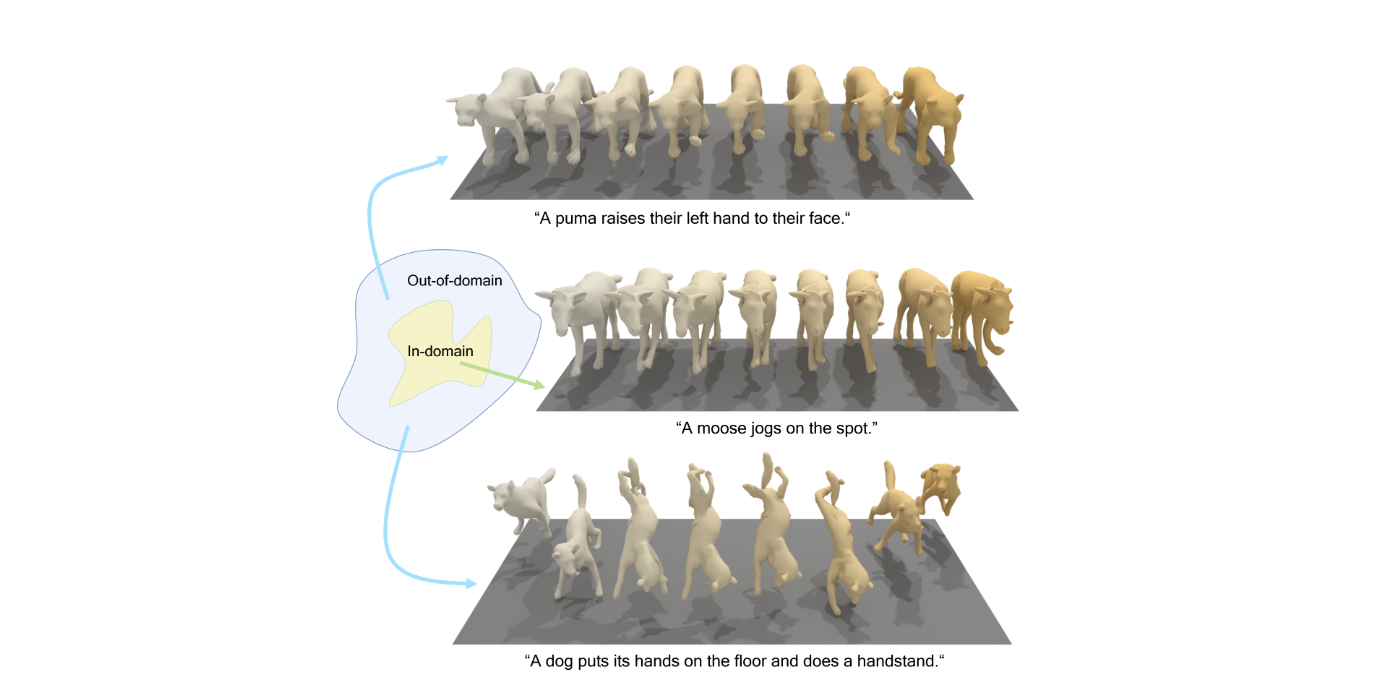
Introduction 우선, 동물의 모션을 생성하는데에는 다음과 같은 문제들이 있다는 것을 지적합니다. 데이터 부족 인간과의 관절 수 및 정의 다름 동물 종류에 따른 골격 상이 동물의 현실적 모션과 우리가 생각하는 모션은 다름 강아지가 박수치는 것을 상상할 수 는
8.[논문] ReMoDiffuse: Retrieval-Augmented Motion Diffusion Model
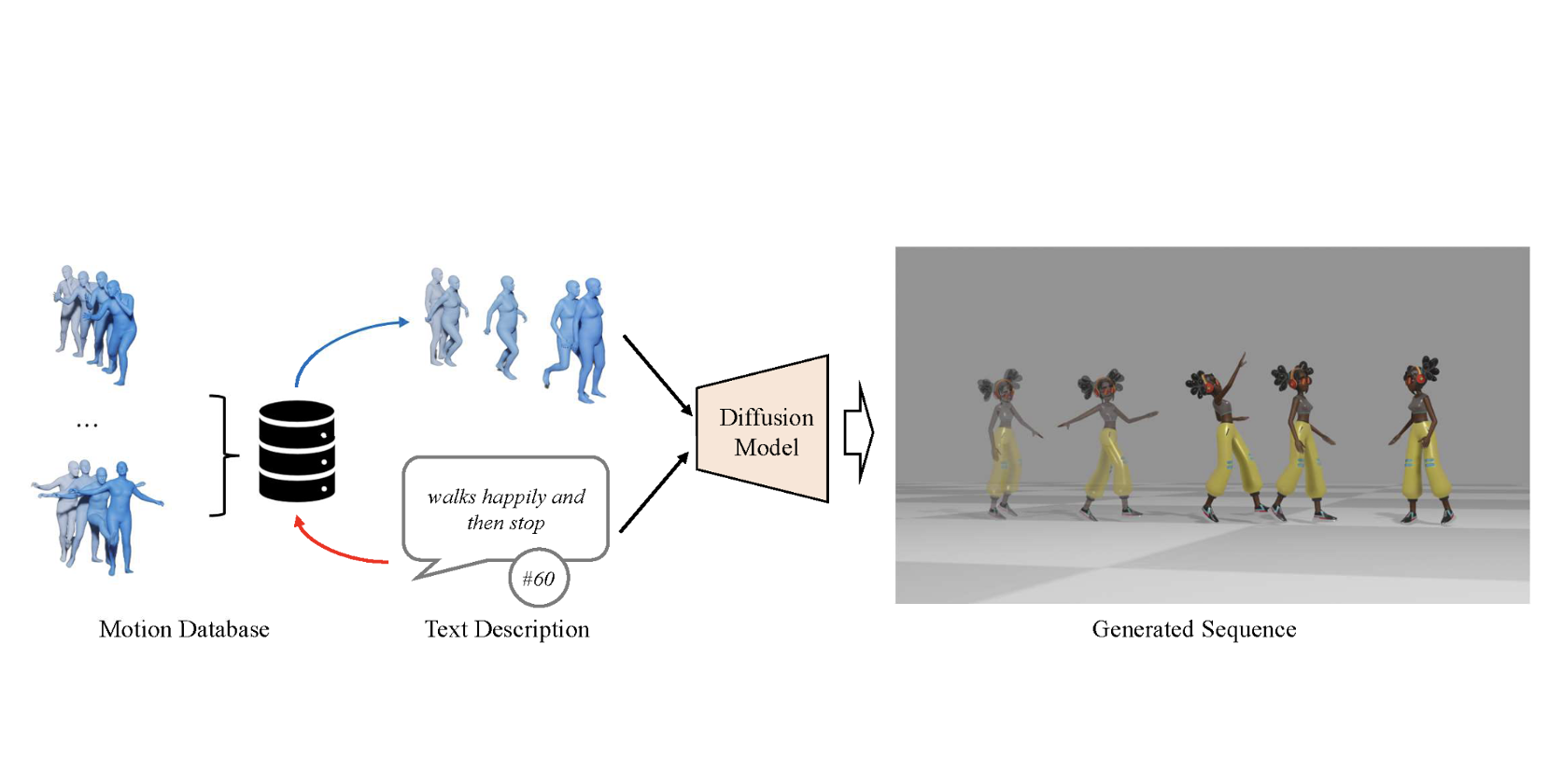
이번 논문은 많은 연구들에서 비교 대상으로 사용되는 ReMoDiffuse입니다. 그만큼 연구된 방법들이 타당하고 결과가 뛰어나다는 것이겠죠? 이 ReMoDiffuse에서 가장 인상적인 부분은 검색된 결과를 다시한번 활용한다는 것입니다. 연구를 하다보면 좋은 결과를 위해
9.Motion Generation Metrics(모션 생성 정량 평가 지표)

Motion Generation 분야에는 FID, R-Precision, MM-Dist, MModality, Diversity와 간튼 5개의 Metric을 많이 사용합니다. 특히, 연구분야에서는 이렇게 통일된 정량적 지표가 있어야 서로의 연구를 객관적으로 평가할 수 있
10.[논문] MotionDiffuse: Text-Driven Human Motion Generation with Diffusion Model
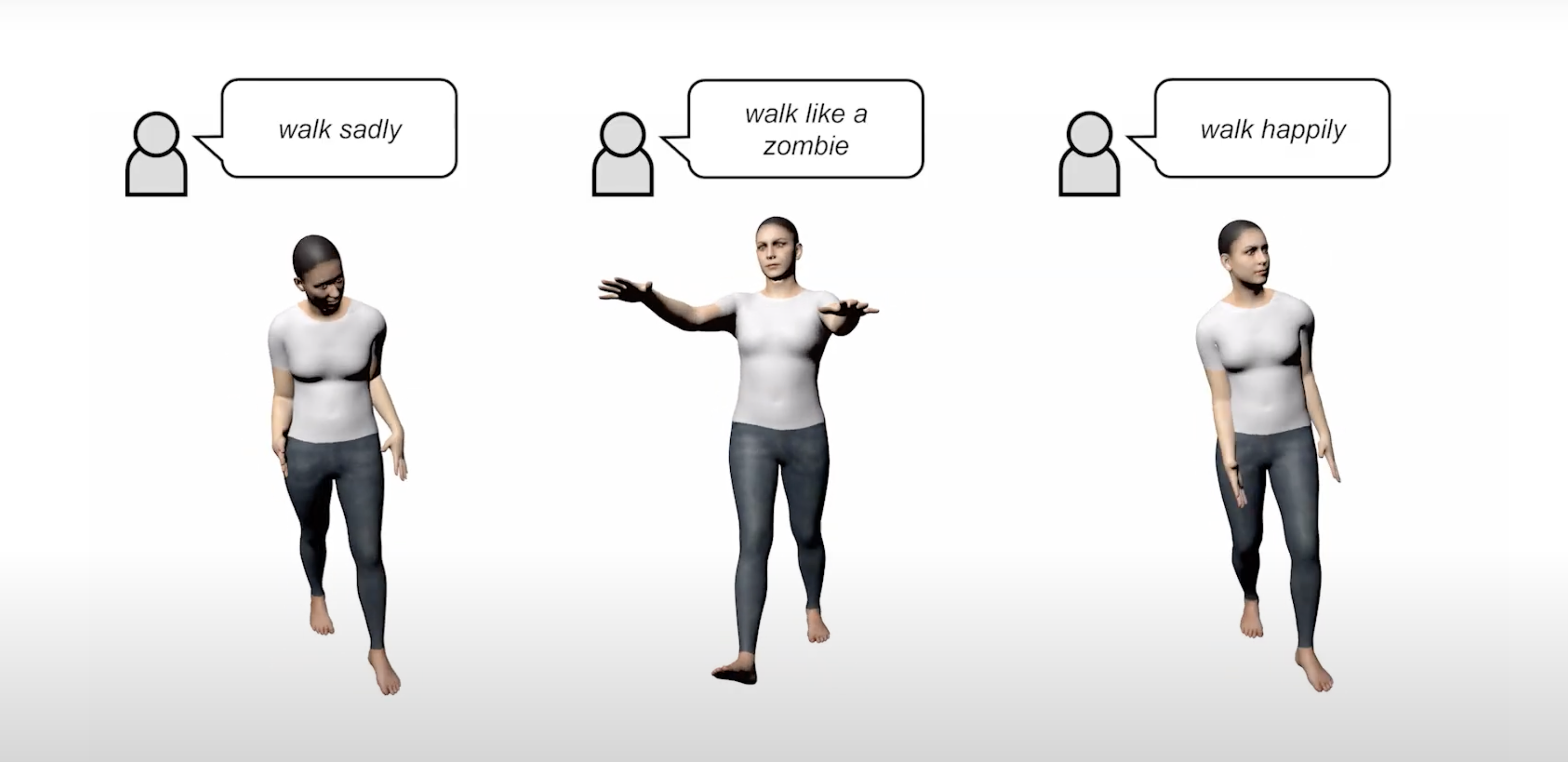
지금은 LLM과 Diffusion Model이 모션 생성(Motion Generation) 분야에서 활발히 활용되고 있습니다. 이러한 연구들은 초기 모델들과 많이 비교되거나, 기존 모델을 기반으로 더 고도화된(advanced) 버전을 제시하는 경우가 많습니다.또한, 새
11.[논문] BAMM: Bidirectional Autoregressive Motion Model

더 이상 모션 생성이 단순히 "모션만" 생성하는 시대는 끝났습니다. 이제는 길이에 대한 제약 없이, 적절한 길이를 스스로 예측하여 생성할 수 있어야 하며, 더 나아가 시간 축에서 모션을 자유롭게 수정할 수 있는 기능까지 갖춰야 하는 시대가 도래했습니다.이러한 요구를 충