이 글은 Kaggle Course의 Random Forests를 번역한 글입니다.
Introduction
Decision tree는 많은 leaves를 가질 경우, 각 leaf에서의 예측값은 적은 수의 집 값 데이터를 이용하여 만들어진 값이기 때문에 과적합(Overfitiing) 되는 경향이 있었습니다. 적은 leaves를 갖는 얕은 깊이의 tree는 훈련 데이터에서 집값의 pattern을 파악하지 못하여 (leaf에 많은 데이터가 있어 데이터별 구분되는 pattern을 파악하지 못하기 때문) 좋지 못한 예측 결과를 보이는 경향이 있습니다(Underfitting).
Overfitting과 Underfitting 문제는 최신 모델링 기법들도 겪는 문제입니다. 그러나 많은 모델들은 더 나은 성능을 보일 수 있는 여러 아이디어를 갖고 있습니다. Random forest를 예시로 들어보겠습니다.
Random Forest는 많은 tree를 사용하여 "각 tree 예측값들의 평균"으로 최종 예측 결과를 만들어냅니다. 이는 보통 한개의 decision tree를 사용할 때보다 더 좋은 예측결과를 보여주고 기본 parmeter로도 좋은 성능을 보입니다. modeling에 관해 계속 공부하다 보면 이보다 더 좋은 성능을 보이는 모델들을 배우게 될 것입니다. 그러나 그 모델들은 parameter에 따라 예측값이 민감하게 바뀔것입니다.
Example
import pandas as pd
# Load data
melbourne_file_path = '../input/melbourne-housing-snapshot/melb_data.csv'
melbourne_data = pd.read_csv(melbourne_file_path)
# 결측값 제거
melbourne_data = melbourne_data.dropna(axis=0)
# target과 features 선택
y = melbourne_data.Price
melbourne_features = ['Rooms', 'Bathroom', 'Landsize', 'BuildingArea',
'YearBuilt', 'Lattitude', 'Longtitude']
X = melbourne_data[melbourne_features]
from sklearn.model_selection import train_test_split
# target, feature 데이터를 훈련데이터와 검증 데이터로 나눈다.
# 나뉜 결과는 random number generator에 따라 달라진다. random_state에 값을 넣어줌으로써
# 이 script를 돌릴때마다 동일한 결과를 얻을 수 있다.
train_X, val_X, train_y, val_y = train_test_split(X, y,random_state = 0)Scikit-learn에서 decision tree를 불러오는 것과 유사하게 ranom forest모델을 불러올 수 있습니다. 여기서 DecisionTreeRegressor 대신에 RandomForestRegressor class를 사용하겠습니다.
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_absolute_error
forest_model = RandomForestRegressor(random_state=1)
forest_model.fit(train_X, train_y)
melb_preds = forest_model.predict(val_X)
print(mean_absolute_error(val_y, melb_preds))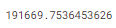
Concolusion
RandomForest의 예측 결과를 더 개선시킬 여지가 있지만, Decision tree의 error score인 250,000보다는 이미 충분히 작은 error를 보였습니다. Decision Tree에서 Maximum Depth의 값을 바꿔 주었듯이 Random Forest에서도 성능을 개선시킬 여러 parameter를 설정할 수 있습니다. 그러나 앞서 말했듯이 Random Forest의 장점 중 하나는 이러한 tuning 없이도 일반적으로 좋은 성능을 보인다는 점 입니다.
Your Turn
