이 글은 Kaggle Coureses-출처를 번역한 글입니다.
모델은 완성됐습니다. 그렇다면 성능은 어느정도 일까요?
이번 강의에서는, 모델의 성능을 측정해서 모델을 검증하는 방법에 관해 배울것입니다. 모델의 성능을 측정하는 것은 모델를 개선하는데 있어서 중요한 부분입니다.
모델 검증은 무엇인가?
여러분은 모델을 만들때 마다 매번 모델을 평가하기를 원할 것입니다. 대부분의 경우에 모델 성능을 측정하는 방법은 예측값의 정확도 입니다. 즉, 모델의 예측값이 실제값과 얼마나 비슷한가를 의미합니다.
많은 사람들은 학습 데이터(training data)를 이용하여 예측하고, 이 예측된 값을 학습데이터의 목적 변수(target values)와 비교하여 모델의 예측 정확도를 측정하는 실수를 저지르곤 합니다. 여기서는 이 접근법의 문제를 보고 이를 어떻게 해결하는지 살펴볼 것입니다.
우선 모델의 성능을 이해할 수 있는 방법으로 정리해야 합니다. 만약 당신이 10000개의 예측된 집가격과 실제 집가격 값을 비교한다면, 예측이 잘 된 경우와 예측이 많이 벗어난 경우들이 존재할 것 입니다. 10,000개의 예측값과 실제 값을 일일이 살펴보는 것은 무의미 하기 때문에 이것을 하나의 평가 지표로 정리해야 합니다.
모델의 성능을 측정하는 평가지표는 여러개가 있습니다. 여기서는 우선 평균 절대 오차(Mean Absoulte Error, MAE)를 살펴보겠습니다. 이 평가지표를 오차(error)라는 의미부터 파악해보겠습니다.
각 예측된 집값의 예측 오차(prediction error)는 다음과 같습니다.
오차(error) = 실제 값(actural) - 예측 값(predicted)만약 집가격이 $150,000이고 에측된 값이 $100,000이면 오차는 $50,000입니다.
MAE 평가지표를 이용하여, 각 오차의 절대값을 계산하겠습니다. MAE는 모든 오차를 양수로 바꾸고 이 바뀐 오차들의 평균을 계산합니다. 이것이 모델의 성능을 측정하는 방법이고 이를 문장으로 표현하면 다음과 같이 표현 될 수 있습니다.
평균적으로 예측값은 X정도 벗어나 있습니다.
MAE를 계산하려면 우선 모델이 필요합니다. 아래의 코드로 모델을 만들겠습니다.
# data load
import pandas as pd
# 데이터 불러오기
melbourne_file_path = '../input/melbourne-housing-snapshot/melb_data.csv'
melbourne_data = pd.read_csv(melbourne_file_path)
# 결측치제거
filtered_melbourne_data = melbourne_data.dropna(axis=0)
# target값과 feature 선택
y = filtered_melbourne_data.Price
melbourne_features = ['Rooms', 'Bathroom', 'Landsize', 'BuildingArea',
'YearBuilt', 'Lattitude', 'Longtitude']
X = filtered_melbourne_data[melbourne_features]
from sklearn.tree import DecisionTreeRegressor
# Define model
melbourne_model = DecisionTreeRegressor()
# Fit model
melbourne_model.fit(X, y)모델을 만들었다면 이를 이용해 평균 절대 오차(MAE)를 계산하겠습니다.
from sklearn.metrics import mean_absolute_error
predicted_home_prices = melbourne_model.predict(X)
mean_absolute_error(y, predicted_home_prices)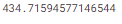
훈련 데이터로 모델 성능을 측정하는 것의 문제
방금 계산한 모델의 평가 지표는 "in-sample" score라고 할 수 있습니다. 여기서 집 가격 데이터의 하나의 표본을 모델을 만드는데도 사용하고 그것을 평가하는데도 사용하였습니다. 이것이 잘못된 이유입니다.
실제로 부동산 시장에서 문의 색은 집의 가격과 상관이 없다고 상상해 보십쇼.
그러나 모델을 만들 때 사용한 데이터의 표본에는, 초록색 문을 가진 모든 집은 매우 비싸다고 가정해봅시다. 모델이 하는 일은 집값에 영향을 주는 패턴을 찾아내는 것이고, 초록색 문이 집의 가격에 중요한 영향을 미친다고 판단하게 되어 초록색 문을 가진 집은 모델이 집의 가격이 크도록 예측할 것입니다.
이러한 패턴은 학습데이터로 부터 파악된 것이므로 모델은 학습데이터에서는 높은 예측 정확도를 보일 것입니다. 그러나 이러한 패턴은 새로운 데이터에 대해서는 보이지 않는다면 모델의 예측은 매우 부정확할 것입니다.
모델의 실제 예측값은 새로운 데이터에 대해서 이뤄질 것이기 때문에, 우리는 모델의 학습에는 사용되지 않은 데이터를 이용하여 모델 성능을 측정해야 합니다. 가장 직관적인 방법으로는 모델을 만드는 과정에서 학습 데이터의 일부를 제외하여 모델의 정확도를 이 제외된 데이터로 평가하는 것입니다. 이러한 데이터를 검증 데이터(validation data)라고 부릅니다.
Coding
Scikit-learn library에는 train_test_split 함수를 이용하여 data를 2개의 집단으로 나눌 수 있습니다. 데이터의 일부는 학습데이터로 이용하여 모델을 만들어 적합 시킬 것이고 나머지 데이터는 검증 데이터로 이용하여 mean_absolute_error를 계산 할것입니다.
code
from sklearn.model_selection import train_test_split
# features와 target 데이터를 학습데이터와 검증 데이터로 나누어줍니다.
# split은 random number generator에 기반합니다.
# random_state인자는 매번 이 스크립트를 실행할 때마다 동일한 split을 얻도록 해줍니다.
train_X, val_X, train_y, val_y = train_test_split(X, y, random_state = 0)
# Define model
melbourne_model = DecisionTreeRegressor()
# Fit model
melbourne_model.fit(train_X, train_y)
# 검증 데이터에 대하여 예측된 집가격을 얻습니다.
val_predictions = melbourne_model.predict(val_X)
print(mean_absolute_error(val_y, val_predictions))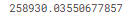
Wow!
학습데이터의 예측값으로 계산한 MAE는 약 500 $ 였습니다. 그러나 검증데이터의 예측값으로 계산한 MAE는 250,000 $ 보다 큰 값입니다. 참고로 검증 데이터의 평균 집가격은 110만$ 입니다. 따라서 새로운 데이터(검증데이터)에서의 오차는 평균 집 가격의 약 4분의 1입니다.
예측에 중요한 feature를 찾거나 아니면 다른 모델을 사용해서 모델을 좀 더 개선할 수 있습니다.
Your Turn
