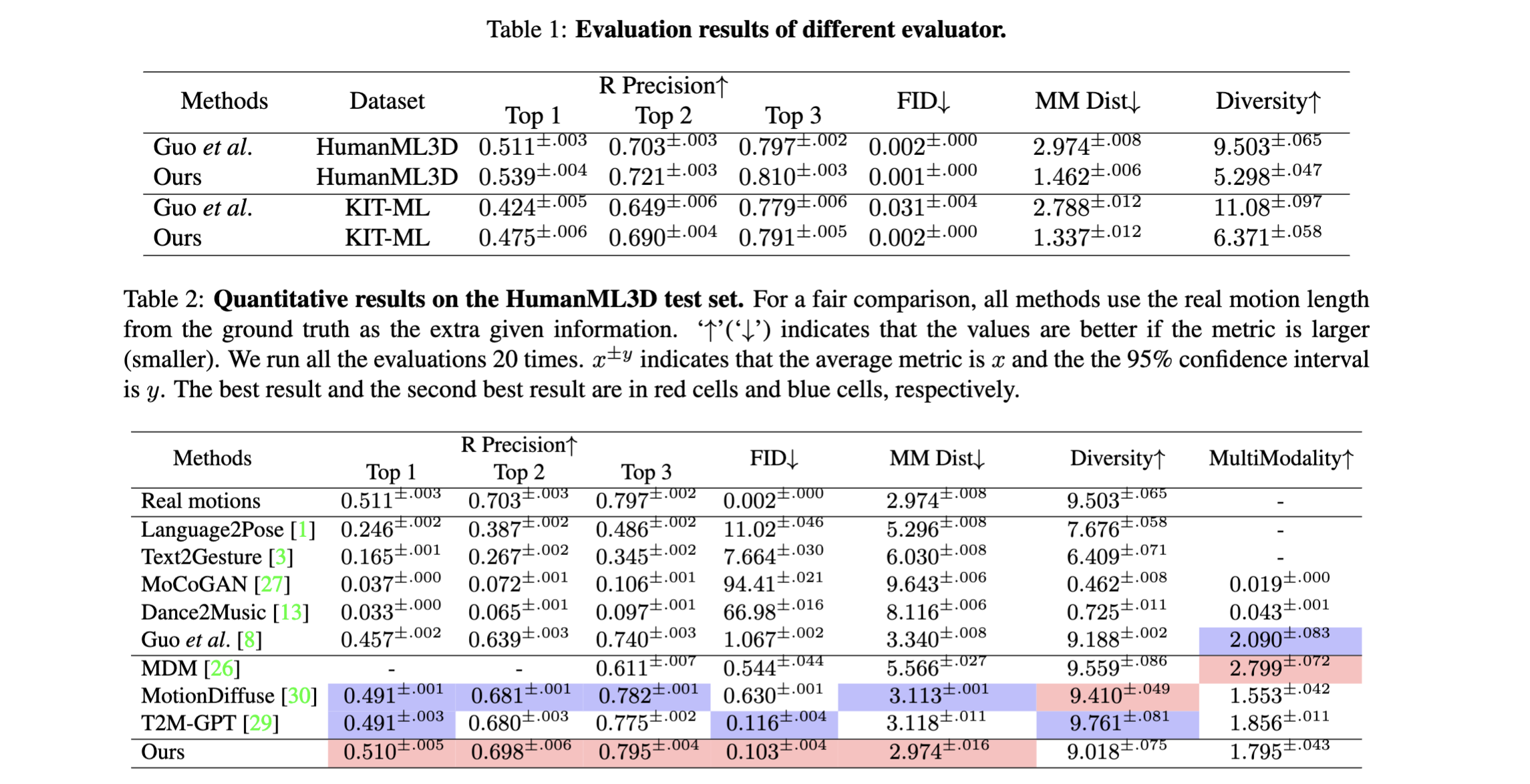
이번 논문은 많은 연구들에서 비교 대상으로 사용되는 ReMoDiffuse입니다. 그만큼 연구된 방법들이 타당하고 결과가 뛰어나다는 것이겠죠? 이 ReMoDiffuse에서 가장 인상적인 부분은 검색된 결과를 다시한번 활용한다는 것입니다. 연구를 하다보면 좋은 결과를 위해서 보통은 핵심을 바꾸거나 하는 경우가 많은데, ReMoDiffuse는 결과를 한번 더 활용함으로써 더 디테일하고 퀄리티 높은 모션 생성 결과를 보여주었습니다. 실제로 그런 결과들을 아주 세세한 방법으로 증명했다는 것에 큰 자신감을 보여주었다고 생각합니다. 멋있습니다 👍
https://arxiv.org/abs/2304.01116
https://github.com/mingyuan-zhang/ReMoDiffuse
https://mingyuan-zhang.github.io/projects/ReMoDiffuse.html
Introduciton
저자들은 모션 생성 기술이 아직까지 만족스럽지 못하다고 말합니다. VAE를 사용한 TEMOS, 두단계의 auto-regressive를 사용한 Guo의 연구, diffustion을 사용한 MDM 까지 모두 좋은 결과를 보였짐만 여전히 uncommon한 경우까지 커버하지는 못했음을 지적합니다. 또한 최근 retrieval 방식을 활용하는 연구들이 있지만 목표된 모션 시퀀스와 데이터베이스내의 유사성이 복잡하며, 단일 모션 시퀀스는 보통 여러개의 세부 동작을 포함하는 점과 CFG방식이 스케일에 매우 민감하다는 점에서 해당 방법이 결코 쉽지 않음을 말합니다.
저자들이 제안한 ReMoDiffuse 역시 retrieval을 활용하는데, 보다 철저하게 위의 특징들을 고려하며 개발했다고 합니다. 일단 retrieval은 retrieval stage와 refinement stage로 나뉩니다. 추가로, 추론과정에서 condition mixture를 통해 다양한 조건에서도 높고 일관적인 시퀀스를 생성하도록 했습니다. 이 연구는 기존의 연구들보다 더 좋은 성능을 보임을 증명했고, 새로운 평가지표를 더해 모델의 일반화 성능을 자랑했습니다.
Our Approach
Framework Overview
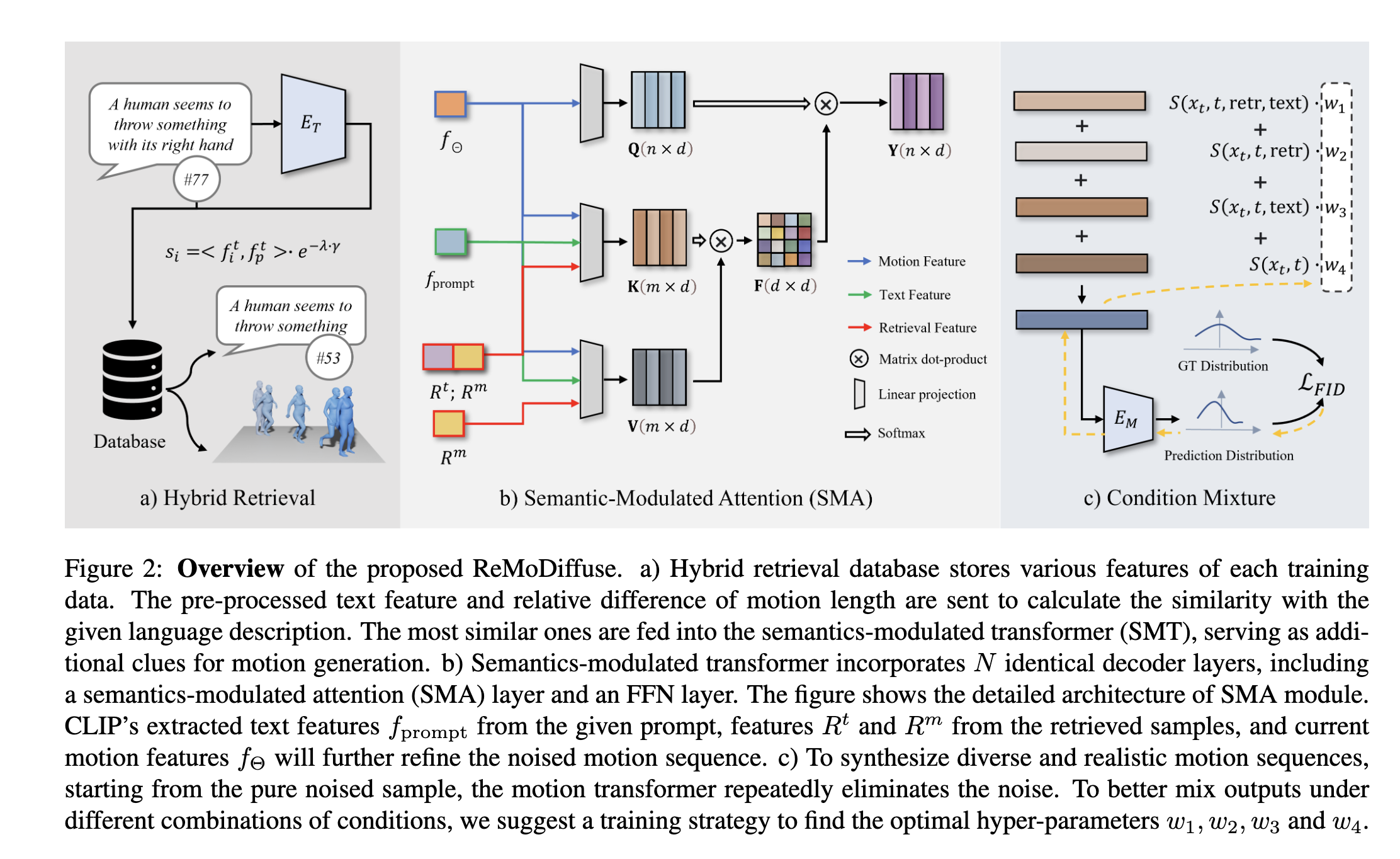
- MotionDiffuse기반의 전체 파이프라인
- diffusion모델과 일련의 transformer decoder layer를 포함
- 일반화 성능 강화를 위한 text와 motion feature를 추출하여 데이터 베이스 구축
- denoising 단계에서 모션 길이와 text feature에 기반하여 찾은 motion을 찾은 후, SMA 레이어가 있는 motion transformer decoder로 정제 후 주어진 desciption과 찾은 sample들 중에서 정보를 추출
- classifier free 생성과정에서 서로 다른 조건 조합에 따른 다양한 출력을 생성하는데, 이때 필요한 하리퍼 파라미터 조합은 잘 찾아둬야 한다.
Diffusion Model for Motion Generation
- MDM 기반의 diffustion model
- training target:
- : 검색된 샘플과 주어진 프롬프트의 조건
- training target:
Retrieval-Augmented Motion Generation
저자들의 retrieval 파이프라인은 데이터베이스에서 적절한 샘플을 찾는 단계와 검색된 샘플로부터 knowledge를 얻고 diffusion model의 denoising 과정을 정제하는 단계로 구성되어 있습니다.
Hybrid Retrieval
- CLIP Decoder (pretrained)
- language description과 기존 database들간의 semantic similarity를 계산하는데 사용
- 각 data point ()에서 text-query feature 를 연산.
- 보통 검색(retrieval) 과정에 의미적으로 유사한 샘플을 뽑을 때, 예상 모션 길이와 데이터베이스 내 각 entity의 길이간의 상대적 magnitude를 고려하지 않는데, 반드시 간과하면 안됨!
- 유사도
- : consine similarity, : motion sequence 의 길이
- : 두 개의 서로 다른 유사성의 크기를 조절하는 하이퍼파라미터
- 예상 모션 길이가 특정 entity의 길이와 비슷할 겨우, 증다
- 유사도
- Database 구축
- 모든 훈연 데이터를 entity로 선택
- 검색할 샘플 수 , prompt, 로 유사도 를 구해 정렬
- 가장 유사한 개의 샘플을 검색 샘플 ()로 선택하여, 모션 transformer의 semantics-modulated attention에 입력
Network Architecture
- semantics-modulated attention과 FFN(Feed-Forward Network)에 timestep을 넣기 위한 stylization block 추가 (MotionDiffuse에서 사용된 방법)
- timestamp 로 부터 embedding vector 생성
- classifier-free guidance 사용할 수 없음
- 각 블록의 입력 와 출력 에 shorcut 연결
- timestamp 로 부터 embedding vector 생성
- 검색된 샘플의 효율적 활용
- 문제점:
- motion diffusion model에서는 denoising과정에서 모션 시퀀스의 해상도가 감소되지 않아 연산이 너무 많다.
- 검색된 샘플과 주어진 prompt간의 의미적 관계가 복잡
- "사람이 앞으로 간다"와 "사람이 앞으로 천천히 간다"는 매우 유사하지만, 이 두 prompt는 속도와 강도면에서는 서로 다른 모션 sequence를 유도.
- solution
- 검색된 데이터의 텍스트 특징과 모션의 feature를 따로 추출할 수 있도록 두개의 encoder 설계
- low level 정보를 제공하면서 비용이 낮은 Semantics-Modulated Attention (SMA) 모듈과 FFN 모듈을 포함한 encoder
- motion encoder
- 원래의 FPS를 1/4로 다운 샘플링:
- : 다운샘플링 후의 프레임 개수, : 검색된 샘플 수
- 원래의 FPS를 1/4로 다운 샘플링:
- text encoder
- 마지막 token에서 추출된 feature 은 global semantic information
- 과 는 etrieval-based augmentation의 주요 요소
- 문제점:
Semantics-Modulated Attention
- Cross attention component
- query vector : 노이즈가 포함된 motion sequence
- key vector 와 value vector :
- motion sequence 그차제
- 제안된 transformer에 self-attention 모듈 없는 대신, 그 기능을 SMA에 포함
- text condition : 예상되는 모션 시퀀스를 의미적으로 설명하는 조건
- CLIP과 두 개의 학습가능한 transformer encoder layer로 얻을 수 있음
- 검색된 샘플에서 가져온 과
- : concatenation of
- : concatenation
- : 두개를 먼저 concat
- motion sequence 그차제
- 기능:
- low-level의 모션 정보 융합
- 검색된 샘플과 prompt간의 의미적 유사성 고려 가능
- 여기서 획득한 는 연산 효율성을 위해, Linear Attention 수행
stylization block
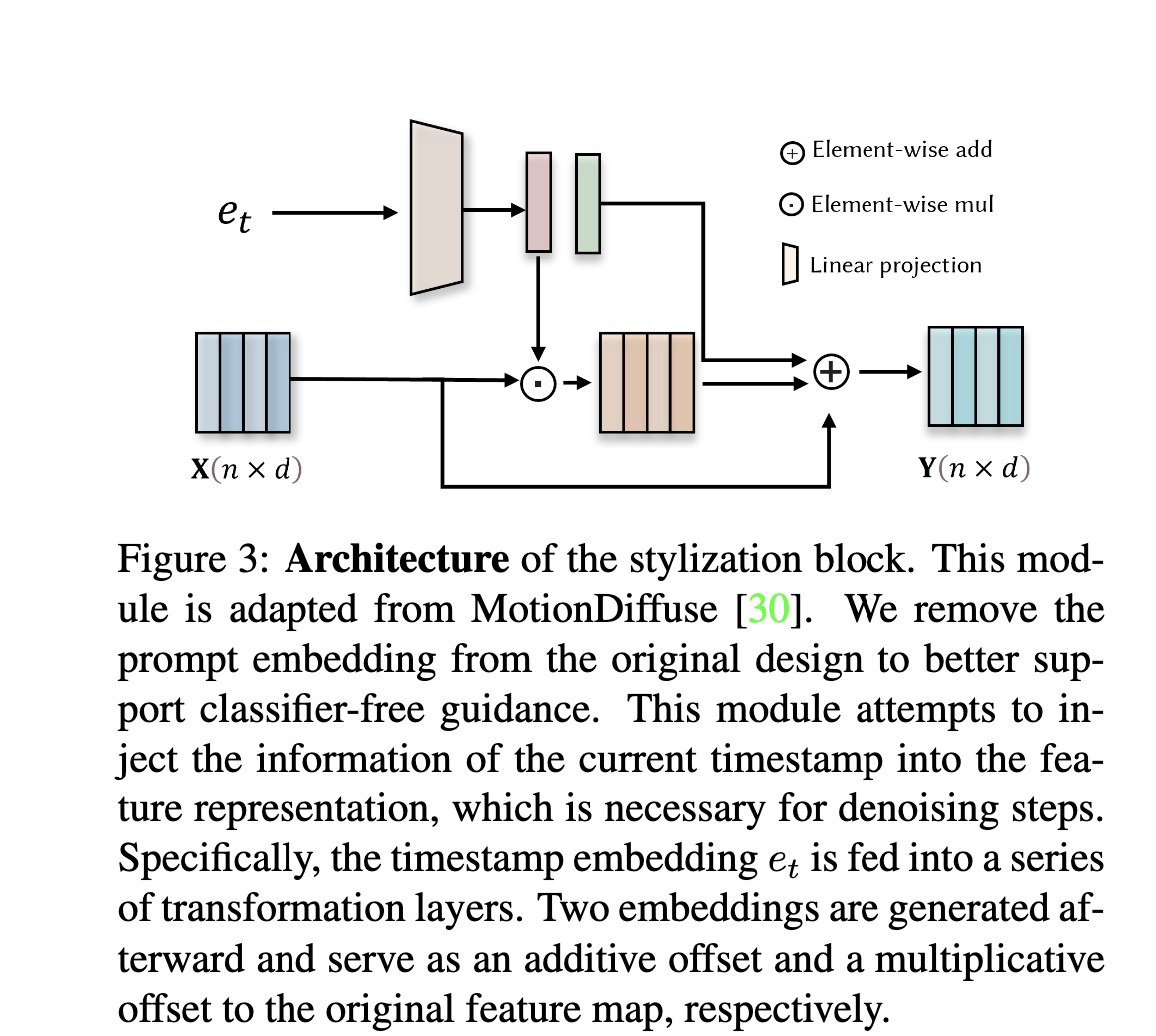
(MotionDiffuse에서 가져와서 사용)
- classifier-free guidance를 위해서, prompt embedding 제거
- 현재 timestamp의 정보를 feature representation에 사용하기 위한 목적
- denoising과정에 필수
- 가 transformation layer들에 입력되고, 두개의 임베딩으로 생성되어, original feature map에 더해지는 offset과 곱해지는 offset으로 적용되어 보정 요소로 작용
Condition Mixture
- Classifier-free guidance
- 주어진 텍스트 설명과 높은 일관성을 유지하면서도 high-fidelity 모션 시퀀스를 생성할 수 있도록
- : text-consistency와 motion quality의 균형을 조절하는 하이퍼파라미터
- 제안된 retrieval-augmented diffusion 파이프라인에서는 추가적인 조건이 있음
- 따라서, Condition Mixture 기법 제안
- 를 최적화하여 최종 출력값 을 얻음
- 이 값들이 최적일 때, FID의 경향이 Precision과 유사. FID 최소화
Contrastive Model
- 평가할때, evaluator를 최소화하기 위해, contrastive model 학습
- 텍스트 설명과 모션 시퀀스를 공동 임베딩 공간(joint embedding space)에 인코딩
- motion encoder: ReModiffuse와 동일
- 유일한 차이는 word feature대신 sentence feature필요
- 2만-4만번 정도 최적화시킨 후 KIT-ML과 HumanML3D에 적용
Parameter Finetuning
- 50 단계 denoising을 사용하기 위해
- 처음 40단계, grid search
- 를 [-5,5]범위에서 0.5 간격으로, =0
- 마지막 10 단계, auto-regressively denoise하면서 FID를 최소화
- Adam Optimizer로 1K step 학습 (HUmanML3D, KIT-ML)
- 처음 40단계, grid search
Training and Inference
Model Training
- Classifier-free 적용: 텍스트 조건의 10% 및 검색 조건의 10%를 독립적으로 랜덤 마스킹
- 훈련에서는 1000-step diffusion process 사용
Model Inference
- 사용하여 %\hat{S}% 연산
- 반복연산이 발생하지 않게 을 사전처리
- denoising processdms 50번
Experiments
- Data: HumanML3D, KIT-ML
- Metrics: Frechet Inception Distance (FID), Diversity, Matching Score, R-Precision
Main Results