
Text-to-Motion 분야로 많은 가능성이 제기됐지만, 여전히 아쉬운 부분들이 많이 있죠. 요청하고자하는 text가 너무 길거나 복잡하면 디테일함이 빠지거나 잘 만들어지지 않는 것들을 많이 보셨을 수 도 있을거에요. 이번 논문에서는 그런 문제가 token을 만들 때 quantization이 되면서 오차가 생기는 것임을 지적하면서 새로운 방법을 제안합니다.
물론, 이 방법이 기존 문제를 시원하게 해결해주지는 못했어요. 마지막 결론 부분을 보면, 여전히 완전 복잡한 모션에 대해서는 디테일이 떨어질 수 있고, 다른 데이터셋에서는 파인튜닝이 필요하다고 말합니다. 하지만, 이런 시도가 나중에 더 완벽한 모델을 만드는데 다 양분이 되는 것 아닐까요?
https://ericguo5513.github.io/momask/
https://arxiv.org/pdf/2312.00063
https://github.com/EricGuo5513/momask-codes
https://huggingface.co/spaces/MeYourHint/MoMask
Introduction
기존의 VQ-VAE는 모션을 단일 token sequence로 변환하는 방식인데, 이는 양자화 오류가 생길 수 있다고 합니다. 즉, 모션을 하나의 토큰으로 바꾸고 Codebook에서 KNN을 사용하여 가장 유사한 토큰을 찾는 방식은 모션의 일부 디테일한 정보가 사라져버리는 문제가 생긴다는 것이죠. 또한, diffusion방식은 sampling을 반복하면서 생성 속도가 느리다는 단점을 꼬집습니다.
이런 문제를 MoMask에서는 RVQ-VAE 방식을 도입하여 다중 토큰으로 변환하여 정밀한 표현을 가능하도록 하고, 그 뒤에 Masked Transformer로 베이스가 되는 레이어 모션 토큰을 생성합니다. 다음은 Residual Transformer를 사용하여 베이스 레이어 토큰을 기반으로 residual token들을 예측하여 점진적으로 모션을 더 정밀하게 복원할 수 있도록 합니다.
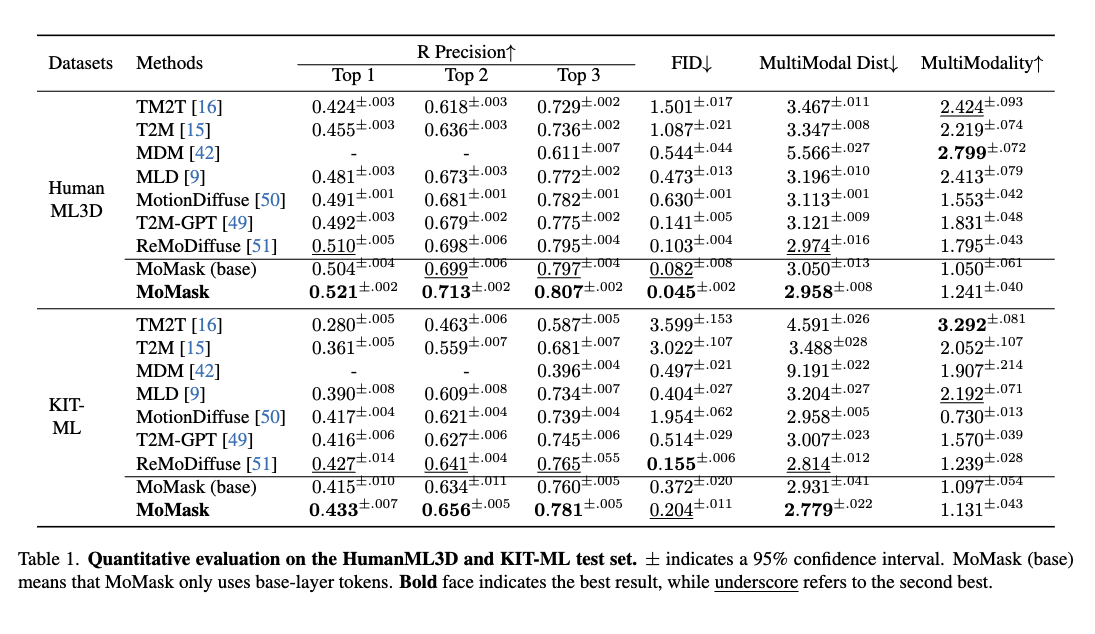
이런 방식은 단 15의 반복으로 고품질의 모션을 생성하는 방법으로 HumanML3D(0.045)와 KIT(0.204) 데이터에서 기존보다 작은 FID를 보이면서 새로운 SOTA임을 증명합니다.
Approach
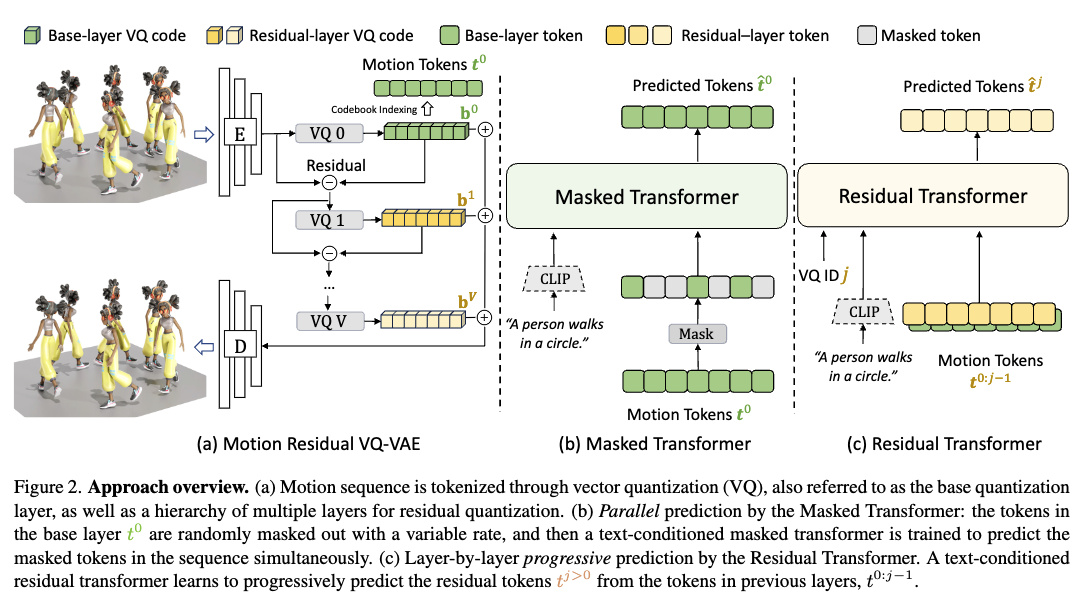
- 목표: text desciotion 를 기반으로 3D motion sequence 생성.
- : sequence length, : feature vector dimension
- 구성:
- Motion sequence를 multi layer discrete token으로 변환하는 Residual-based Quantizer
- base layer의 motion token을 생성하는 Masked Transformer(M-Transformer)
- residual layer의 token을 예측하는 Residual Transformer(R-Transformer)
Training: Motion Residual RVQ-VAE
-
기존 VQ-VAE
- 1D conv Encoder: latent vector sequence 로
- codebook에서 가장 가까운 것으로 대체 (Quantiztion, ):
- projection:
- 효과: 효율적
- 단점: 정보 손실로 인한 모션 reconstruction quality 제한
-
RQ 방식: 를 개의 code sequence로 변환
-
bv{1:n}
-
추론된
-
장점: fine-grained representation
-
-
loss
-
-
Motion Reconstruction Loss
-
Latent Embedding Loss
-
-
DropOut
- trainig 중, ~ 개의 quantization layer를 비활성화
- Initial layer가 중요한 요소를 reconstruction하도록 하여 robust하게 만듦.
- trainig 중, ~ 개의 quantization layer를 비활성화
-
After training
- input 을 token 로 변환
- input 을 token 로 변환
Training: Masked Transformer
-
목적: base layer motion token 의 global context 모델링
- 여기서 은 마스킹된 토큰
-
Masking 방식
- 시퀀스 토큰의 일부를 랜덤하게 마스킹
- cosine함수 에 따라 마스킹 비율을 스케줄링
- 학습 중, 이 랜덤하게 샘플링, 개의 시퀀스 항목에 균등하게 마스킹
- BERT의 remasking strategy 적용: contextual reasoning을 위해서
- 80% 확률로 [MASK] 토큰 유지
- 10% 확률로 랜덤 토큰으로 변경
- 10% 확률로 원래 토큰을 유지
-
Loss
Training: Residual Transformer
- 구조: M-Transformer와 유사하지만, 개의 개별 embedding layer
- Training 중,
- 선택, : embedded & summed token embedding input
- Loss
- parameter sharing: j 학습시, j+1에서 사용할 정보(token embedding)을 함께 학습
Inference
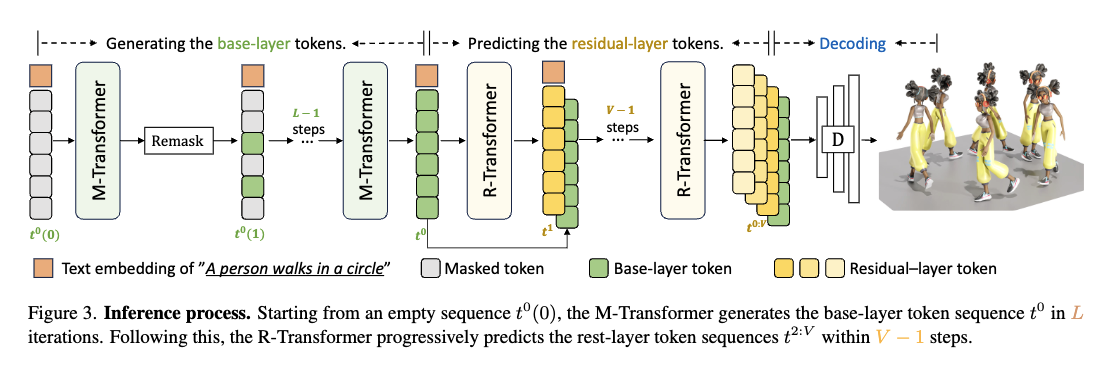
-
Base-Layer Motion Tokens 생성 (M-Transformer 활용)
-
빈 [MASK] 토큰으로 채워진 시퀀스 생성
- 처음에는 모든 모션 토큰이 [MASK]로 가려져 있음
- 모델이 텍스트를 보고 점진적으로 채워나가는 방식
입력: [MASK] [MASK] [MASK] [MASK] [MASK] [MASK] -
Masked Transformer가 일부 토큰을 예측
- 모델이 문맥을 고려하여 일부 마스킹된 토큰을 채움
- 하지만 confidence가 높은 토큰만 남기고, 낮은 토큰은 다시 마스킹
첫 번째 예측: A B C D [MASK] [MASK] -
Remasking 수행 → 확신도가 낮은 토큰은 다시 마스킹하고 재예측
- 반복적으로 예측하면서 점점 더 정교한 모션을 생성
두 번째 예측: A B C D E [MASK] 세 번째 예측: A B C D E F ✅ (최종적으로 모든 기본 레이어 토큰이 채워짐) -
최종적으로 M-Transformer를 통해 base layer의 모션 토큰 완성
-
-
Residual-Layer Motion Tokens 생성 (R-Transformer 활용)
- Base-Layer Tokens을 입력으로 사용
- base layer에서 생성된 토큰을 기반으로 Residual 정보를 추가하는 과정
- 더 세밀한 움직임을 표현하기 위해 추가적인 Residual Layers 생성
- Residual Transformer가 계층별로 토큰을 점진적으로 예측
Base 레이어: A B C D E F ✅ (이전 단계에서 완성됨) 1번째 Residual: A' B' C' D' E' F' 2번째 Residual: A'' B'' C'' D'' E'' F'' ...- 각 계층의 잔여 정보를 이용하여 점진적으로 모션을 보완
- 높은 레이어로 갈수록 더 작은 Residual을 추가함
- 마지막 Residual Layer까지 예측되면 모든 모션 토큰 생성 완료
- Base-Layer Tokens을 입력으로 사용
-
Motion Decoding
- 모든 모션 토큰 를 RVQ-VAE Decoder에 입력
- 3D 포즈 데이터 으로 변환
-
Classifier-Free Guidance 적용
- 생성된 모션을 더 자연스럽고 일관되게 보정
- : 최종 출력 값 (Guided Prediction)
- : 조건부 예측 값 (Conditional, 텍스트 기반)
- : 무조건 예측 값 (Unconditional, 텍스트 없이)
- : Guidance Scale (조건을 얼마나 강하게 적용할지 조절하는 값)
Experiment
- data: HumanML3D, KIT-ML
- train : test: validation = 0.8 : 0.15 : 0.05
- Evaluation metrics (from T2M)
- FID, R-Precision, multimodal distance, Multimodality
- Implementation Details
- VQ-VAE(Motion Residual VQ-VAE)의 경우, 인코더(encoder)와 디코더(decoder) 모두 ResBlock을 사용하며, 다운스케일링 비율은 4.
- RVQ는 6개의 quantization layer으로 구성되어 있으며, 각 layer의 codebook은 512개의 512차원 codes를 포함
- quantization dropout 비율 =0.2
- Masked Transformer와 Residual Transformer는 각각 6개의 Transformer layer, 6개의 Attention Heads, 384차원의 latent dimension로 구성
- CFG scale
- HUMANML3D: MT에서 4, RT에서 5
- KIT-ML: MT에서 2, RT에서 5
- 반복 횟수 =10
Comparison to state-of-the-art approaches
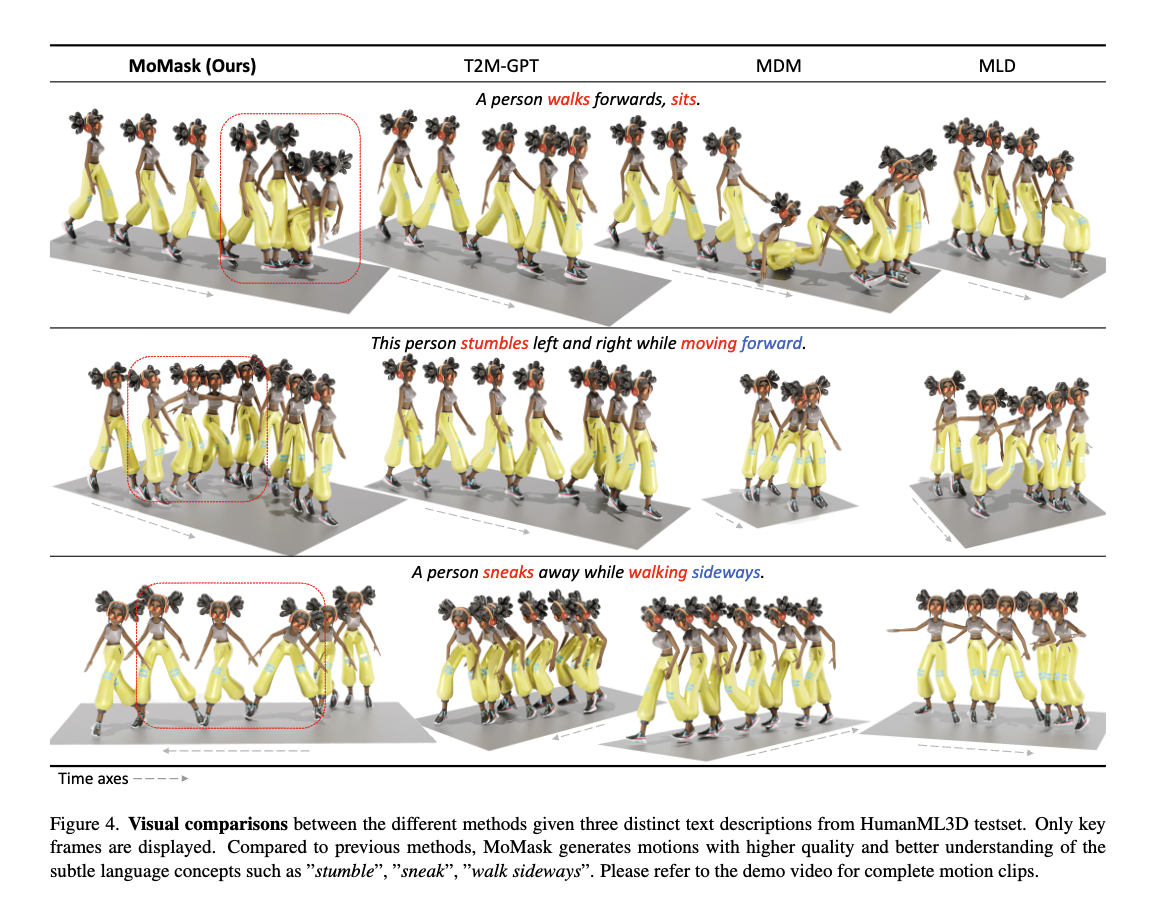

Application: Temporal Inpainting

Discussion and Conclusion (limitation)
- MoMask는 기존 텍스트-모션 생성 모델보다 우수한 성능을 보이며, 특히 적은 추론 횟수로도 높은 품질을 달성함.
- Residual Quantization을 활용하여 모션 세부 정보를 더 효과적으로 보존할 수 있음.
- 기존 Diffusion 모델보다 효율적이며, 추론 속도가 빠름.
- 그러나, 일부 경우에는 비정상적인 모션이 발생할 수 있으며, 복잡한 동작 표현에는 한계가 있음.
- MoMask는 텍스트-모션 생성의 새로운 접근법을 제시하며, 향후 연구에서 더욱 발전할 가능성이 높음.
