이 글은 출처를 번역한 글입니다. 저작권에 문제가 있을시에 바로 삭제하겠습니다.
Introduction
이글은 우선 machine learning model이 어떻게 작동되고 사용 되는지에 대한 개요로 시작하고자 합니다. 이전에 statistical modeling 이나 machine learning을 전에 해본 경험이 있다면 쉽게 느껴질 것입니다. 걱정하지 마시길 바랍니다. 곧 더욱더 powerful models 들을 다룰 것입니다.
이 course에서는 다음과 같은 시나리오로 모델을 만들 것입니다:
당신의 사촌은 부동산 투기로 수백만 달러를 벌었고 그는 데이터 과학에 대한 당신의 관심 때문에 당신과 사업 파트너가 되겠다고 제안했습니다. 그가 자금을 대주고, 당신은 다양한 주택의 가치를 예측하는 모델을 만들어야 합니다.
당신은 과거에 어떻게 부동산의 가격을 어떻게 예측했는지에 대해 사촌에게 물었고, 그것은 단순히 직감이었다는 답을 들었습니다. 그러나 계속되는 질문을 통해 그가 과거의 보았던 집들의 가격에 패턴이 있다는 것을 알았고, 이 패턴을 이용해 가격을 예측한다는 것을 알아냈습니다.
Machine learning은 이와 동일하게 작동합니다. 우선 Decision Tree라는 모델로 예시를 들겠습니다. 좀 더 정확한 예측을 하는 좋은 모델들이 있지만, Decsiion Tree는 이해하기 쉽고 data science에서 다른 모델들의 기반이 되는 모델입니다.
가장 단순한 Decision Tree를 예시로 들겠습니다.
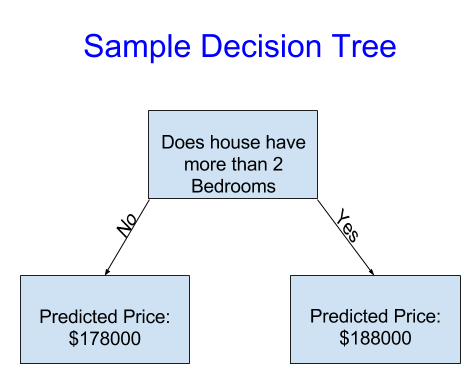
이 Decision Tree는 집을 오직 2개의 범주로 나눴습니다.(침실이 2개 이상인 집, 그게 아닌 집) 여기서 예측된 가격은 과거에 동일한 범주에 있는 집들의 평균 가격입니다.
데이터를 사용하여 집을 두 그룹으로 나누는 방법을 결정하고 각 그룹의 예상 가격을 다시 결정합니다. 데이터로 부터 이러한 pattern을 잡아내는 과정을 model을 fitting(적합) 또는 training(훈련) 한다고 합니다. 그리고 fitting에 사용되는 데이터를 training data(훈련 데이터)라고 합니다.
모델이 어떻게 fit 되는지(즉 데이터를 어떻게 나누는지)는 복잡하기 때문에 다음에 다루도록 하겠습니다. 모델이 fit 된 후에, 새로운 집들의 가격을 이를 이용해 예측 할 수 있습니다.
Improving the Decision Tree
다음 두개의 Decision Tree 중 어떤것이 실제 부동산 training data를 적합한 결과인 것 같습니까?
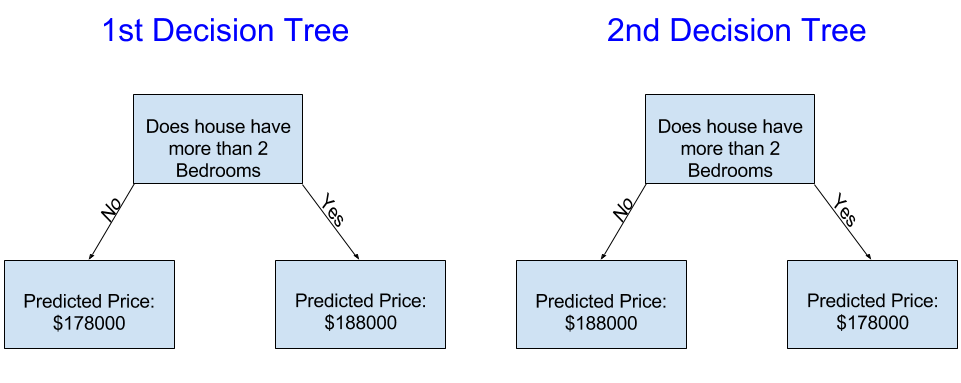
왼쪽에 있는 Decision Tree (Decision Tree 1)가 침실이 많은 집이 침실이 적은 집보다 높은 가격에 팔리는 경향이 있는 현실을 포착하기 때문에 더 합리적인 결과일 것입니다. 이 모델의 가장 큰 단점은 화장실의 수, 주차장 크기, 위치 등 집가격에 영향을 주는 다른 factor(요인)을 고려하지 않았다는 것입니다.
이는 tree가 더 많은 "splits"을 갖도록 함으로써 다른 요인들을 고려하도록 할 수 있습니다. 이는 tree를 "deeper"하게 한다고 합니다. 주차공간의 크기를 고려하는 Decision Tree는 다음과 같이 결정 될 것입니다.
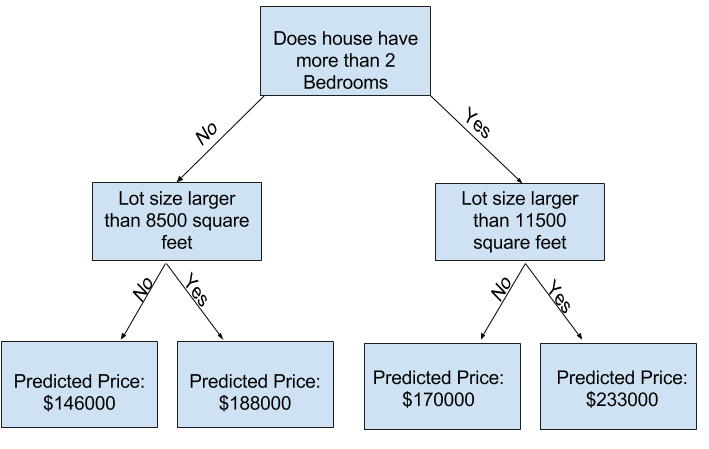
Decision Tree를 통해 항상 해당 주택의 특성에 맞는 경로를 선택하여 모든 주택의 가격을 예측합니다. 예측된 집가격은 tree의 맨 아래 부분이고, 예측이 되는 맨아래 부분을 leaf라 부릅니다.
splits과 leaf에 있는 값들은 데이터에 의해 결정되므로, 이제 당신이 잡업할 데이터로 확인해볼 시간입니다.
