이 글은 Kaggle Courseㄴ의 내용을 번역한 글입니다. 출처
모델링을 위한 데이터 선택
데이터셋에 변수가 너무 많아 데이터 셋을 이해하거나 또는 데이터를 출력하는데 어려움이 있을 수 있습니다. 어떻게하면 이 많은 양의 데이터를 이해할 수 있는 형태로 줄일 수 있을까요?
우선 직관을 이용해 몇개의 변수만 선택해 보겠습니다. 추후의 과정에서는 통계적인 기술을 이용하여 자동으로 중요한 변수들을 선택하는 법을 다룰 것입니다.
변수/컬럼(variable/columns)를 선택하기 위해 우선 데이터셋에 존재하는 모든 컬럼의 리스트를 봐야합니다. 이는 DataFrame의 columns의 성질을 이용하여 볼 수 있습니다.
import pandas as pd
melbourne_file_path = '../input/melbourne-housing-snapshot/melb_data.csv'
melbourne_data = pd.read_csv(melbourne_file_path)
melbourne_data.columns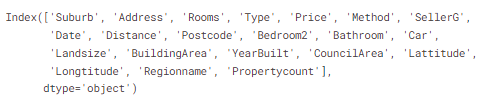
# 결측치가 있는 데이터를 제거합니다.
melbourne_data = melbourne_data.dropna(axis=0)데이터의 subset(일부분)을 선택하는 방법은 여러가지가 있습니다. 여기서는 2가지 방법만 다룰 예정입니다. 다른 방법은 Pandas course에서 다루고 있으니 참고 바랍니다.
1. Dot notation으로, 이를 이용해 "prediction target"을 선택합니다.
2. Column 리스트를 선택하는 방법으로, 이를 이용해 "features"를 선택합니다.Selecting The Prediction Target
dot notation을 이용해 변수를 불러올 수 있습니다. 이 한개의 column은 Series에 저장 되고, 이는 하나의 column 데이터만 존재하는 DataFrame과 같습니다.
Dot notation을 이용하여 우리가 예측할 column을 선택할 것이며 이를 Prediction target이라 부르겠습니다. 일반적으로 prediction target은 y라고 합니다. 그래서 Melbourne data의 집가격을 저장하기 위해 필요한 코드는 다음과 같습니다.
y = melbourne_data.PriceChoosing "Features"
모델에 들어가는 column들을 "features"라고 부릅니다. 우리의 예시에서는 집값 예측을 위한 컬럼이 features에 해당할 것입니다. 때로는 target을 제외한 모든 column을 features로 사용할 수도 있습니다. 또는 더 적은 feature를 사용하는 것이 좋은 결과를 보여줄 때도 있습니다.
지금까지, 우리는 몇개의 features만 이용하여 모델을 만들었습니다. 추후에 다른 feature들을 이용해 만들어진 모델들을 어떻게 비교하는지에 대해 알아볼 것입니다.
대괄호 안에 column 이름의 리스트를 이용하여 여러개의 feature를 선택할 것입니다. 리스트안에 있는 각 항목은 문자열 이여만 합니다. 예시는 다음과 같습니다.
melbourne_features = ['Rooms', 'Bathroom', 'Landsize', 'Lattitude', 'Longtitude']일반적으로, 이러한 데이터는 X라고 부릅니다.
X = melbourne_data[melbourne_features]describe와 head를 이용하여 이용하여 우리가 집값예측에 사용할 데이터를 빠르게 한 번 살펴봅시다.
X.describe()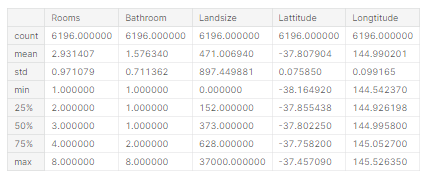
X.head()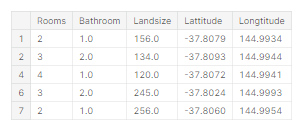
이러한 명령어로 데이터를 눈으로 보는것은 data science에서 중요한 부분입니다. 이를 통해 데이터의 어떤 부분을 더 살펴봐야하는지를 종종 알 수 있습니다.
우리의 모델 만들기
scikit-learn library를 이용하여 model을 만들 수 있습니다. 코딩을 할 때, 이 library는 sklearn으로 적어 사용합니다. Skcikit-learn은 DataFrame에 저장된 데이터들을 이용해 쉽게 모델링을 할 수 있게 해주는 가장 유명한 library 입니다.
모델을 만들고 사용하는 과정은 다음과 같습니다:
- **Define(정의)**: 어떤 종류의 모델인지? Decision tree? 아님 다른 다른 종류의 모델? 또한 모델 종류에 따른 Parameter 또한 명시되어야 합니다.
- **Fit(적합)**: 제공된 데이터로 부터 pattern 파악. 이는 모델링에서 가장 중요한 부분입니다.
- **Predict(예측): 말그대로 target(Y)를 예측
- **Evaluate(평가)**: 모델의 예측이 얼마나 정확한지 파악scikit-lear을 이용해 decision tree 모델을 정의하고 feature와 target 변수를 이용해 적합시키는 코드의 예시는 다음과 같습니다.
from sklearn.tree import DecisionTreeRegressor
# 모델을 Define(정의)하고 매번 동일한 결과를 얻기위해 random_state의 숫자를 명시해 줍니다.
melbourne_model = DecisionTreeRegressor(random_state=1)
# 모델 적합
melbourne_model.fit(X, y)
많은 머신러닝 모델들은 training(훈련)과정에서 randomness(무작위성)을 갖고 있습니다. random_state를 명시함으로써 매번 학습시(동일한 데이터로)에 동일한 결과를 얻을 수 있습니다. 이는 좋은 관행으로, 어떤 값을 사용하는냐에 따라 모델의 성능은 유의미하게 달라지지 않을것입니다. - (1)
이제 우리는 우리는 fitted(적합된) model을 갖고 있고, 이를 이용해 prediction(예측)을 할 수 있습니다.
실전에서는 당신은 우리가 이미 집가격을 알고 있는 집(Training data)이 아닌 실제 새로운 집들에 대한 가격을 예측하기 원할 것입니다. 그러나 여기서는 prediction이 어떻게 이뤄지는지 보기위해 training data의 몇개의 row만 이용하여 예측을 해보겠습니다.
print("Making predictions for the following 5 houses:")
print(X.head())
print("The predictions are")
print(melbourne_model.predict(X.head()))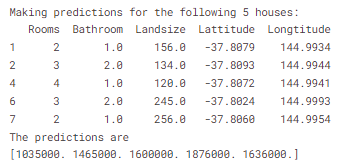
Your Turn
Model Building Exercise 이용해 연습해보세요
사족
(1) 이 부분에 대해서는 개인적인 의견으로 맞기도 하고 틀리기도 할 수 있다고 생각됩니다. 실제로 kaggle에서는 seed마다 약간의 모델 성능이 달라지는 것을 이용하여 seed ensemble이라는 테크닉으로 모델의 성능을 올리기도 합니다. 따라서 데이터, 그리고 모델에 따라 실험 및 결과로 확인해야 하는 부분이 아닐까 생각합니다.
