이 글은 Kaggle Course - 출처이 글을 번역한 글입니다.
이번에는 과소적합(Underfitting)과 과적합(Overfitting)에 관해 얘기해보겠습니다. 이 개념을 model에 적용하여 더욱더 정확한 model을 만들 수 있습니다.
다른 모델들을 이용한 실험
이제 우리는 모델의 정확도를 신뢰할 수 있는 방법으로 측정할 수 있으므로, 다른 모델들의 예측 결과를 비교하면서 가장 좋은 모델을 선택할 수 있습니다.
Scikit-learn의 documentation을 보면 Decision tree 모델은 많은 option을 갖고 있습니다. 가장 중요한 option은 tree의 깊이 (tree's depth) 입니다. tree의 깊이는 예측 전에 얼마나 많은 split(분기점)을 만들지를 나타내는 수치입니다. 상대적으로 낮은 깊이의 tree의 예시는 다음곽 같습니다.
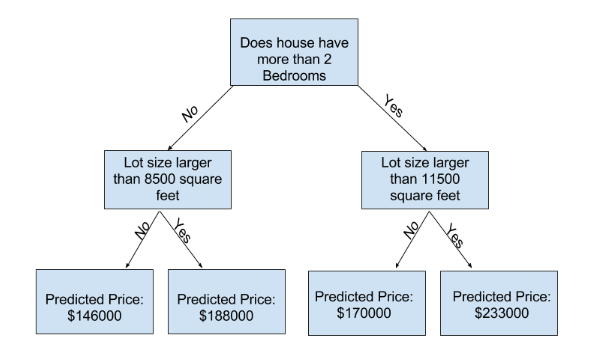
실전에서는, tree가 10개 이상의 split을 갖는 것은 흔한 일이 아닙니다. tree가 깊어질 수록 데이터셋이 더 적은 집의 집합 나눠져서 leaves에 들어가게 됩니다. 만약 tree가 한 개의 split만 존재한다면, 이건 데이터셋을 2개의 그룹으로 나눈것입니다. 만약 각 그룹이 또 split(분기)한다면 데이터셋을 4개의 그룹으로 나눈 것입니다. 만약 또 각각의 그룹을 또 split한다면 8개의 그룹이 만들어집니다. 만약 각 수준(level)에서 더 많은 split을 통해 계속해서 group을 2배씩 늘려가면, 10번째 수준(level)에서 개의 그룹을 갖게 될것입니다.
split을 많이 만들어 집의 그룹을 많이 나눈다면, 각 leaf에 속한 집의 개수는 작아질 것입니다. leaf에 들어가 있는 집의 수가 작아질수록 집값의 예측값은 실제 집값에 더 가까워질것 입니다. 하지만 새로운 데이터에는 신뢰하지 못할 예측 결과를 만들어 낼 수 있습니다.(왜냐하면 각 leaf에서의 예측된 집값은 적은 수의 집 값 데이터로 만들어진 예측이기 때문입니다) 모델의 예측 결과가 훈련 데이터(training data)에는 완벽히 들어 맞으나 그러나 검증 데이터(validatio data) 또는 새로운 데이터에는 예측 결과가 잘 맞지 않을 때, 이런 현상을 과적합(overfitting)이라고 부릅니다.
반대로 tree의 길이를 얕게 만든다면 집은 어떤 뚜렷한 집단으로 나뉘지 않을 것입니다. 예로 만약 tree가 집을 2 or 4개의 그릅으로 나눈다면 각 그룹은 여러 종류의 집을 포함하고 있을것입니다. 이런 경우 심지어 학습데이터에서 집값의 예측값이 대부분의 실제 집값과 차이가 나게 되는 현상을 볼 수 있습니다. 그리고 동일한 이유로 검증 데이터에서도 에측값은 좋지 못한 결과를 보일 것입니다. 모델이 집값 data의 pattern 또는 중요한 요인을 파악하기 실패했고 심지어 학습데이터에서도 모델의 성능이 좋지 못할 때, 이러한 현상을 과소적합(Underfitting)이라고 부릅니다.
우리가 관심있는 것은 우리의 검증 데이터를 이용해 측정되는 정확도, 즉 새로운 데이터에 대한 모델의 정확도이므로 underfitting과 overfitting사이에 최고의 결과를 보이는 지점을 선택해야 합니다. 아래 그림을 참고하면 validation curve(red line)에서 가장 낮은 지점을 선택 해야 합니다.
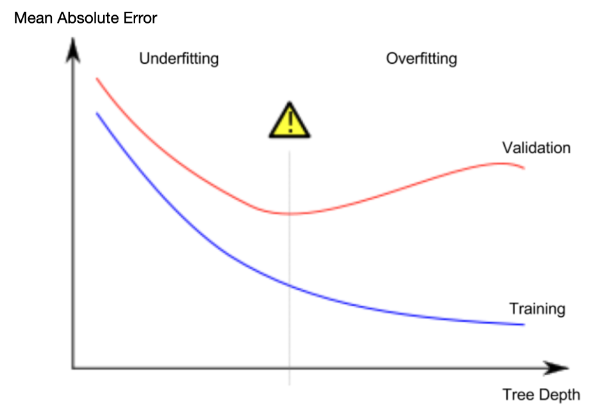
Example
tree의 깊이를 조절하는 방법은 여러개가 있는데, 이 중 어떤 옵션은 몇개의 route들만 다른 rotue보다 깊이가 더 깊어지도록 할 수 있습니다. 이와 달리 the max_leaf_nodes 인자는 매우 합리적으로 overfitting과 underfitting을 제어 할 수 있습니다. 모델이 더 많은 leaves를 만들어 낼수록 underfitting에서 overfitting 되도록 모델이 만들어 질 것 입니다.
MAE 점수를 계산하는 함수를 이용하여 max_leaf_nodes에 따른 MAE점수를 비교해 보겠습니다.
from sklearn.metrics import mean_absolute_error
from sklearn.tree import DecisionTreeRegressor
import pandas as pd
# Load data
melbourne_file_path = '../input/melbourne-housing-snapshot/melb_data.csv'
melbourne_data = pd.read_csv(melbourne_file_path)
# 결측치 처리
filtered_melbourne_data = melbourne_data.dropna(axis=0)
# target과 feature 선택
y = filtered_melbourne_data.Price
melbourne_features = ['Rooms', 'Bathroom', 'Landsize', 'BuildingArea',
'YearBuilt', 'Lattitude', 'Longtitude']
X = filtered_melbourne_data[melbourne_features]
from sklearn.model_selection import train_test_split
# features와 target 데이터를 훈련데이터와 검증 데이터로 나눔
train_X, val_X, train_y, val_y = train_test_split(X, y,random_state = 0)
def get_mae(max_leaf_nodes, train_X, val_X, train_y, val_y):
model = DecisionTreeRegressor(max_leaf_nodes=max_leaf_nodes, random_state=0)
model.fit(train_X, train_y)
preds_val = model.predict(val_X)
mae = mean_absolute_error(val_y, preds_val)
return(mae)
for-루프를 사용하여 max_leaf_nodes 값에 따른 모델에 정확도를 비교해 보겠습니다.
# max_leaf_nodes을 달리하며 MAE 값을 계산합니다.
for max_leaf_nodes in [5, 50, 500, 5000]:
my_mae = get_mae(max_leaf_nodes, train_X, val_X, train_y, val_y)
print("Max leaf nodes: %d \t\t Mean Absolute Error: %d" %(max_leaf_nodes, my_mae))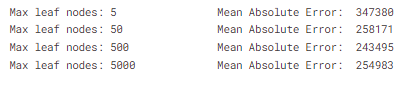
위 결과에서는 500이 가장 좋은 결과를 보여줍니다.
결론
모델은 다음 중 하나를 겪을 수 있습니다.
- Overfitting: 새로 보게될 데이터에는 발생하지 않을 pattern을 학습데이터에서 파악하여 실제 예측에서는 부정확한 예측 결과를 보여준다.
- Underfitting: 훈련데이터에서 예측에 중요한 pattern을 파악하지 못하여 부정확한 예측 결과를 보여준다.
모델 학습에서는 사용되지 않은 검증 데이터를 이용하여 모델의 정확도를 측정할 수 있습니다. 이를 이용하여 다른 후보들을 살펴보고 그 중 최고를 선택해야 합니다.
Your Turn
optimizing the model you've previously built.
Reference
이글의 모든 내용은 아래의 링크에서 사용한 것입니다.
