이 글은 kaggle courses XGboost를 번역한 글입니다.
이번 강의에서는 gradient boosting 모델을 어떻게 만들고 최적화 하는지에 대해 배울것입니다. 이 모델은 kaggle competitions에서 주로 이용되는 방법이고 다양한 데이터셋에서 최고의 성능을 보였습니다.
Introduction
강의를 진행하면서 RandomForst model을 이용하여 예측을 해왔습니다. 이 방법은 많은 decision tree들의 예측결과를 합하여 평균냄으로써 하나의 tree를 이용하는 것보다 더 좋은 성능을 보였습니다.
이러한 Random forest의 방법을 "Ensemble method"라고 부릅니다. Ensemble methods는 많은 모델의 예측 결과를 합치는 것을 의미합니다. (Random forest의 경우는 여러개의 tree결과를 합치는 것입니다.)
다음으로 gradient boosting이라 불리는 다른 ensemble 방법에 대해 배우겠습니다.
Gradient Boosting
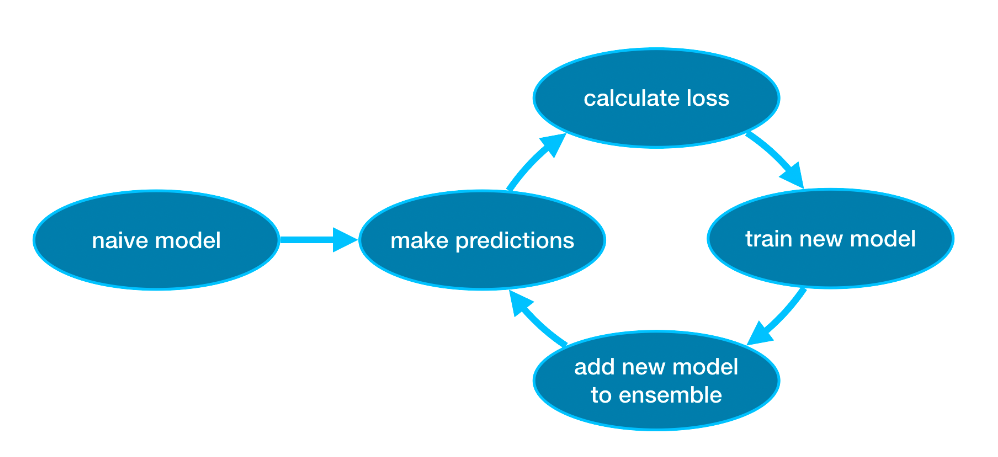
Gradient boosting은 반복적으로 모델을 더하는 Cycle을 통해 ensemble하는 방법입니다.
처음에는 하나의 모델로 ensemble을 시작합니다. (이 예측값은 부정확할 수 있으나 다음에 ensemble에 더해지는 예측 결과로 이러한 부정확한 예측 결과를 조정할 수 있습니다.)
다음으로 Cycle을 시작합니다.
- 우선 현재 ensemble에 더해진 모델들을 이용해 데이터셋에 예측값을 만듭니다.(모델들의 예측값의 평균)
- 이 예측값으로 loss 함수를 계산합니다.(ex: mean squared error)
- 그 다음에 loss 함수를 이용하여 ensemble에 더해질 새로운 모델을 적합시킵니다. 이 때, ensemble에 더해질 모델의 parameter는 loss를 줄이도록 결정합니다.
- 마지막으로 새로운 모델을 ensemble에 더합니다.
- 이러한 과정을 반복합니다.
Example
우선 학습데이터와 검정데이터셋을 불러옵니다.
import pandas as pd
from sklearn.model_selection import train_test_split
# Read the data
data = pd.read_csv('../input/melbourne-housing-snapshot/melb_data.csv')
# Select subset of predictors
cols_to_use = ['Rooms', 'Distance', 'Landsize', 'BuildingArea', 'YearBuilt']
X = data[cols_to_use]
# Select target
y = data.Price
# Separate data into training and validation sets
X_train, X_valid, y_train, y_valid = train_test_split(X, y)이 예시에서는 XGBoost 라이브러리로 작업합니다. XGBoost는 Extreme Gradient Boost를 의미하며, 성능과 속도에 초점을 맞춘 몇 가지 추가 기능을 갖춘 Gradient Boost를 구현한 것입니다.
다음의 코드 셀에서, XGBoost를 위한 scikit-learn의 API를 import 하겠습니다.(xgboost. XGBRegressor). scikit-learn에서 해왔던 것처럼 모델을 만들고 적합할 수 있게 해줍니다. output에서 볼 수 있듯이, XGBRegressor
class는 튜닝할 수 있는 많은 parameters를 가지고 있습니다 -- 이 와 관련해서는 곳 배우게 될 것입니다.
from xgboost import XGBRegressor
my_model = XGBRegressor()
my_model.fit(X_train, y_train)
예측값을 만들고 모델을 평가하겠습니다.
from sklearn.metrics import mean_absolute_error
predictions = my_model.predict(X_valid)
print("Mean Absolute Error: " + str(mean_absolute_error(predictions, y_valid)))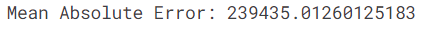
Parameter Tuning
XGBoost에는 정확성과 학습 속도에 큰 영향을 미칠 수 있는 몇 가지 parameter가 있습니다. 이해해야 할 첫 번째 paramter는 다음과 같습니다.
n_estimators
n_estimators는 위에서 언급한 modeling cycle을 얼마나 반복해야 할지를 지정합니다. 이는 ensemble에 더해질 모델의 수를 의미합니다.
- 값이 너무 작다면 underfitting이 발생하여 학습데이터와 테스트 데이터에 대해 부정확한 예측을 할 수 있습니다.
- 값이 너무 크다면 overfitting이 발생하여, 학습데이터에는 정확한 에측 결과를 보이다 테스트 데이터에는 부정확한 에측 결과를 초래할 수 있습니다.
일반적인 값의 범위는 100-1000 사이이지만, 이는 아래에 설명된 learning_lrate parametr 값에 따라 달라집니다.
다음은 ensemble에 더해질 모델의 수를 설정하는 코드 입니다.
my_model = XGBRegressor(n_estimators=500)
my_model.fit(X_train, y_train)early_stopping_rounds
early_stopping_rounds은 n_estimator에 대한 이상적인 값을 자동으로 찾을 수 있는 방법을 제공합니다. Early stopping은 모델이 검정데이터에 대한 성능이 개선되지 않을 때 iterating(cycle을 반복하는 것)을 중단합니다. 높은 n_estimator의 값을 성정해 놓고 early_stopping_rounds를 이용하여 최적의 iteration을 결정하는 것이 좋은 방법입니다.
early_stopping_rounds를 사용할 때, validation score를 계산하기 위해 데이터의 일부분을 떼어나야 합니다. 이는 eval_set parametor를 이용하여 설정할 수 있습니다.
Early stopping을 포함한 코드 예시는 다음과 같습니다.
my_model = XGBRegressor(n_estimators=500)
my_model.fit(X_train, y_train,
early_stopping_rounds=5,
eval_set=[(X_valid, y_valid)],
verbose=False)learning_rate
각 모델의 예측값을 단순하게 합산하여 예측을 얻는 대신, 각 모델의 예측값을 더하기전에 작은 수(learning rate)를 곱할 수 있습니다. 이는 ensemble에 더하는 각 tree가 덜 도움이 된다고 의미합니다. 따라서 n_estimator의 값을 overfitting 없이 높은 값으로 설정할 수 있습니다. early stopping을 사용한다면, 적정할 tree의 수가 자동으로 결정 될 것입니다.
일반적으로, 작은 learning rate와 큰 estimator의 수가 더 정확한 XGBoost 모델을 만들지만, 이는 많은 cycle을 반복하기 떄문에 모델의 학습 속도가 오래 걸릴 수 있습니다. 초기값으로 XGBoost는 learning_rate = 0.1으로 설정합니다.
learning rate를 바꾼 코드의 예시는 다음과 같습니다.
my_model = XGBRegressor(n_estimators=1000, learning_rate=0.05)
my_model.fit(X_train, y_train,
early_stopping_rounds=5,
eval_set=[(X_valid, y_valid)],
verbose=False)n_jobs
런타임이 고려되는 대규모 데이터 세트에서는 병렬 처리를 사용하여 모델을 더 빨리 구축할 수 있습니다. 일반적으로 n_jobs parameter를 시스템의 코어 수와 동일하게 설정합니다. 작은 데이터 세트에서는 이 방법이 도움이 되지 않습니다.
모델에 성능에 변화는 없고, 학습(fit)에 걸리는 시간은 중요하지 않을 수도 있습니다. 하지만 fit 명령어에 오랜 시간이 걸리는 큰 데이터셋을 이용할 떄는 n_jobs가 유용할 수 있습니다.
수정된 코드는 다음과 같습니다.
my_model = XGBRegressor(n_estimators=1000, learning_rate=0.05, n_jobs=4)
my_model.fit(X_train, y_train,
early_stopping_rounds=5,
eval_set=[(X_valid, y_valid)],
verbose=False)Conclusion
XGBoost는 일반적인 정형데이터(Pandas DataFrame에 저장되는 데이터, 이미지와 비디오와는 반대됨)에 좋은 결과를 보이는 라이브러리 입니다. 적절한 parameter tunning을 통해 더욱더 정확한 모델을 만들 수 있습니다.
Your Turn
다음 예시에서 XGBoost를 이용하여 나만의 모델을 만들어보세요
Reference
해당 글의 이미지와 내용은 모두 다음을 이용한 것입니다.
