Kaggle Courses
1.[Intro to Machine Learning] 기계학습 소개(Intro to Machine Learning)

이 글은 출처를 번역한 글입니다. 저작권에 문제가 있을시에 바로 삭제하겠습니다. Introduction 이글은 우선 machine learning model이 어떻게 작동되고 사용 되는지에 대한 개요로 시작하고자 합니다. 이전에 statistical modeling
2.[Intro to Machine Learning] 데이터 탐색 기초 (Basic Data Exploration)
이 글은 Kaggle Coueses 이글을 해석한 글입니다. Pandas를 이용하여 당신의 데이터를 탐색해 보세요 Machine leaning 프로젝트에서 첫 step은 데이터와 친숙해지는 것입니다. 당신은 아마 이를 위해 Pandas library를 이용할 것입니다
3.[Intro to Machine Learning] 첫 머신러닝 모델 (Your First Machine Learning Model)
이 글은 Kaggle Courseㄴ의 내용을 번역한 글입니다. 출처 모델링을 위한 데이터 선택 데이터셋에 변수가 너무 많아 데이터 셋을 이해하거나 또는 데이터를 출력하는데 어려움이 있을 수 있습니다. 어떻게하면 이 많은 양의 데이터를 이해할 수 있는 형태로 줄일 수
4.[Intro to Machine Learning] 모델 검증(Model Validation)
이 글은 Kaggle Coureses-출처를 번역한 글입니다.모델은 완성됐습니다. 그렇다면 성능은 어느정도 일까요?이번 강의에서는, 모델의 성능을 측정해서 모델을 검증하는 방법에 관해 배울것입니다. 모델의 성능을 측정하는 것은 모델를 개선하는데 있어서 중요한 부분입니다
5.[Intro to Machine Learning] 과소적합 & 과적합 (Underfitting and Overfitting)
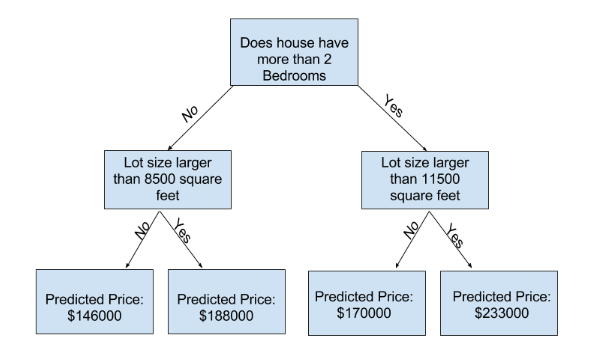
이 글은 Kaggle Course - 출처이 글을 번역한 글입니다.이번에는 과소적합(Underfitting)과 과적합(Overfitting)에 관해 얘기해보겠습니다. 이 개념을 model에 적용하여 더욱더 정확한 model을 만들 수 있습니다.이제 우리는 모델의 정확도
6.[Intro to Machine Learning] 랜덤포레스트(Random Forests)
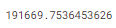
이 글은 Kaggle Course의 Random Forests를 번역한 글입니다.Decision tree는 많은 leaves를 가질 경우, 각 leaf에서의 예측값은 적은 수의 집 값 데이터를 이용하여 만들어진 값이기 때문에 과적합(Overfitiing) 되는 경향이
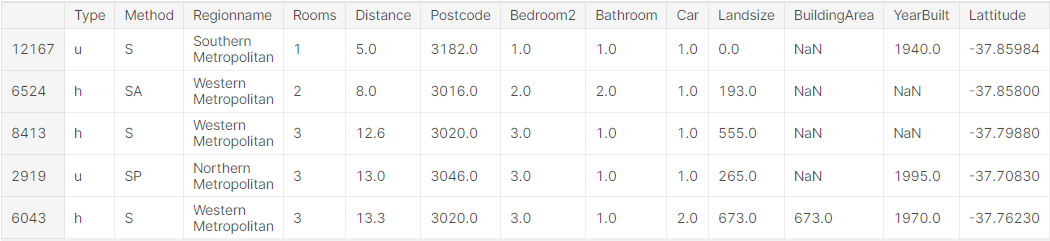
7.[Intermediate Machine Learning] 결측값(Missing Values)

이글은 Missing Values를 번역한 글입니다.이번에는 결측값(Missing Values)를 다루는 방법들을 배울것입니다. 이 방법들을 실제 데이터셋에 적용하여 결과를 비교할 수 있을것입니다.데이터는 여러 이유로 결측값을 갖게 됩니다. 예로,침실이 2개인 집은 세
8.[Intermediate Machine Learning] 범주형 변수(Categorical Variables)
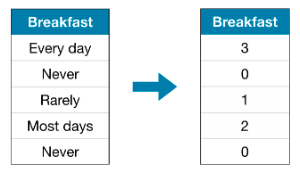
이글은 (Categorical Variable)https://www.kaggle.com/code/alexisbcook/categorical-variables을 번역한 글입니다.이번에는 범주형 변수(Categorical Variables)가 무었인지, 어떻게 범
9.[Intermediate Machine Learning] 파이프라인(Pipelines)
이 글은 Kaggle Courses에 있는 Pipelines 글을 번역한 것입니다.이번에는 pipelines(파이프라인) 을 사용하여 모델링 코드를 깔끔하게 하는 방법을 배우겠습니다.Pipelines은 데이터 처리와 모델링 코드를 깔끔하게 관리할 수 있게 해주는 간단한
10.[Intermediate Machine Learning] 교차검증(Cross-Validation)
이글은 Kaggle Courses에 Cross-Validation을 번역한 글입니다. 이번에는 모델 성능의 정확한 측정을 위한 교차검증(Cross-validation)에 대해 배우겠습니다. Introduction 머신러닝은 반복정인 과정입니다. 어떤 예측 변수를
11.[Intermediate Machine Learning] XGBoost
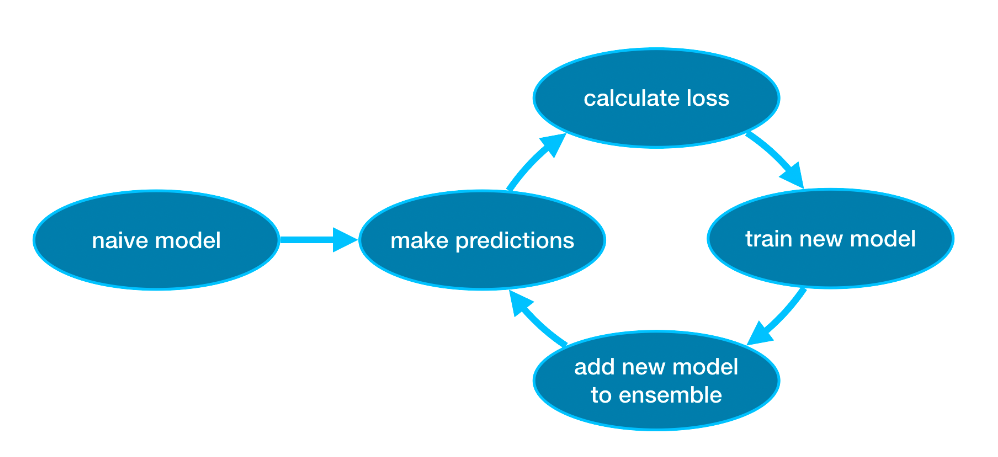
이 글은 kaggle courses XGboost를 번역한 글입니다. 이번 강의에서는 gradient boosting 모델을 어떻게 만들고 최적화 하는지에 대해 배울것입니다. 이 모델은 kaggle competitions에서 주로 이용되는 방법이고 다양한 데이터셋에서