
https://motion-gpt.github.io/
https://arxiv.org/pdf/2306.14795
https://github.com/OpenMotionLab/MotionGPT
Introduction
LLM은 방대한 양의 데이터를 사용하여, 포괄적인 언어 표현에 대해 학습하고, 이를 통해서 번역, 요약, 질의 응답과 같은 다양한 작업을 수행합니다. 다른 연구들은 이 LLM을 활용해서 vision, audio, robotics 영역에도 활용하고 있고, 저자들은 모션에 대해서도 이를 적용하려고 했습니다. 저자들이 사용한 핵심 개념은 "인간의 모션은 또 다른 언어"로, LLM에 적용하여 motion 설명, 생성, 그리고 예측이 가능하게 하였습니다. 특히, 단일 방향 (motion to text, text to motion)이 아닌 양방향이 한번에 가능하도록 하는 MotionGPT를 개발하였습니다.
Motion GPT는 모션 시퀀스를 token으로 인코딩했고, 사전 학습된 언어 모델을 이용하여 모션과 텍스트가 함께 있는 공간을 만들어 모션과 language가 상호적으로 추론될 수 있도록 하였습니다. 이 모델의 학습 단계는 motion tokenization, motion-language pre-training, instruction tuning으로 구성돕니다.
Method
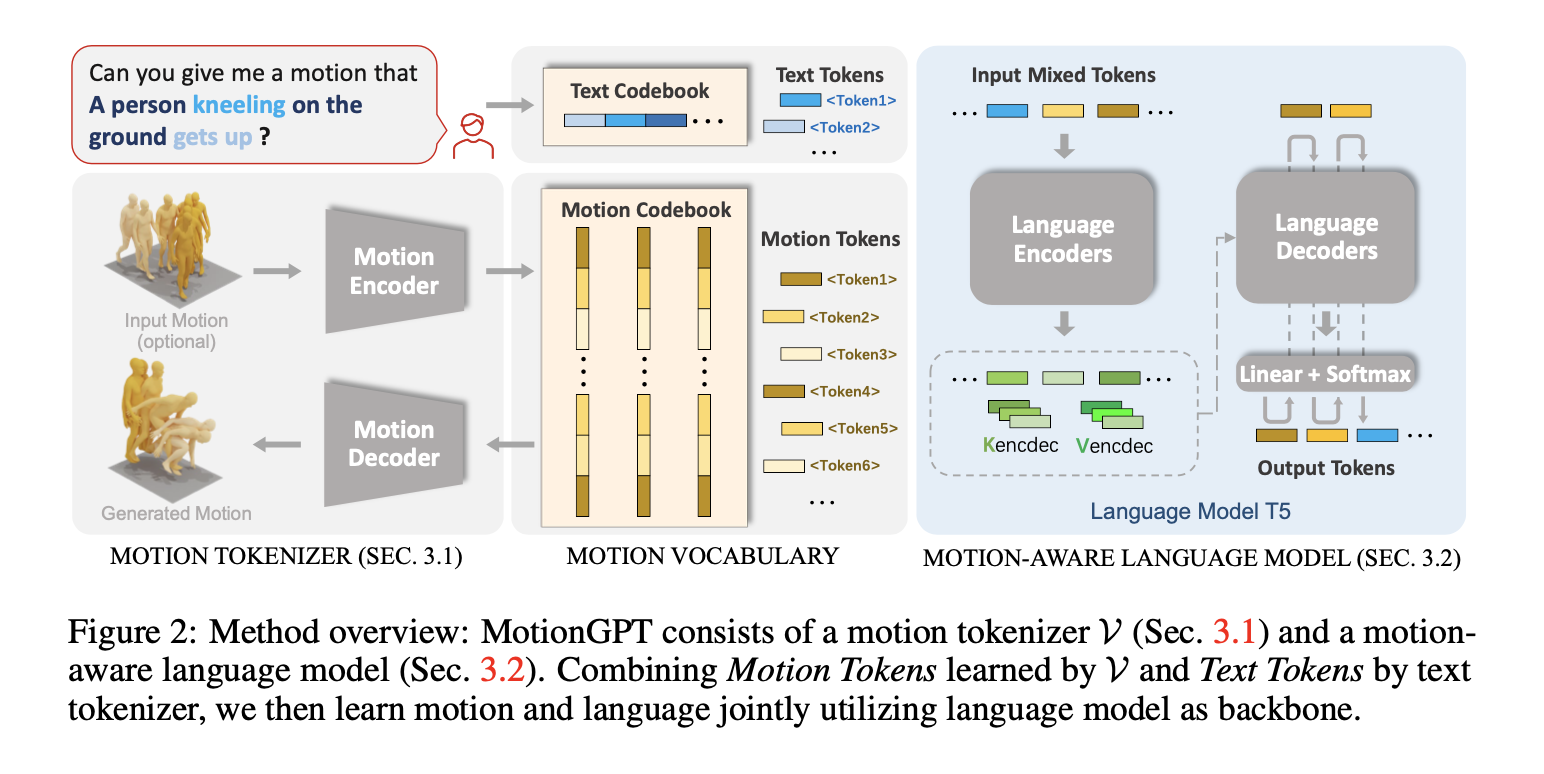
: 인코더와 디코더로 구성된 Motion Tokenizer를 이용하는데, 인코더는 모션 데이터를 모션 토큰으로, 디코더로 모션 토큰을 다시 모션 데이터로 복원합니다. 이후, Motion GPT는 모션 관련 N길이의 문장이 주어지면 L길이의 모션 또는 텍스트 토큰으로 변환합니다.
Motion Tokenizer
: motion을 discrete tokens로 변환. 인간 모션 을 모션 토큰 시퀀스 로 매핑 -> 모델에서 사용하는 vocabulary embedding을 이용한 joint representation가능.
- 모델 V (VQ-VAE, Vector Quantized Variational Autoencoders) 사전 학습
- V 는 인코더 와 디코더 로 구성.
- 인코더 :
- 에 1D 컨볼루션(1D convolutions)을 적용하여, latent vectors 를 생성
- 학습 가능한 코드북(learnable codebook) 는 차원의 개의 잠재 임베딩 벡터(latent embedding vectors)로 구성
- 양자화 과정(quantization)는 각 행 벡터(row vector) 를 코드북 내에서 가장 가까운 코드북 항목 로 대체
- 디코더
- 을 다시 원래의 모션 공간(raw motion space)으로 변환하여 프레임을 가지는 모션 을 생성
- Loss
- , reconstruction Loss
- : embedding loss
- : commitment loss
Motion-aware Language Model
: motion과 text를 한번에 학습하는 방식
- 기존의 언어 모델은 만 있었다면, Motion GPT는 를 활용.
- T5와 같은 Transformer 사용
- input: sequence of tokens , 는 어휘집 에 속하는 토큰, 은 입력 시퀀스의 길이
- output: , 는 어휘집 에 속하는 토큰, 은 출력 시퀀스의 길이
- 입력 토큰(source tokens)은 Transformer 인코더로 전달되며, 이후 디코더는 단계별로 다음 토큰의 probability distribution를 autoregressive manner로 예측.
- Loss (objective)
- 추론 과정: 목표 토큰(target tokens)이 예측된 확률 분포 에서 재귀적으로 샘플링(sampled recursively)되며,
종료 토큰(예: )이 나올 때까지 반복- 예를 들어, "점프 하는 모션을 보여줘"라고 하면, 처음에는 랜덤한 토큰을 선택 -> 이후 점점 자연스러운 모션 예측 -> 마지막 나놀때까지 반복.
Trainig strategy
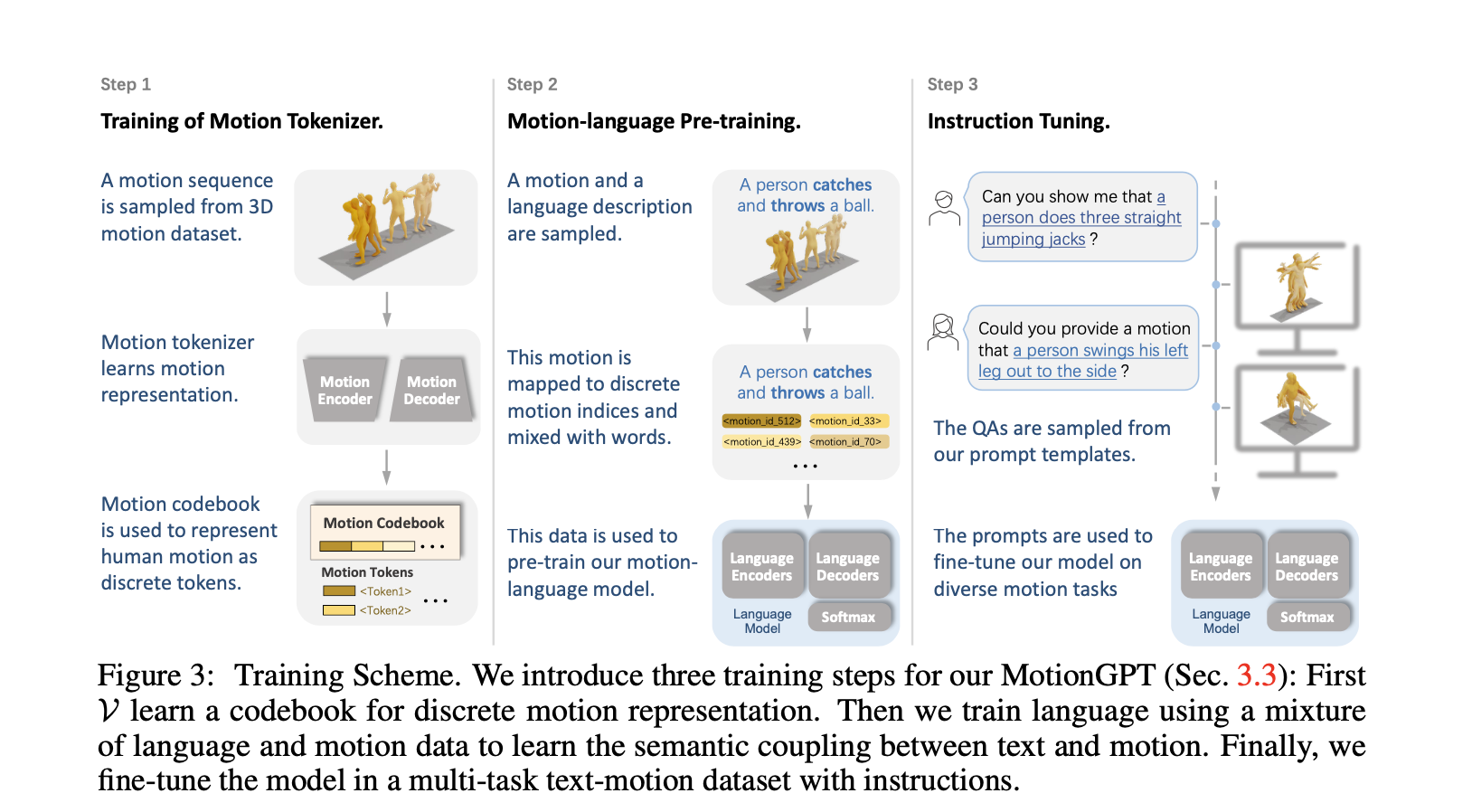
: 위 그림과 같이 Motion Tokenizer 학습 -> Motion-language Pre-training -> Instruction Tuning 순서로 학습.
Training of Motion Tokenizer
- motion sequence 도
모션 토큰 시퀀스(motion tokens)로 변환할 수 있도록 하여 텍스트정보를 완벽하게 통합하도록 학습 - 학습 후, 변경하지 않음
Motion-language Pre-training Stage
- 입력 토큰 의 일정 비율(15%)을 무작위로 특수 센티널 토큰(special sentinel token) 으로 대체 (비지도 학습)
- text-motion datasets을 활용한 지도 학습을 통해 모션과 언어의 관계 학습
Instruction Tuning Stage

- motion generation with text, motion captioning, motion prediction 등을 포함한 15개의 core motion tasks 정의 -> 각 task에 수십개의 서로 다른 template구성.
