이글은 Missing Values를 번역한 글입니다.
이번에는 결측값(Missing Values)를 다루는 방법들을 배울것입니다. 이 방법들을 실제 데이터셋에 적용하여 결과를 비교할 수 있을것입니다.
Introduction
데이터는 여러 이유로 결측값을 갖게 됩니다. 예로,
- 침실이 2개인 집은 세 번째 침실 크기 값을 포함하지 않았을 수 있습니다.
- 응답자가 수입에 대해 공개를 하지 않을 수 있습니다.
대부분의 machine learning libraries(예: scikit-learn)를 이용해 결측값을 갖고 있는 데이터로 모델을 만든다면 error가 발생할 수 있습니다. 따라서 아래와 같은 전략중 하나를 선택하여 결측치를 처리해야 합니다.
3가지 접근법
1) A simple Option: 결측값이 있는 Columns을 제거하기
가장 간단한 방법은 결측값이 있는 coluns을 제거하는 것입니다.

제거되는 columns에서 대부분의 값이 결측값이 아니라면, 이러한 방법은 모델이 (잠재적으로 유용한)많은 정보를 잃어버리는 결과를 초래할 수 있습니다. 예로 10,000개의 행을 가진 데이터셋에서 하나의 중요한 column이 1개의 결측치를 갖고 있다면 이러한 방법은 해당 column 전체를 제거하게 될것입니다.
2) A Bettor Option: 대치법(Imputation)
대치법(Imptutation)은 결측값을 다른값으로 대체하는 방법입니다. 예로 각 column에 결측치를 해당 컬럼의 평균값으로 대체 할 수 있습니다.

채워진 값(imputed value)는 대부분의 경우에 정확하진 않지만 column을 완전히 제거하는 경우보다 더 정확한 모델을 만들 수 있습니다.
3) 또 다른 방법
대치법(Imputation)은 일반적으로 잘 작동합니다. 그러나 채워진 값(imputed value)는 시스템적으로 실제 값(실제 데이터셋에서 수집되지 값)보다 작거나 큰 값일 수 있습니다. 또는 결측치가 있는 행은 unique한 값을 갖게 될 수 있습니다. 이런 경우 어떤 값이 결측치인지를 고려하여 예측한다면 더 좋은 예측 결과를 얻을 수 있습니다.
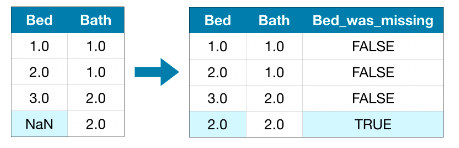
이 접근법은 전과 마찬가지로 결측치에 값을 채워 놓고 추가적으로, 원래 데이터셋에 결측치가 있던 컬럼에 대하여 어떤 값이 채워진 값(imputed value)인지를 나타내는 컬럼을 새로 만들어 내는것입니다. 이 방법은 결과를 개선시킬 수도 있고 또는 전혀 도움이 되지 않을 수도 있습니다.
Example
예시에서는 Melbourne Housing dataset을 이용합니다. 모델은 방의 개수, 부지의 크기 등을 이용하여 집의 가격을 예측하는 모델을 만들것입니다.
데이터 불러오기
import pandas as pd
from sklearn.model_selection import train_test_split
# 데이터 불러오기
data = pd.read_csv('../input/melbourne-housing-snapshot/melb_data.csv')
# target 선택하기
y = data.Price
# 문제를 간단하게 하기 위해 수치형 변수들만 이용할 것입니다.
melb_predictors = data.drop(['Price'], axis=1)
X = melb_predictors.select_dtypes(exclude=['object'])
# data를 학습데이터와 검증데이터로 나누기
X_train, X_valid, y_train, y_valid = train_test_split(X, y, train_size=0.8, test_size=0.2,
각 접근법의 성능을 측정하기 위한 함수 정의
score_dataset() 함수를 정의하여 결측값을 다루는 다른 방법들을 비교할 것입니다. 이 함수는 random forest 모델로 계산된 평균절대오차(MAE: mean absolute error)를 알려줄것입니다.
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_absolute_error
# 다른방법들을 비교하는 함수
def score_dataset(X_train, X_valid, y_train, y_valid):
model = RandomForestRegressor(n_estimators=10, random_state=0)
model.fit(X_train, y_train)
preds = model.predict(X_valid)
return mean_absolute_error(y_valid, preds)방법 1의 성능(결측값이 있는 columns 제거하기)
학습 데이터셋과 검증 데이터셋, 둘 다 이용하기 때문에 동일한 columns을 두 데이터에서 제거하야 합니다.
# 결측값을 갖는 columns의 이름 얻기
cols_with_missing = [col for col in X_train.columns
if X_train[col].isnull().any()]
# 학습데이터셋과 훈련데이터셋의 columns 제거 하기
reduced_X_train = X_train.drop(cols_with_missing, axis=1)
reduced_X_valid = X_valid.drop(cols_with_missing, axis=1)
print("MAE from Approach 1 (Drop columns with missing values):")
print(score_dataset(reduced_X_train, reduced_X_valid, y_train, y_valid))
방법 2의 성능(Imputation)
SimpleImputer를 사용하여 결측값들을 각 column의 평균값으로 대체할 것입니다.
간단한 방법이지만, 결측값을 평균값으로 채우는 방법은 꽤 좋은 성능을 보입니다(데이터셋마다 다르지만). 통계학자들이 어떻게 값을 채워넣을지에대한 많은 복잡한 방법들을 실험해 봤지만(예: regression imputation), Sophisticated Machine learning 모델에 적용해 보았을때 추가적인 이점을 얻지 못했습니다.
from sklearn.impute import SimpleImputer
# Imputation
my_imputer = SimpleImputer()
imputed_X_train = pd.DataFrame(my_imputer.fit_transform(X_train))
imputed_X_valid = pd.DataFrame(my_imputer.transform(X_valid))
# Imputation removed column names; put them back
imputed_X_train.columns = X_train.columns
imputed_X_valid.columns = X_valid.columns
print("MAE from Approach 2 (Imputation):")
print(score_dataset(imputed_X_train, imputed_X_valid, y_train, y_valid))
방법2는 방법1 보다 더 낮은 MAE를 보였습니다. 따라서 방법2가 해당 데이터셋에서 더 좋은 성능을 보입니다.
방법 3의 성능
결측값을 채워넣은 다음, 어떤 값이 채워진 값인지를 기록합니다.
# 원본 데이터가 바뀌는것을 막기 위해 copy를 사용합니다.
X_train_plus = X_train.copy()
X_valid_plus = X_valid.copy()
# 어떤 값이 채워졌는지(imputed)에 대한 column을 만듭니다.
for col in cols_with_missing:
X_train_plus[col + '_was_missing'] = X_train_plus[col].isnull()
X_valid_plus[col + '_was_missing'] = X_valid_plus[col].isnull()
# Imputation
my_imputer = SimpleImputer()
imputed_X_train_plus = pd.DataFrame(my_imputer.fit_transform(X_train_plus))
imputed_X_valid_plus = pd.DataFrame(my_imputer.transform(X_valid_plus))
# Imputation은 column의 이름을 제거하기 때문에 이름을 되돌립니다.
imputed_X_train_plus.columns = X_train_plus.columns
imputed_X_valid_plus.columns = X_valid_plus.columns
print("MAE from Approach 3 (An Extension to Imputation):")
print(score_dataset(imputed_X_train_plus, imputed_X_valid_plus, y_train, y_valid))
방법3은 방법2 보다 약간 안 좋은 결과를 보였습니다.
그렇다면 왜 Imputation이 column을 제거하는 것보다 더 좋은 성능을 보여줄까요?
학습데이터는 10864개의 행과 12개의 column을 갖고 있습니다. 3개의 column이 결측치를 갖고 있고, 각 컬럼에서 결측치의 수는 전체 데이터 수의 절반 이하입니다. 그러므로 column을 제거하면 많은 유용한 정보를 제거하게 되기 때문에, imputation으로 결측값을 채워넣는 것은 column을 제거하는 것보다 더 좋은 성능을 보입니다.
# 학습데이터의 Shape(num_rows, num_columns)
print(X_train.shape)
# 학습데이터에서의 각 column에서의 결측치(값)의 수
missing_val_count_by_column = (X_train.isnull().sum())
print(missing_val_count_by_column[missing_val_count_by_column > 0])
Conclusion
일반적으로 결측값을 채워넣는 방법은(Imputing missing values - 방법2, 방법3)는 결측값이 존재하는 column을 제거하는 방법1 보다 더 좋은 성능을 보였습니다.
Your Turn
exercise를 통해 연습해보세요
Reference
