이 글은 Kaggle Courses에 있는 Pipelines 글을 번역한 것입니다.
이번에는 pipelines(파이프라인) 을 사용하여 모델링 코드를 깔끔하게 하는 방법을 배우겠습니다.
Introduction
Pipelines은 데이터 처리와 모델링 코드를 깔끔하게 관리할 수 있게 해주는 간단한 방법입니다. 특히 pipeline은 전처리와 모델링 단계를 묶어 한번에 처리 할 수 있게 해줍니다.
많은 데이터 과학자들이 pipeline 없이 작업하지만, 파이프라인은 몇가지 중요한 장점을 갖고 있습니다.
-
간결한 코드: 각 단계에서 전처리 하는 과정이 반복된다면 코드가 지저분해질 수 있습니다. 파이프라인을 사용한다면, 학습과 검증 데이터 단계의 전처리 과정을 한번에 처리 할 수 있습니다.
-
더 적은 bug: 전처리 과정을 건너 뛰거나 잘못 적용할 확률이 줄어듭니다.
-
생산 용이성: 프로토타입에서 대규모로 배포할 수 있는 모델로 전환하는 것은 의외로 어려울 수 있습니다. 여기서 많은 관련 문제에 대해서는 언급하지 않겠지만, 파이프라인이 이러한 문제에서 도움이 될 수 있습니다.
-
모델 검증을위한 추가 옵션: Cross validation(교차 검증)을 다루는 다음 학습에 예시가 나와 있습니다.
Example
지난 번과 동일하게 Melbourne Housing dataset.을 이용하여 예시를 들어보겠습니다.
데이터를 우선 불러오고 학습데이터와 검증데이터로 나누겠습니다.
import pandas as pd
from sklearn.model_selection import train_test_split
# 데이터 불러오기
data = pd.read_csv('../input/melbourne-housing-snapshot/melb_data.csv')
# target값 분리하기
y = data.Price
X = data.drop(['Price'], axis=1)
# 학습데이터와 검증 데이터로 나누기
X_train_full, X_valid_full, y_train, y_valid = train_test_split(X, y, train_size=0.8, test_size=0.2,
random_state=0)
# "Cardinality"는 변수에서 유일한 값의 수를 의미합니다.
# 낮은 Cardinality를 갖고 있는 범주형 변수 선택(편의성을 위함)
categorical_cols = [cname for cname in X_train_full.columns if X_train_full[cname].nunique() < 10 and
X_train_full[cname].dtype == "object"]
# 수치형 변수 선택
numerical_cols = [cname for cname in X_train_full.columns if X_train_full[cname].dtype in ['int64', 'float64']]
# 선택한 변수만 불러오기
my_cols = categorical_cols + numerical_cols
X_train = X_train_full[my_cols].copy()
X_valid = X_valid_full[my_cols].copy()head() method로 학습데이터를 살펴보겠습니다. 데이터는 범주형 변수를 포함하고 결측값이 있는 것을 알 수 있습니다. 파이프라인을 이용한다면 이 두 경우의 수를 간단하게 처리할 수 있습니다.
X_train.head()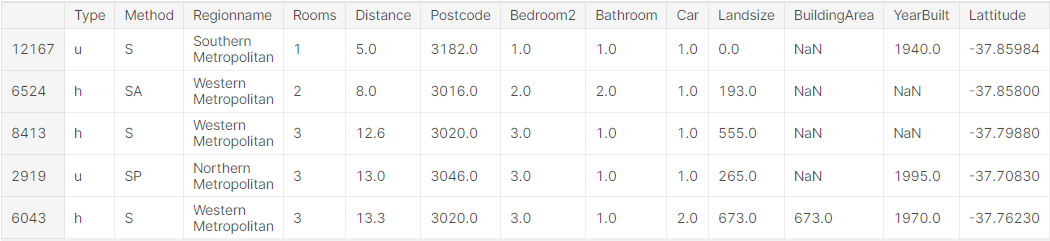
3단계를 거쳐서 전체 pipeline을 작성하겠습니다.
step 1: 전처리(preprocessing) 단계 정의하기
pipeline에서 전처리 및 모델링 단계를 함께 묶는 방법과 유사하게 ColumnTransformer 클래스를 사용하여 서로 다른 전처리 단계를 함께 묶습니다.
- numerical(수치형) data에 존재하는 결측값에 값을 채워(impute)넣습니다.
- categorical(범주형) data에 결측값에 값을 채워넣고 one-hot encoding을 수행합니다.
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import OneHotEncoder
# numerical(수치형) 데이터 전처리
numerical_transformer = SimpleImputer(strategy='constant')
# categorical(범주형) 데이터 전처리
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='most_frequent')),
('onehot', OneHotEncoder(handle_unknown='ignore'))
])
# numerical and categorical 데이터 전처리 한번에 묶기
preprocessor = ColumnTransformer(
transformers=[
('num', numerical_transformer, numerical_cols),
('cat', categorical_transformer, categorical_cols)
])Step 2: 모델 정의하기
다음으로 RandomForestsRegressor class를 이용하여 모델을 정의합니다.
from sklearn.ensemble import RandomForestRegressor
model = RandomForestRegressor(n_estimators=100, random_state=0)Step 3: pipleline을 만들고 평가하기
Pipleline class를 이용하여 전처리와 모델링 단계를 한번에 묶어 처리하는 pipeline을 정의합니다. 여기서 몇가지 중요한 점이 있습니다.
- pipeline을 이용한다면 학습데이터를 전처리하고 모델을 적합시키는 것을 한줄의 코드로 수행할 수 있습니다.(만약에 pipeline을 사용하지 않는다면 imputation(결측값 처리), one-hot encoding, 모델 학습을 개별로 수행해야 합니다. 만약 수치형 변수와 범주형 변수를 둘 다 다룬다면 이러한 과정은 지저분해 질것 입니다.
- pipeline을 사용하여 전처리 되지 않은 검증 데이터(
X_valid)를predict()커멘드에 넣어줍니다. 그러면 pipeline은 예측을 하기전에 자동으로 전처리를 수행합니다.(그러나 pipeline이 없다면 예측을 하기전에 검증데이터를 전처리 해야합니다.)
from sklearn.metrics import mean_absolute_error
# 파이프라인을 이요하여 전처리 코드와 모델링 코드를 묶어 주기
my_pipeline = Pipeline(steps=[('preprocessor', preprocessor),
('model', model)
])
# 학습데이터를 저처리하고 모델을 적합
my_pipeline.fit(X_train, y_train)
# 검증 데이터를 전처리하고 예측값을 생성
preds = my_pipeline.predict(X_valid)
# 모델 평가
score = mean_absolute_error(y_valid, preds)
print('MAE:', score)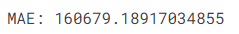
Conclusion
pipeline은 machine learning code를 간결하게하고 에러를 줄여준다는 장점이 있습니다 특히 복잡한 데이터를 전처리하는 작업환경에 유용합니다.
Your Turn
exercise에서 pipeline을 사용하여 고급 데이터 전처리 기술을 사용하고 예측을 개선해 보세요!
Reference
