데이터 비즈니스
1.[Python for Marketing Research and Analytics] 3장 정리
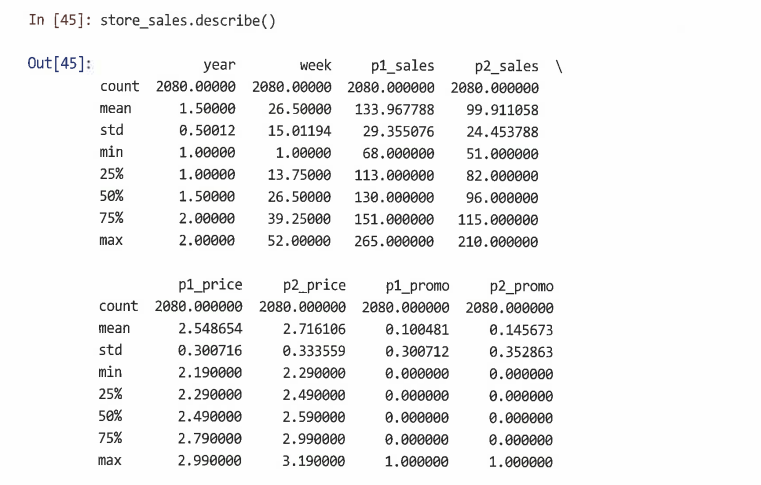
데이터 설명 3.1 데이터 시뮬레이션 3.1.1 데이터 저장: 구조 설정 상점 수와 각 상점에 대한 데이터 주 수 설정 head()를 사용해 store_sales를 확인 설정한대로 모든 값을 0으로 설정되어 있음 각 상점을 식별하기 위해 store_numbers 작
2.[Python for Marketing Research and Analytics] 4장 정리

4.1.1 데이터 시뮬레이션매장과 온라인에서 제품을 판매하는 다채널 소매 업체의 1000명 고객에 대한 데이터셋 생성프로세스를 재현할 수 있도록 난수 시드 설정고객을 설명하는 여러 변수를 만들 후 해당 변수를 cust_df 데이터프레임에 추가고객의 연령은 numpy.r
3.[Python for Marketing Research and Analytics] 5장 정리

구독 기반 서비스를 이용하는 300명의 응답자로부터 수집된 데이터 사용세 부분으로 코드 분리5.1.1 세그먼트 데이터 정의변수 이름과 추출하려는 분포 유형 정의각 세그먼크의 각 변수에 대한 통계 정의이상이나 푸아송 변수의 경우 평균만 지정하면 된다정규 변수의 경우 분포
4.[Python for Marketing Research and Analytics] 6장 정리
앞선 5장의 데이터를 그대로 사용한다.그룹 간의 차이가 실제 유의미한 차이인지를 식별하기 위해서 통계 검정을 진행해야 한다!카이제곱 검정은 가장 간단한 통계 검정 중 하나로, 2개의 범주형 변수가 서로 연관성이 있는지, 즉 서로 독립인지를 통계적으로 판단하는 방법이다.
5.[Python for Marketing Research and Analytics] 7장 정리

결과의 동인 식별: 선형 모델 만족 동인 분석: 제품의 특정 요소 및 그 제공과 관련해 제품에 대한 만족도를 모델링하는 것 마케팅 믹스 모델링: 가격과 광고가 판매와 어떻게 관련돼 있는지 이해하는데 사용되는 선형 모델 이때, 동인은 인과 관계를 암시하지 않으며, 모델은
6.[Python for Marketing Research and Analytics] 8장 정리
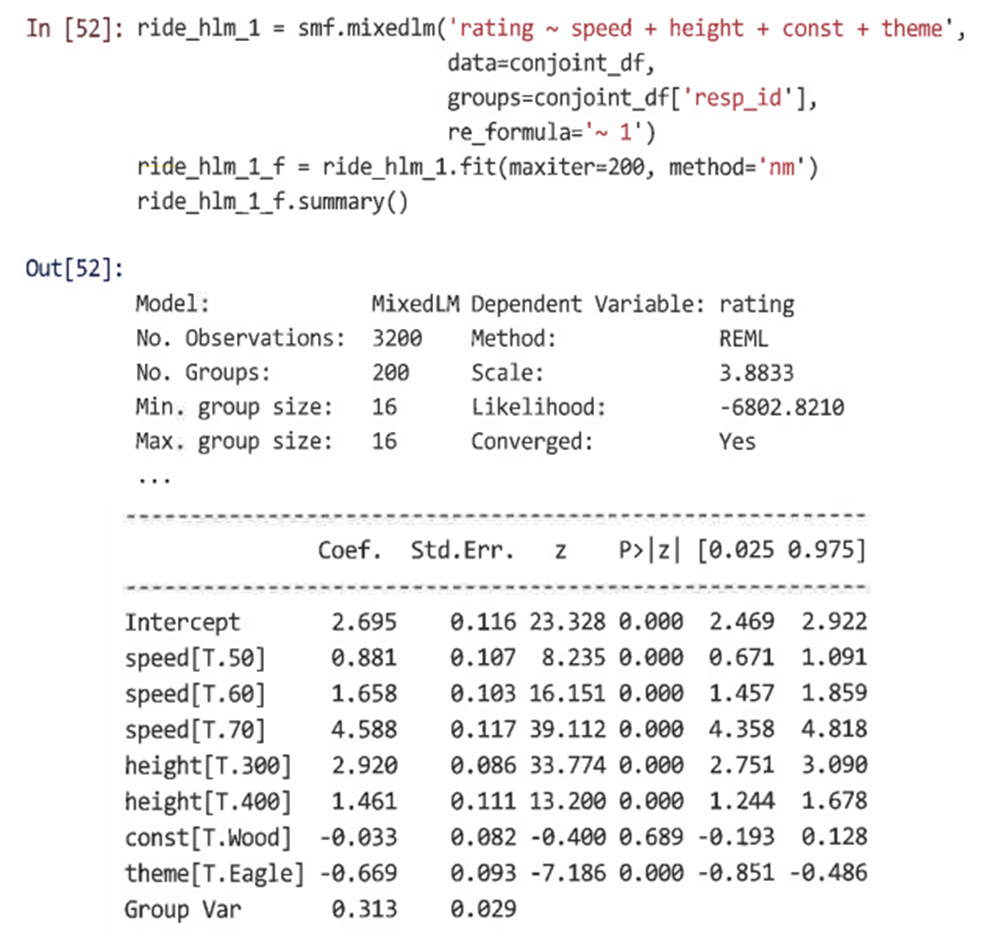
추가 선형 모델링 주제 8.1 고도로 상관된 변수 처리 8.1.1 온라인 지출의 초기 선형 모델 데이터 생성 ols()를 사용해 지출을 다른 모든 변수의 함수로 모델링한다. 데이터 시각화를 통해 해당 모델링의 문제점을 발견할 수 있다. => 극도로 치우친 변수와
7.[Python for Marketing Research and Analytics] 9장 정리
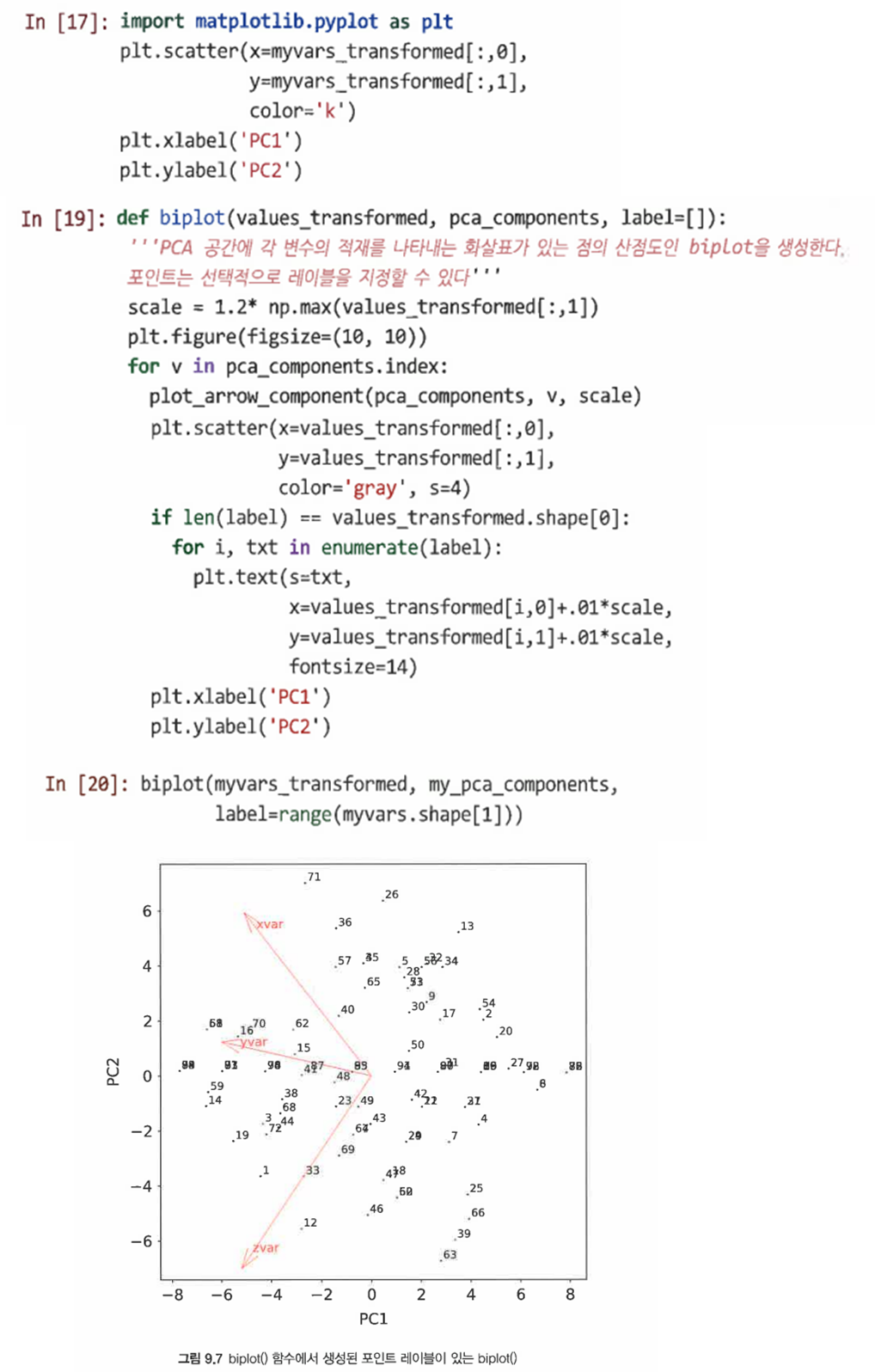
데이터 복잡도 줄이기 9.1 소비자 브랜드 평가 데이터 먼저 웹사이트로부터 데이터를 불러온다. 데이터 확인 9.1.1 데이터 크기 조정 원시 데이터의 크기 조정을 통해 개임과 샘플 간에 데이터를 더 비교할 수 있다. 데이터 표준화(정규화, Z-점수): 모든 관측치
8.[Python for Marketing Research and Analytics] 10장 정리

세그멘테이션: 부분 모집단 탐색을 위한 비지도 클러스터링 방법
9.[Python for Marketing Research and Analytics] 11장 정리

분류: 알려진 범주에 관측치 할당 11.1 분류 클러스터링은 그룹 멤버십을 발견하는 프로세스인 반면, 분류는 멤버십의 예측 분류는 상태가 알려진 관측치를 사용해 예측 변수를 도출한 다음 해당 예측 변수를 새 관측치에 적용한다. 분류 프로젝트에는 일반적으로 최소한 다음