이글은 Kaggle Courses에 Cross-Validation을 번역한 글입니다.
이번에는 모델 성능의 정확한 측정을 위한 교차검증(Cross-validation)에 대해 배우겠습니다.
Introduction
머신러닝은 반복정인 과정입니다. 어떤 예측 변수를 사용할지, 어떤 모델을 사용할지, 모델의 parameter를 어떻게 설정할지 등을 선택해야 합니다. 여태까지는 이를 검증 데이터(validation set)에 대한 모델의 성능을 측정하는 데이터 중심 방식으로 결정을 내려왔습니다.
그러나 이러한 접근법은 몇가지 단점이 존재합니다. 예시로 5000개의 행을 갖는 데이터셋이 있다고 가정해 봅시다. 당신은 일반적으로 데이터의 20%정도(1000개)를 검증 데이터로 남겨둘 것입니다. 그러나 이러한 방법은 모델 성능을 결정하는데 있어서 무작위성을 부여하게 됩니다. 즉 모델은 1000개의 데이터에는 잘 작동할 수 있지만 다른 1000개의 데이터 에서는 부정확한 성능을 보일 수 있습니다.
극단적인 예시로 오직 1개의 데이터만 검증 데이터로 남겨두고 여러 모델들의 성능을 비교한다면, 이 한개에 데이터에 대해서 가장 좋은 예측을 하는 모델은 우연에 의해 결정될 확률이 큽니다.
일반적으로 모델의 성능을 측정할 때 검증 데이터셋의 크기가 클수록 더 적은 무작위성(Randomness A.K.A "noisse) 보이고 더 신뢰할 수 있는 결과를 얻습니다. 불행하게도 큰 검증 데이터셋은 훈련데이터에서 많은 데이터를 제거함으로써 얻을 수 있고, 더작은 훈련 데이터셋으로 학습한 모델은 안 좋은 성능을 보일것 입니다.
교차 검증이란?(What is cross-validation)
교차검증(Cross-validation)은 데이터의 다른 집합들에다 모델링 과정을 적용하여 여러번 모델의 성능을 측정하는 방법입니다.
예를 들어보겠습니다. 전체 데이터셋을 5개(전체 데이터셋의 20%)로 분할합니다. 이런 경우를 데이터를 5개의 "fold" 로 나누었다고 말합니다.
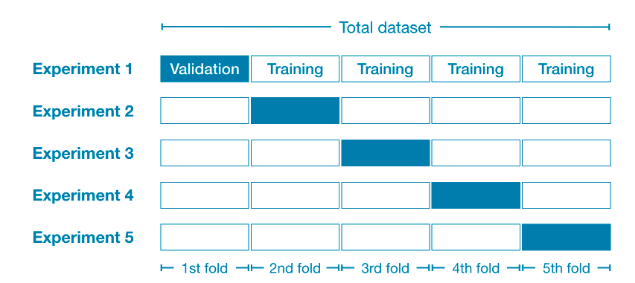
그런다음 각 fold에 대해 실험(experiment)을 수행합니다.
- experiment1 에서 첫번째 fold를 검증 데이터셋으로 사용하고 나머지를 훈련데이터셋으로 이용합니다. 이러한 방법은 20% holdout 셋을 기반으로 모델의 성능을 측정한 결과를 얻게 됩니다.
- experiment2 에서 두번째 fold를 제외한(holdout) 나머지 데이터셋을 훈련데이터셋으로 이용하고 두번째 데이터셋을 이용하여 모델의 성능을 측정합니다.
- 이 과정을 모든 fold에 대하여 반복합니다. 이 결과를 합친다면 모든 데이터가 어떤 시점에서 검증데이터셋으로 사용되어 집니다. 결론적으로는 모든 데이터를 이용하여 모델의 성능을 측정하게 됩니다.
언제 Cross-validation을 사용해야 할까?
Cross-validation 더 정확하게 모델의 성능을 측정할 수 있습니다. 이는 모델링에서 여러 결정을 내려야 할 때 특히 중요합니다. 그러나 이는 모델을 여러번 (각 fold 마다 한번씩) 학습시켜야 하기 때문에 수행시간이 길어질 수 있습니다.
그렇다면 이런 tradeoffs를 고려했을때 어떤 접근 방법을 사용해야 할까요?
-
작은 데이터셋인 경우 여러번의 계산의 부담이 크지 않을 때 Cross-validation을 사용해야만 합니다.
-
큰 데이터셋의 경우 코드를 더 빨리 수행할 수 있고 다른 검증데이터셋을 이용하는 것에 큰 장점이 없기 때문에, 하나의 검증 데이터셋만 이용해도 충분합니다.
큰데이터셋과 작은 데이터셋을 구분하는데 특정 값이 정해진건 아니지만, 모델을 실행하는데 시간이 많이 걸리지 않는다면 Cross-validation을 하는것이 좋습니다. 그리고 cross-validation에서 각 실험의 결과가 비슷한 값을 보이는지 확인할 수 있습니다. 만약 각실험의 결과가 동일한 결과를 보인다면 하나의 검증데이터셋이면 신뢰할수 있는 결과를 얻을 수 있을것입니다.
Example
전과 동일한 데이터셋(멜버른 집값 데이터)를 이용하여 실험하겠습니다.
import pandas as pd
# 데이터 불러오기
data = pd.read_csv('../input/melbourne-housing-snapshot/melb_data.csv')
# 예측 변수 선택
cols_to_use = ['Rooms', 'Distance', 'Landsize', 'BuildingArea', 'YearBuilt']
X = data[cols_to_use]
# target값 설정
y = data.Pricepipeline을 정의하여 imputer를 이용하여 결측치를 처리하고 random forest 모델로 예측을 수행하겠습니다. pipeline 없이 cross-valdation을 하는것은 가능하나, 여기서는 pipeline을 사용하여 코드를 직관적으로 만들겠습니다.
from sklearn.ensemble import RandomForestRegressor
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
my_pipeline = Pipeline(steps=[('preprocessor', SimpleImputer()),
('model', RandomForestRegressor(n_estimators=50,
random_state=0))
])scikit-learn에 cross_val_score()함수를 이용하여 cross-validation score를 얻었습니다. 여기서 cv parameter를 설정하여 fold의 수를 결정합니다.
from sklearn.model_selection import cross_val_score
# sklearn이 음수의 MAE를 계산하기 때문에 -1을 곱해줍니다.
scores = -1 * cross_val_score(my_pipeline, X, y,
cv=5,
scoring='neg_mean_absolute_error')
print("MAE scores:\n", scores)
scoring parameter는 어느지표로 모델의 성능을 측정할지 알려줍니다. 이 경우에는 negative mean absolute score (MAE)를 이용했습니다. scikit-learn의 doc을 참고하면 어떤 옵션들이 있는지 확인 할 수 있습니다. scikit-learn은 모든 평가지표(Metric)는 높은 숫자가 좋은 성능을 의미하도록 정의 되어 있기에 MAE에 음수값을 사용하게 됩니다.
일반적으로 모델의 성능을 비교하기 위해 하나의 값을 이용하기를 원하므로 cross-validation의 결과를 평균내어 줍니다.
print("Average MAE score (across experiments):")
print(scores.mean())
Conclusion
cross-validation을 사용하여 모델 성능 측정에 더 정확한 결과를 얻게 되었습니다.
Your turn
next exercise에서 배운것을 적용해 보세요.
Reference
