더 이상 모션 생성이 단순히 "모션만" 생성하는 시대는 끝났습니다. 이제는 길이에 대한 제약 없이, 적절한 길이를 스스로 예측하여 생성할 수 있어야 하며, 더 나아가 시간 축에서 모션을 자유롭게 수정할 수 있는 기능까지 갖춰야 하는 시대가 도래했습니다.
이러한 요구를 충족하면서도 높은 성능을 유지하는 모델, 바로 BAMM이 제안되었습니다. (이름이 뭔가 귀엽지 않나요? 저만 그런가요? 😅)
특히, 저자들은 기존의 마스킹 방식과는 완전히 다른 형태의 마스킹 전략을 도입하였는데요. 이런 아이디어를 떠올렸다는 것 자체가 attention 메커니즘을 얼마나 깊이 이해하고 있는지를 보여주는 증거라고 생각합니다.
본 논문은 ECCV 2024에 채택되었는데, 솔직히 더 높은 학회에 제출되었어도 충분히 경쟁력이 있었을 것 같네요. 실제 평가 지표를 보면 성능도 압도적이죠!
https://exitudio.github.io/BAMM-page/
https://github.com/exitudio/BAMM/
https://arxiv.org/abs/2403.19435
Introduction
최근 모션 생성 연구는 conditional denoising motion model과 conditional autoregressive motion model에 초점을 두고 있다. Diffusion은 masking과 함께하여 좋은 결과를 보여주지만, 모션의 길이가 한정되어 있다. 그에 비해, GPT같은 LLM은 길이의 제한이 보다 자유롭다. 하지만, 토큰을 decoding하는 과정이 text의 의미를 희석시키기는 면과 편집 과정이 어려운점에 아쉬움이 있다.
저자가 제안하는 BAMM은 motion tokenizer와 conditional masked self-attention transformer를 사용하여 위 두 모델 방법론이 가질 수 있는 취약점을 보완하는 text-to-motion 프레임워크다. 이 방법론은 특정 작업을 위해 별도로 학습하지 않고도, inpainting, outpainting, prefix prediction suffix completion과 long sequence genration까지 가능하다.
조금 더 얘기하자면, BAMM은 VQ-VAE 기반의 motion tokenizer 학습과 [MASK]의 토큰 대체 방식이 아닌 attention score matrix 조정하는 방식을 적용한 모델 학습으로 두 단계의 학습과정을 가진다. 학습과정에서 마스킹된 예측과 autoregressive 예측을 통합함으로 풍부하고 bidirectional한 특성을 가지며, 동시에 직접적인 확률적 매핑과 길이 조정이 가능한다. 따라서, 추론 과정에서는 우선unidirecitional autoregressive deconding으로 모션 길이를 예측하고 그에 맞는 시퀀스를 생성하고, 일부 모션 토큰을 마스킹하여 bidirectional 방식으로 다시 생성하여 정제한다.
Method
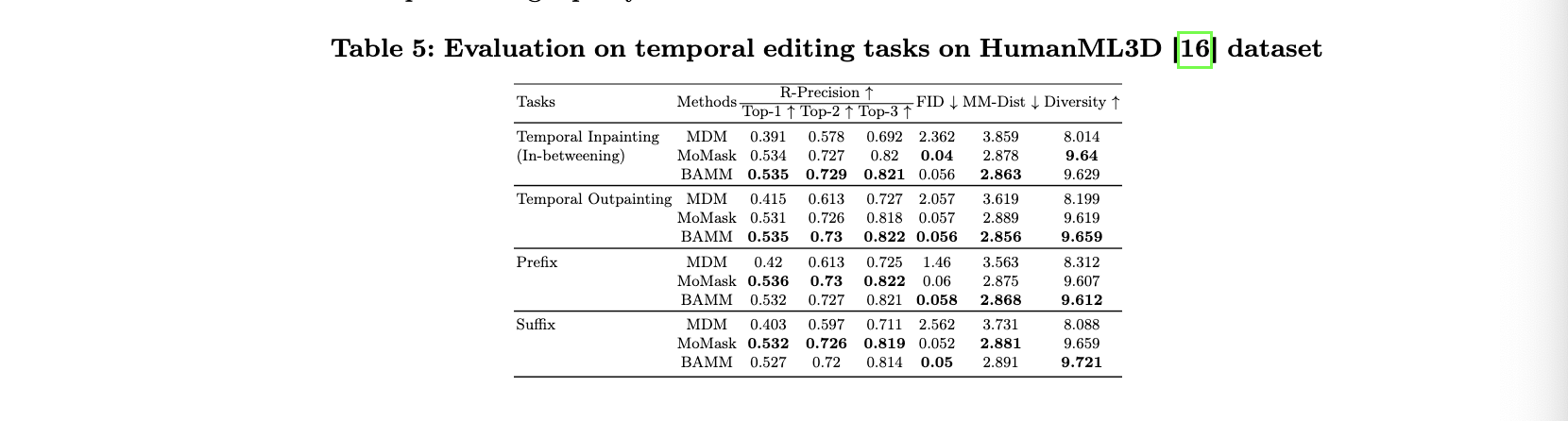
저자의 프레임워크는 두가지 핵심 구성 요소가 있다. (1) input 모션을 motion token seauence로 변환하는 Motion Toknizer. (2) unidirectional and bidirectional causal masks와 generative masked model이 통합된 Conditional Masked Self-Attention Transformer.
학습 과정은 무작위로 적용된 두가지 casual mask 방식을 사용하고, 추론 과정은 계단식 모션 디코딩 방식을 사용한다.
Motion Toknizer
목표
: embedding 를 코드죽의 C로 quantization (모션의 이산 표현)
모델
: VQ-VAE(Vector Quantized Variational Autoencoder) 기반
과정을 얘기해보자면 original 모션 시퀀스 을 다운 샘플링하여 latent embedding 로 변환하고, codebook 에서 유클리드 거리가 가장 가까운 코드 c로 양자화된다. (여기서, 양자화라는 표현은 원래 모션이 가장 가까운 코드를 고르면서 원래 있던 디테일이 사라질 수 있기 때문에 사용한다.)
이 과정을에 대한 손실 함수는 다음과 같이 정의된다.
Conditional Masked Self-Attention Transformer
입력
(1) tokenizer으로 생성한 모션 토큰 , (: motion 길이),
(2) 사전 학습된 CLIP에서 출력된 text embedding
(3) 모션의 종료 지점을 나타내는 토큰
masking 방식
: 기존 generative masked models과 달리, 단순히 입력 토큰을 [MASK]로 대체 하지 않는다. Fig. 2(b)에서 처럼, 입력 토큰 간의 attention 관계를 지정하기 위해 causal attention mask 을 적용한다. 검정으로 마스킹된 토큰의 attention이 허용된 범위는 자기 자신, 왼쪽의 모션 토큰과 오른쪽의 마스킹되지 않은 토큰뿐이다. 반대로 마스킹이 되지 않았다면 양쪽의 마스킹되지 않은 토큰에 대해서만 attention을 적용할 수 있다.
여기서 사용되는 mask 방식은 단방향과 양방향으로 두 가지 casual mask로 나뉜다. 단방향 마스크 는 텍스트 토큰만 놔두고 다른 토큰을 다 마스킹하는 방식이며, 양방향 마스킹 은 텍스트와 [END] 토큰을 제외한 토큰을 무작위로 마스킹하는 방법이다. 이런 방식이 적용된 Self-Attention Transformer는 autoregressive motion generation의 인과적인 특성을 유지하고, 미래 토큰을 활용할 수 있게 된다.
self-attention 적용
- Attention
masking이 적용되었을 때의 attention은 위와 같이 연산된다. 여기서 은 attention이 가능한 토큰에 대해서는 0으로, 그렇지 않다면 음의 무한대로 설정된다.(음의 무한대를 적용하면 softmax때문에, 결국 0이 되기 때문)
Training: Hybrid Attention Masking
학습 과정을 요약하자면, 주어진 모션 시퀀스 토큰 와 텍스트 토큰 에 대하여 모션 시퀀스를 복원하도록 하며, 그 과정에서 마스킹 방식이 적용된다.
학습 목표
: 여기서 는 단방향 인과 마스크가 선택될 확률로 0.5로 설정했을때 학습결과가 가장 좋았다고 한다.
Inference: Cascaded Motion Decoding
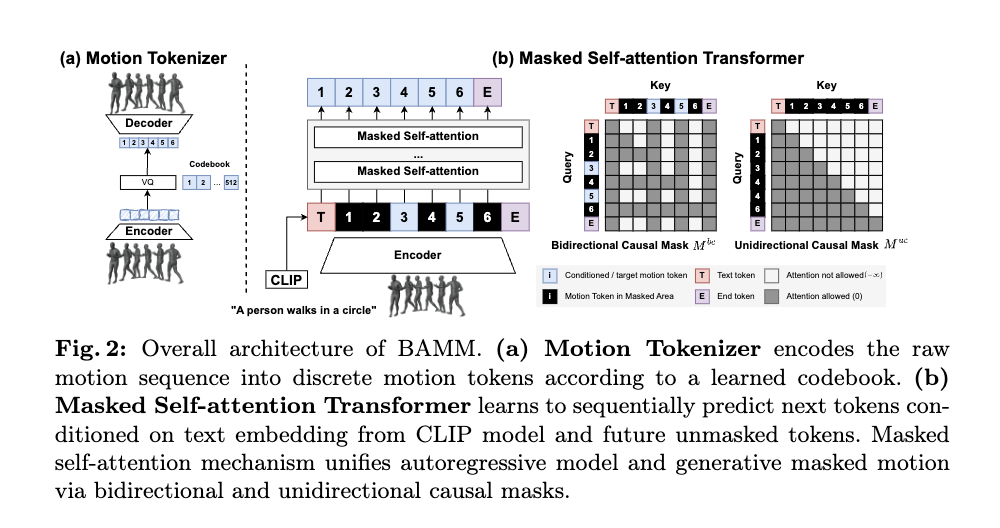
추론 방식은 이중 반족 방식의 cascade(계단식) 디코딩이다.
첫 번째 반복에서는 autoregressive decoding 방식으로, 단방향 예측분포 을 기반으로 샘플링되며, [END] 토큰이 예측될 때 중단한다.
두번째 반복은 앞서 생선된 모션의 축적된 오차를 정제하는 과정으로 일부 모션 토큰을 에 따라 다시 샘플링을 진행한다.
이 방식은 surrounding context를 기반으로 신뢰도가 낮은 토큰을 다시 예측할 수 있다.
Hybrid Classifier-Free Guidance
모델을 학습할 때, uncondition에도 추론할 수 있도록, text 토큰을 무작위로 제거하는 방식을 사용한다. 또한 추론시에는 CFG방식을 적용한다.
Residual Motion Refinement
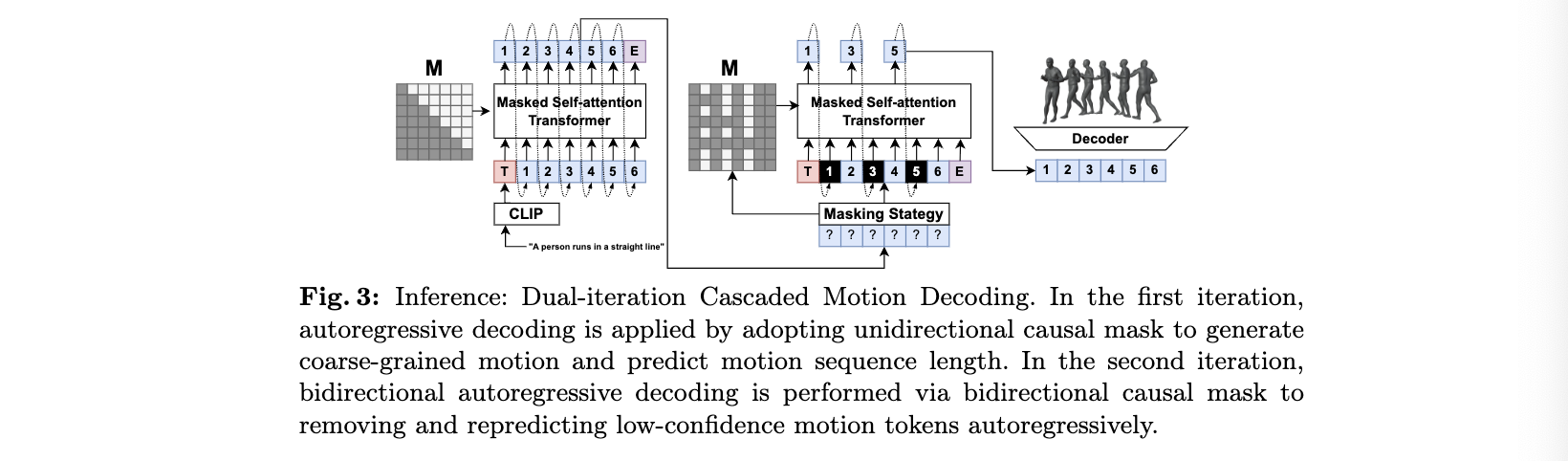
이 모델에는 추가적인 정제과정을 또다른 transformer를 추가하여 RVQ방식으로 수행한다. 이 방식은 원본 모션 시퀀스를 lantent space에서 multiple token sequence로 인코딩한다. 첫번째 VQ가 먼저 대부분의 정보를 인코딩하면 나머지 VQ는양자화 과정에서 생길 수 있는 에러를 인코딩하면서 정보손실을 막는다.
Motion Editability
autoregressive 방식은 미래 토큰을 활용할 수 없어 temporal motion editing이 불가능하지만, BAMM은 bidirectional causal mask를 사용했기 째문에 가능하다. 수정하고 싶은 위치에 masked attention을 적용하기 때문이다.
Experiments
Comparison to State-of-the-Art Approaches

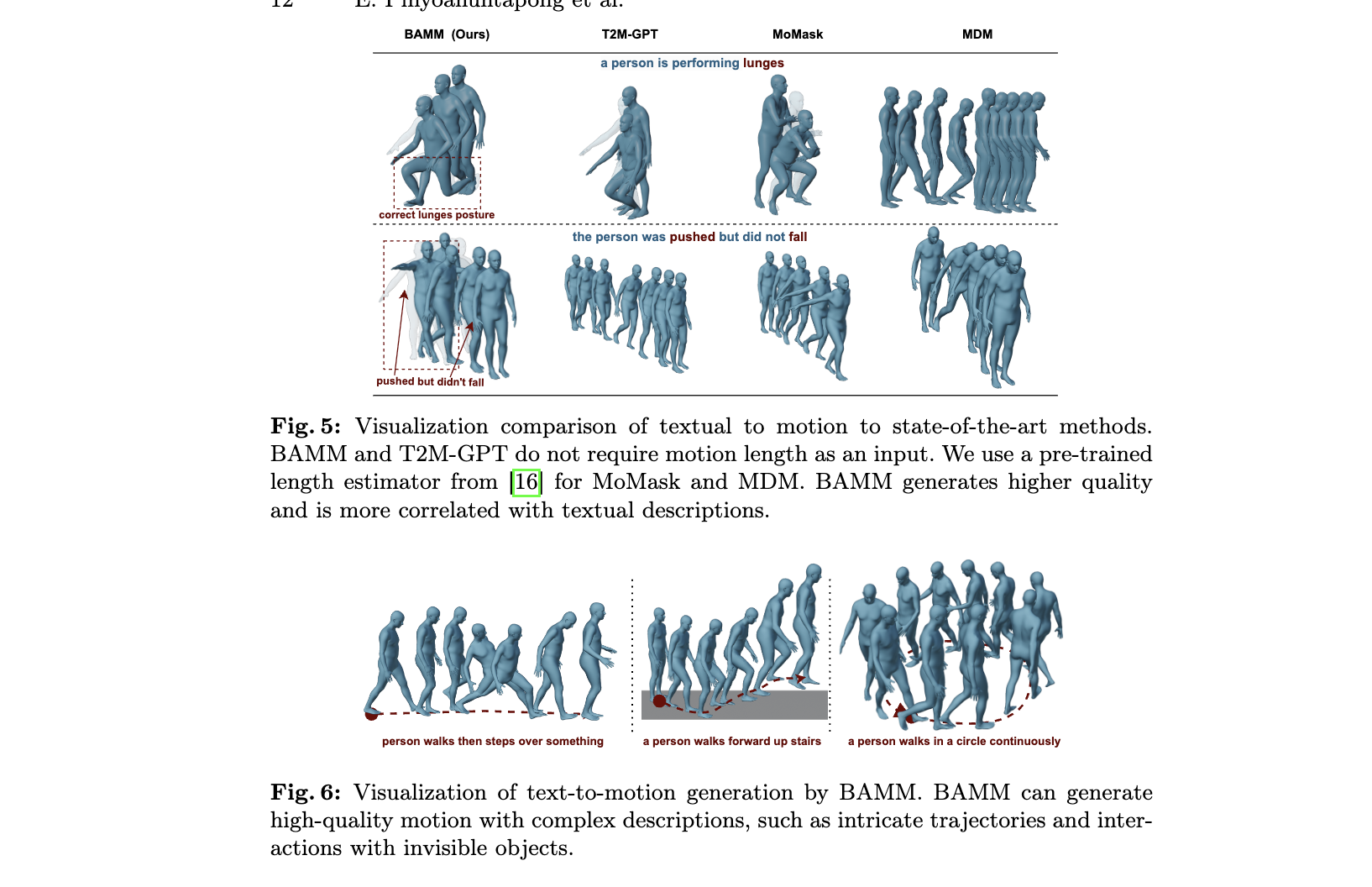
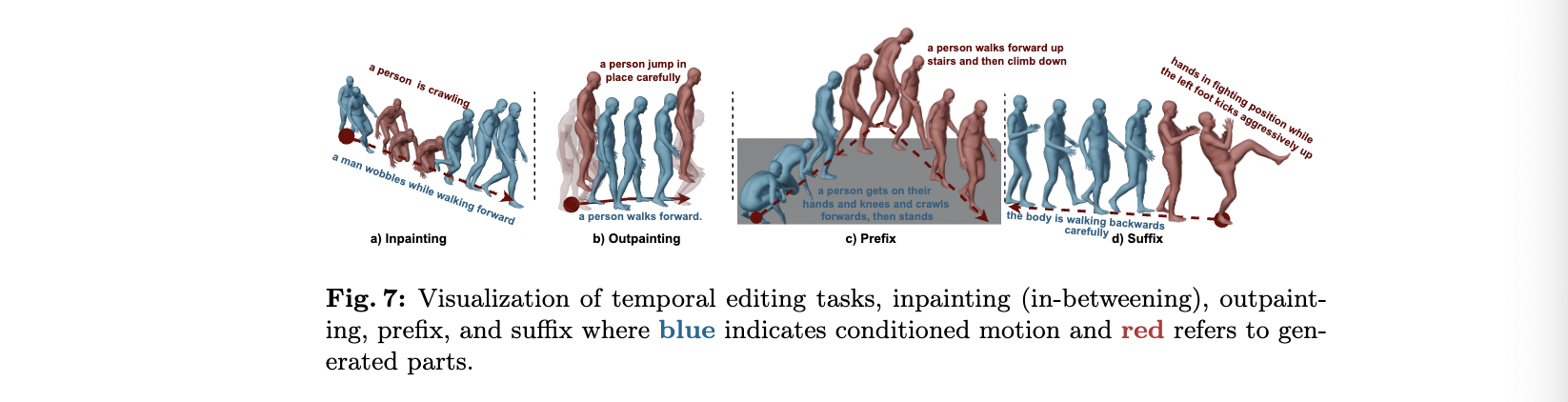
Length Prediction and Editability