[논문] StableMoFusion: Towards Robust and Efficient Diffusion-based Motion Generation Framework
Motion Generation 논문 리뷰
요즘 텍스트-투-모션 관련 연구가 많긴 한데, 솔직히 결과물 보면 "음… 아직은 좀…" 싶은 경우도 많잖아요? 근데 이 논문의 결과는 조금 더 잘된다?는 느낌이였는데, 왜냐면요...거의 쓸 수 있는 방법을 다 갖다가 썼어요 ㅋㅋㅋㅋ 다른 논문들보면 너무 베이스라인을 플레인하게 잡아서 다른 연구들과 다른 본인들만의 방법을 돋보이게 하는 느낌이라면 이 저자들은 세상의 좋은 기술들을 어떻게 활용하는지 확실히 보여줬다랄까요 ㅎ
특히, 이번 논문에서 풋스케이팅(발 미끄러짐) 문제를 신경 써서 해결한 게 인상적이었어요. 저도 모션에 대해서 아직도 고민중인 부분이 연속된 데이터에서 생기는 발 미끄러짐 현상인데요. 그래서인지 더 눈이 가는 연구 였습니다.
https://arxiv.org/abs/2405.05691
https://github.com/h-y1heng/StableMoFusion
Introduction
diffusion을 이용한 text-to-motion 연구들이 나왔지만, 아래와 같은 문제들이 아쉬움이 있다고 합니다.
- 체계적인 분석 부족: 서로 다른 모델 구조와 학습 파이프라인으로 인한 다양한 방법 통합 불가
- 긴 추론 시간: 반복적인 샘플링으로 인한 지연
- 풋 스케이팅: 생성된 모션의 발이 미끄러지는 현상
그래서 저자들은 위의 문제들을 아래와 같은 방법들을 적용하여 해결했음을 주장합니다.
- denoising network로 Con1D UNet사용 및 AdaGN와 linear cross-attention 사용, 일반화 성능을 위한 GroupNorm 조정
- 학습 과정에서의 두가지 전략
- 추론 과정에서의 네가지 training-free acceleration trick
- mechanical model과 최적화를 이용한 footskate 문제 해결
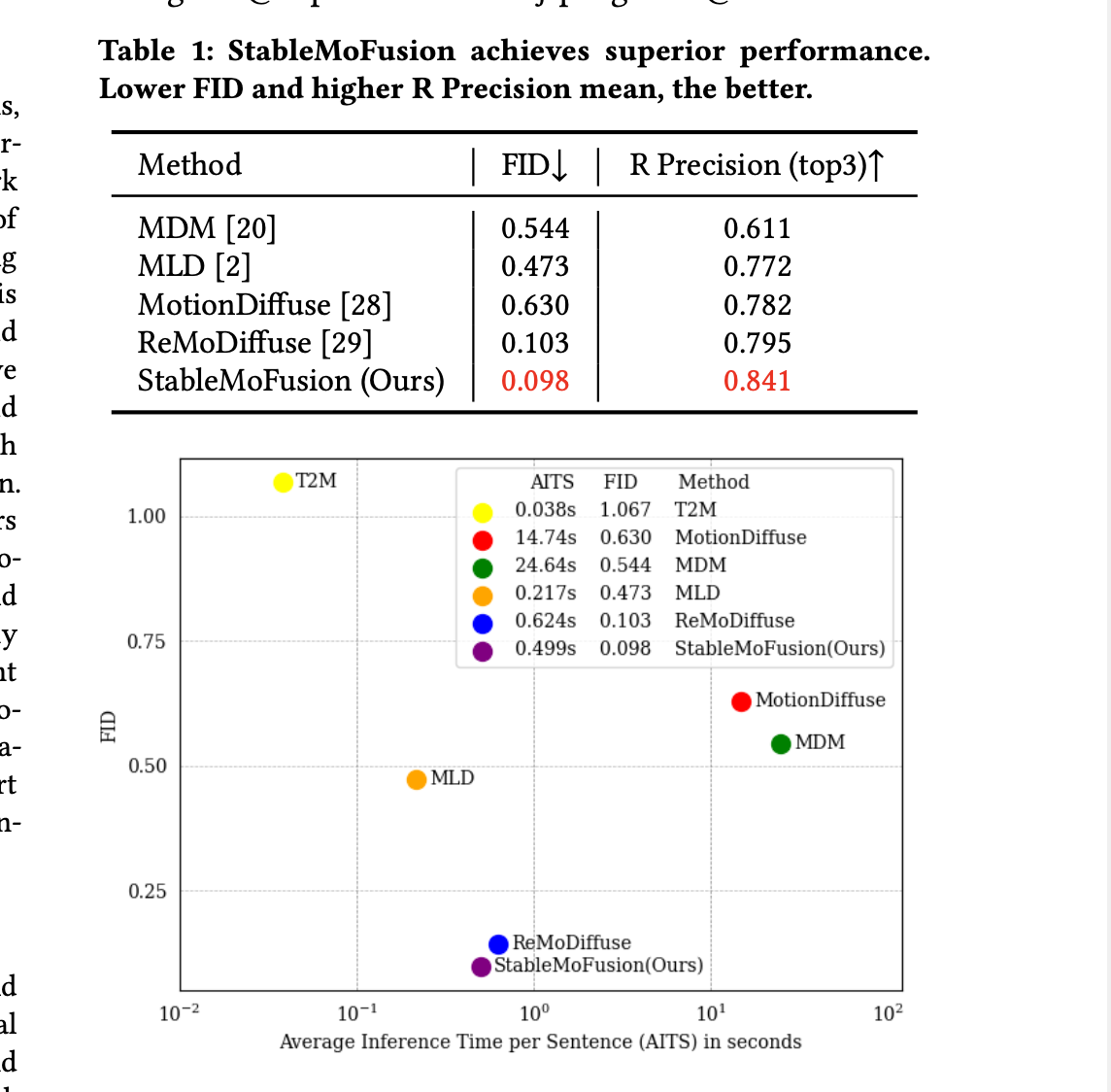
위와 같은 방식으로 StableMofusion은 일반적으로 1000번 하는 반복을 10회로 줄였고, 성능 또한 높았으며, 추론 시간은 0.5초(HumanML3D)의 성과를 보였습니다.
Method
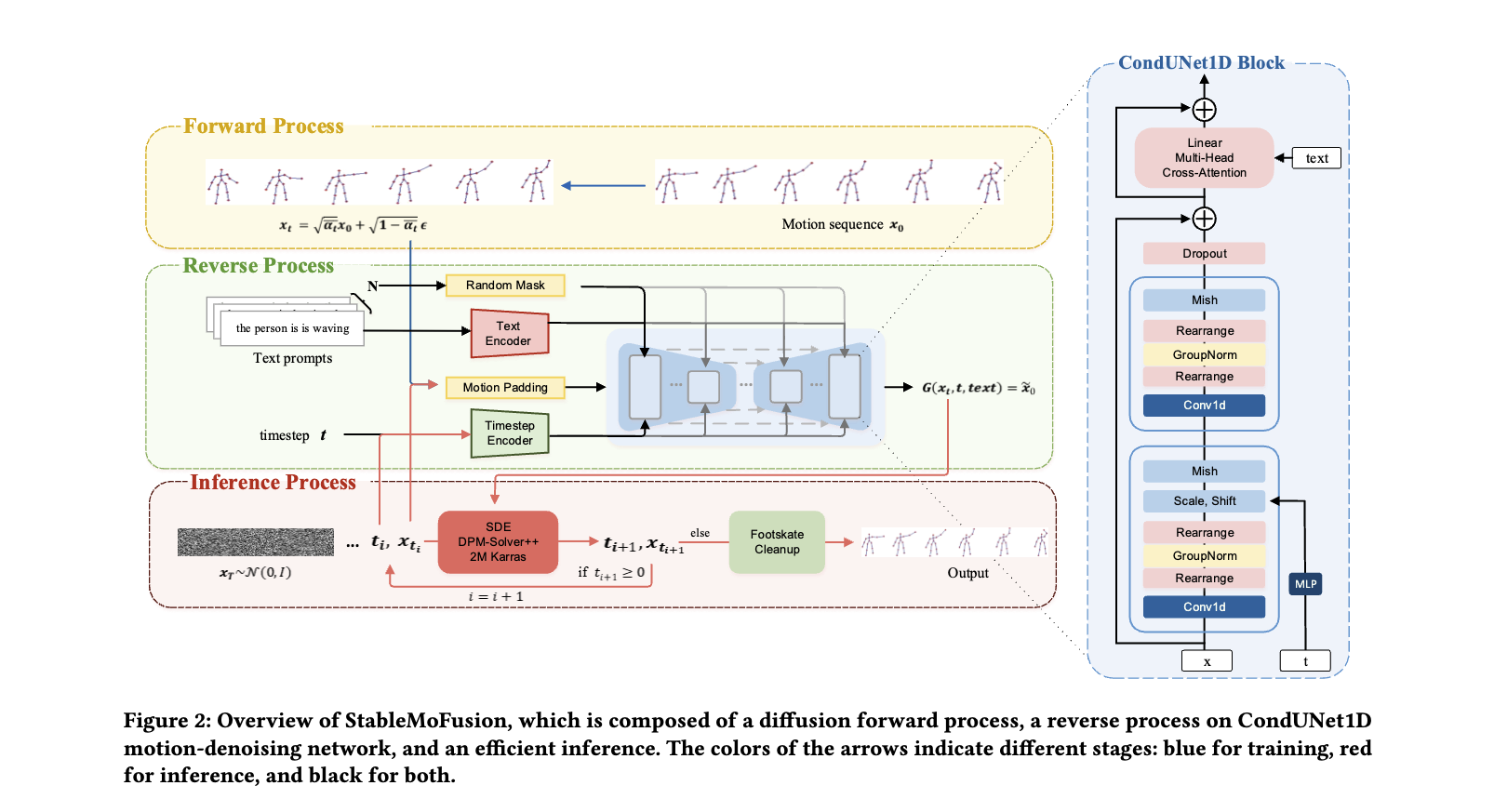
Model Architecture
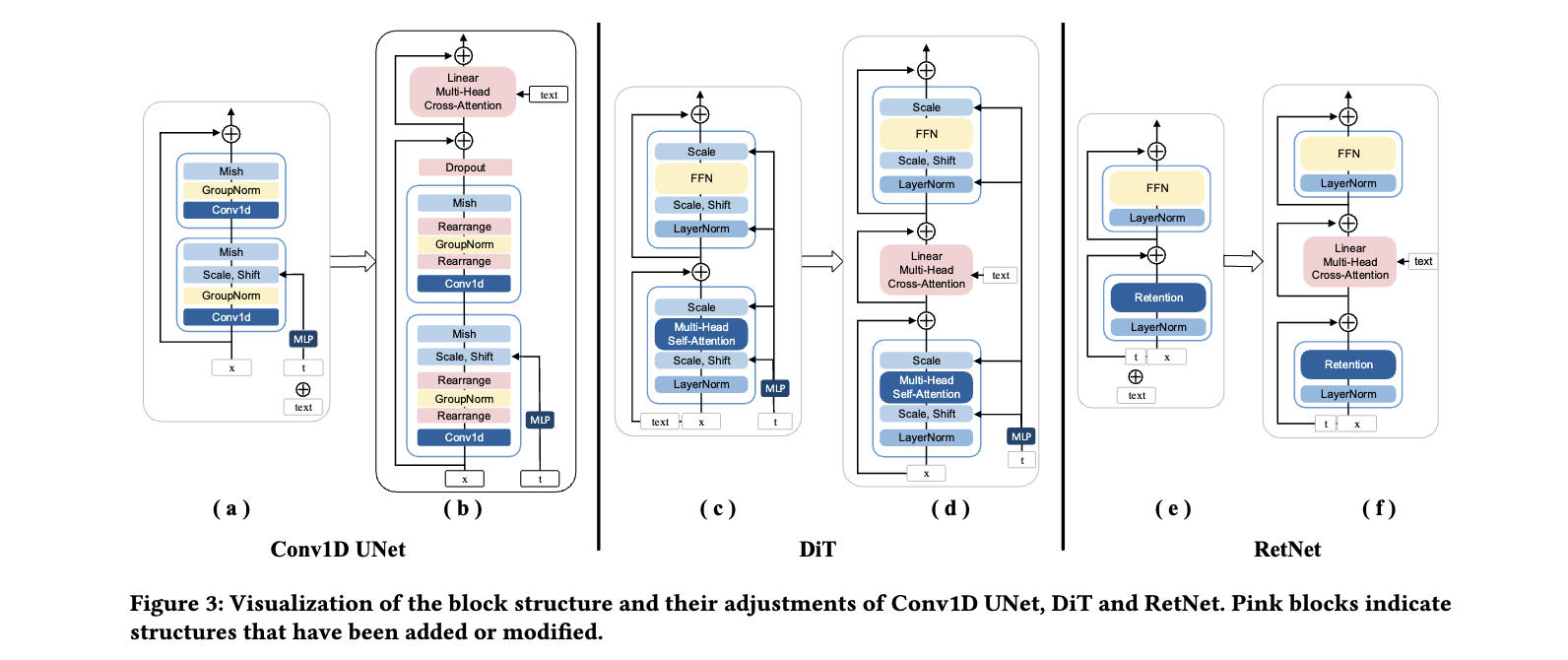
연구자들은 Conv1D UNet, Diffusion Transformer(DiT), Retent Network(RetNet)등의 motion denoising network들로 테스트들을 해봤다고 합니다.
Conv1D UNet
- Baseline
- AdaGN 적용
- UNet 사용의 장점:
- UNet의 skip connections과 layer-by-layer reconstruction: 시공간적 세부 정보 유지
- 다양한 스케일에서 feature 복원과 추출을 통한 현실적인 모션
- 모션 적용 과정
- Conv1D 블록에서, CLIP으로부터 얻은 sentence-level textural embedding 은 feature-wise linear modulation (FiLM)을 위해 timestep에 따라 scale과 shift값으로 projection된다.
- : 번째 프레임의 pose embedding
- 각 프레임의 pose embedding에 대한 일관된 condition-based linear mapping을 의미
- 노이즈가 있는 모션에 타임스텝을 적용한 경우 디노이즈에는 적합하지만, timestep이 일정하면 제한되어 각 프레임이 텍스트 문장에서 다른의미를 가지는 경우 제한됨
- Conv1D 블록에서, CLIP으로부터 얻은 sentence-level textural embedding 은 feature-wise linear modulation (FiLM)을 위해 timestep에 따라 scale과 shift값으로 projection된다.
- Block Adjustment(일반 conv1D block에 특정 효과를 위해 layer 추가)
- 모션 임베딩(Query)과 단어 수준의 의미(Key 및 Value) 정렬을 위한 Conv1D에 Residual Cross-Attention 추가
- Dropout 추가
- baseline에서 사용된 sentence-level의 embedding외에도, word-level의 text embedding을 CLIP같은 추가 transformer를 적용하여 모션관현 표현으로 정제
- GroupNorm Tweak
- motion embedding의 dimension을 재배열(rearrange)하여 feature-wise Group Normalization 가능
- 재배열 비유
- Conv1D의 sequence dimension에 따른 convolution으로 인해, outputdp 바로 group normalization을 적용하는 것은 sequence-wise normalization을 의미하며, 이 방식은 sequence padding의 비율에 예민.
- 결좌적으로, 다양한 모션 길이를 포한하는 KIT-ML 데이터에서 패딩의 영향이 생기게되고 baseline의 성능이 크게 저하되는 문제 발생
Diffusion Transformer (DiT)
- Baseline
- 이미지 처리를 위한 Vision transformer는 제거, self-attention 적용
- CLIP을 이용해 얻은 text prompt embedding과 motion embedding 결합 후 Self-Attention에 입력
- autoregressive computation 전후에 timestep을 이용하여 motion embedding에 scale과 shift
- motion-denoising 과정이 timestep과 잘 정렬되도록 보장
- Block Adjustment
- Linear Multi-Head Cross-Attention을 통합
- (text 정보를 1D text embedding으로 변환하는 방식 보다) text 정보를 motion dynamics와 잘 융합되도록 하기때문에, motion sequence의 일관성과 text의 연관성이 향상됨
Retentive Network (RetNet)
- Baseline
- (MDM과 유사) timestep encoding을 text projection과 결합하여 token 생성 후, motion embedding을 RetNet에 적용
- RetNet
- gate가 적용된 multi-scale 유지(retention) 방식으로 정보 유지 및 처리능력을 가지고 motion sequence 생성능력 향상
- Block Adjustment
- RetNet의 retention과 FFN(Fully Connected Feedforward Network) 사이에 Linear Multi-Head Cross-Attention 추가
- 시간적 feature와 text feature를 분리하여 처리하여, 각 modality의 고유 특성 유지
- model이 motion 생성에 대한 정보를 독립적으로 학습 및 활용 가능
- model의 interpretability와 flexibility 향상, temporal dynamics와 semantic context의 관계 포착 성능 향상
Final Model Architecture
- 최종 선택: CondUNet1D = Conv1D UNet + Block Adjustment + GroupNorm Tweak
- DiT와 RetNet 선택하지 않은 이유
- 트렌드가 빠르고 부드러운 motion에 대한 우선순위가 높아서
- DiT는 텍스트-모션 일관성이 좋긴 하지만, 너무 계산량이 많고, 실시간으로 빠르게 모션을 생성하기 어려움
- RetNet은 부드러운 모션을 만드는 데 강하지만, 모션이 너무 정형화되고 변화에 적응하기 어려움
- DiT와 RetNet 선택하지 않은 이유
Training Strategies
Exponential Moving Average
- 모델 가중치의 가중 평균(weighted average)을 계산하는 방식으로, 최근 데이터에 더 큰 가중치를 부여
- : 시점에서의 EMA 가중치
- : 과거 가중치의 중요도를 조절하는 계수 (일반적으로 0.99와 같은 값)
- : 현재 시점에서의 모델 가중치
- 부드러운 가중치 업데이트를 통한 안정성 증가, 급격한 변동 감소를 통한 학습 모션의 일관성 향상
Classifier-Free Guidance
- condition 유무를 상관하지 않도록 하는 방법
- $G (x_t, t, c) $: 조건이 주어진 경우(텍스트 입력이 있는 경우) 모델의 디노이징 결과
- : 조건이 없는 경우(텍스트 입력 없이 학습된 경우) 모델의 디노이징 결과
- : 조건의 영향을 조절하는 계수 (값이 클수록 텍스트-모션 일관성이 증가)
- 추론 과정에서 텍스트-모션 일관성과 모션 Fidelity 간의 균형을 조절
Efficient Inference
저자들의 연구는 효율적인 추론시간을 위해 다음과 같은 기법들을 적용했습니다.
Efficient Sampler
- denoising 반복 횟수를 줄이기 위한 DPM-Solver++ 사용
- Stochastic Differential Equations을 풀기 위한 hig-order solver인 second-order DPM-Solver의 SDE 변형 적용
- 반복적인 샘플링과정에 추가 노이즈 도입을 통한 누적 오류 감소 () 모션의 realism 향상
- Karras Sigma방식의 이산적 timestep 설정
- constant-velocity thermal diffusion 이론을 활용한 최적의 timestep 결정
- 주어진 반복 횟수내에서 motion denoising의 효율성을 극대화
Embedded-text Cache
- 추론 과정에서 불필요한 연산을 줄이는 기법
- denoising에서 매번 사용되는 텍스트 임베딩을 저장된 상태로 사용
Parallel CFG Computation
- CFG 추론과정의 병렬화
- conditional과 unconditional 과정을 병렬로 수행
Low-precision Inference
- FP16 변환으로 연산량, 파라미터 크기, 메모리 사용량 감소
Footskate Reduction
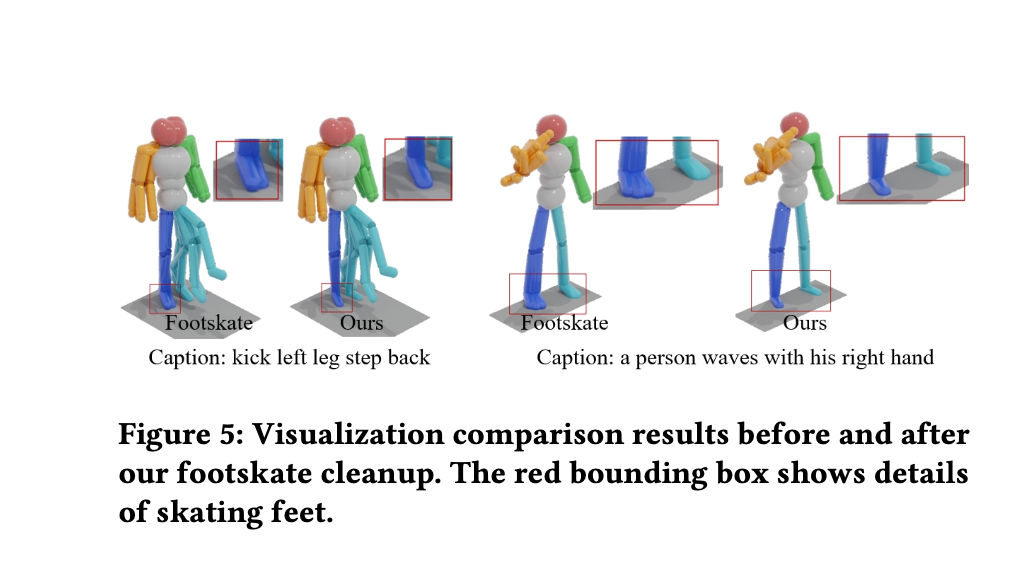
모션 캡쳐를 포함하여 최신 모션 연구들을 보면 포즈를 추론하는 것은 정말 잘하는데요. 정말 정밀한 모션 캡쳐 결과를 원하는 전문 회사가 아닌 이상 자연스러운 모션 결과에 대한 수요가 훨씬 많습니다. 그 중하나가 foot lock, foot skate reduction입니다. 발이 미끄러지는게 마치 허우적?하는 느낌인데, 이게 아주 거슬립니다... 그런데, 이런 유저 중심적 문제를 고려했다는 것이 너무나 존경스럽습니다...
- foot skating이 발생하는 foot joint와 해당 frame을 골라 그 중간 프레임에서 해당 joint의 위치 를 기준점으로 설정하여 움직이 않도록 고정
- : foot skating이 발생할 수 있는 모든 관절(right ankle, right toes, left ankle, and left toes)
- UnderPressure 연구를 베이스로 vertical ground reaction
forces (vGRFs) 사용하여 풋스케이팅이 발생하는 발 관절 과 해당 프레임 를 식별- vGRFs 예측 모델 은 23개 joint 필요하지만 사용 데이터셋과 다름 (HumanML3D: 22, KIT-ML: 21)
- 다음 방식처럼 pretrained 의 weight를 에 전이
- : HumanML3D 데이터셋을 위한 새로운 vGRFs 예측 모델
- : 기존 UnderPressure 모델의 vGRFs 예측값
- : HumanML3D의 키포인트(foot joint)
- : 관절 시스템에서의 리타겟팅(retargeting) 결과
- LOSS
- Diffusion 모델 기반 추가 보정
- 일부 보정된 모션에서 비정상적인 자세 발생 가능
- 사전 학습된 Diffusion 모델을 활용하여 자동 보정
- UniControl 및 PhysDiff 기법 참고하여 모션 디노이징 프로세스 개선
Experiments
Dataset and Evaluation Metrics
- dataset: HumanML3D, KIT-ML
- Evaluation Metrics:
- Motion Realism: FID
- Text match: R Precision
- Generation diversity: Diversity, Multi-modality
- Time Cost: Average Inference Time per Sentence (AITS)
Implementation Details
- 학습
- denoising step = 1,000
- : 0,0001에서 0.02까지 선형 증가
- AdamW, lr=0.0002, wd=0.01, iter=50,000, batchsize:64, GPU: A100 1대
- 추론
- DPM-Solver++ => 10 단계 샘플링
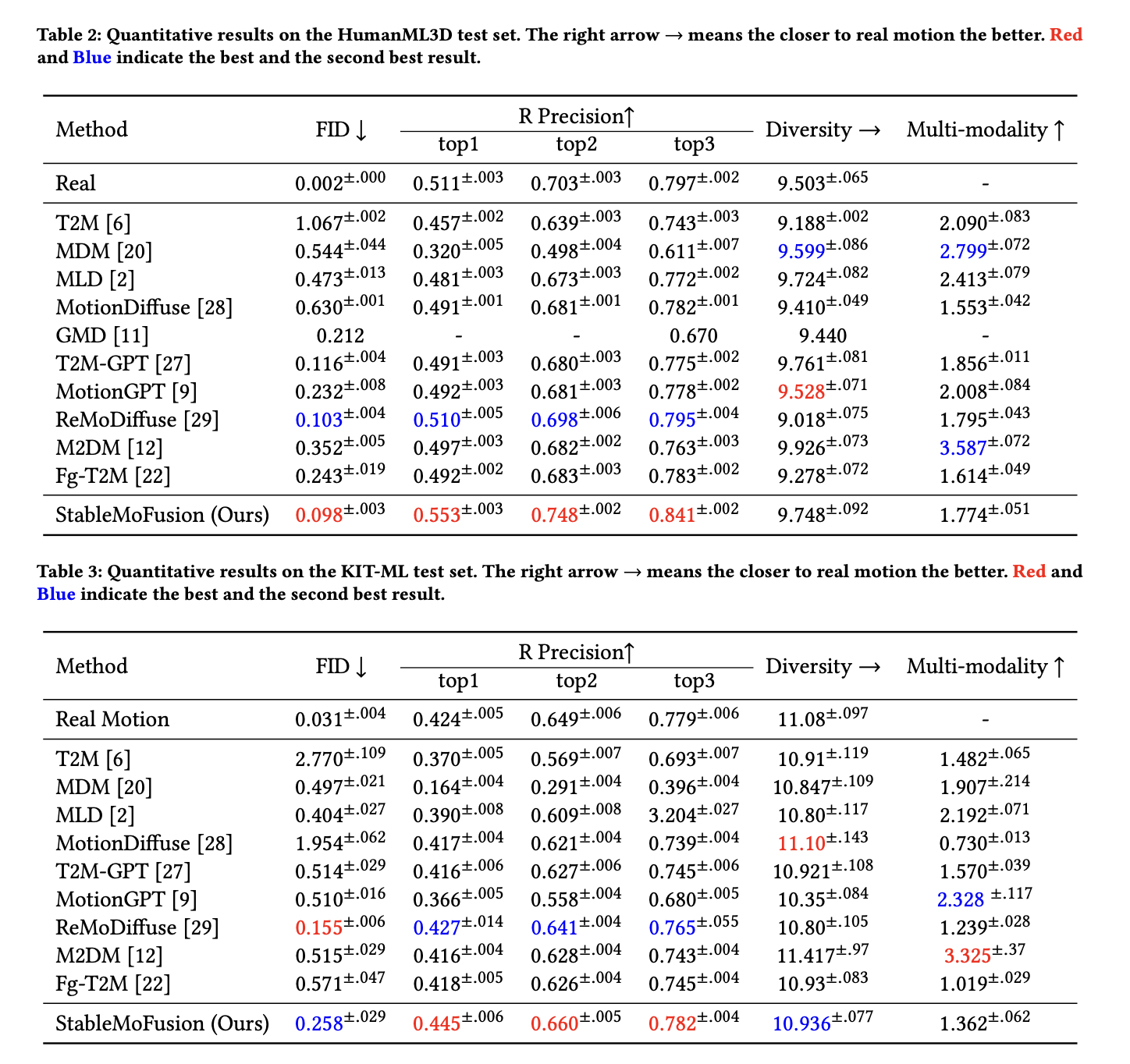
Quantative Results
Qualitative Result
Ablation Study