그룹 비교: 테이블 및 시각화
5.1 소비자 세그먼트 데이터 시뮬레이션
- 구독 기반 서비스를 이용하는 300명의 응답자로부터 수집된 데이터 사용
- 세 부분으로 코드 분리

5.1.1 세그먼트 데이터 정의
-
변수 이름과 추출하려는 분포 유형 정의

-
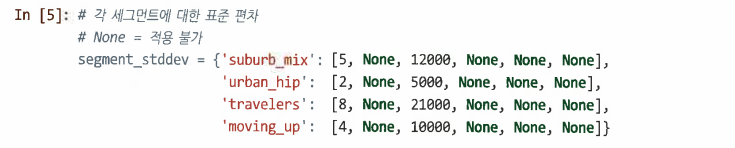
각 세그먼크의 각 변수에 대한 통계 정의
-
이상이나 푸아송 변수의 경우 평균만 지정하면 된다

-
정규 변수의 경우 분포의 분산, 평균 주위의 분산 정도를 추가로 지정해야 한다
-
세그먼트 크기를 설정하고 모든 변수를 포함하여 전체를 저장할 딕셔너리를 만든다

-
moving_up 세그먼트에 대해 얻은 값 확인

5.1.2 최종 세그먼트 데이터 생성
-
의사 코드를 사용해 실제 프로그램을 작성하기 전 개념적으로 코드를 요약하고 디버그한다
-
원하는 데이터 유형에 따라 적절한 유사 난수 함수를 사용해 데이터를 추출한다
-
단일 명령으로 주어진 세그먼트 내의 주어진 변수에 대한 모든 값을 추출한다

-
데이터셋을 완성하기 위해 몇 가지 작업을 수행해 각 이항 변수를 더 명확한 값, 부울이나 문자열로 변환한다

-
데이터 검사

5.2 그룹별 설명 찾기
-
데이터프레임 인덱싱을 사용해 일부 기준과 일치하는 행을 찾은 다음 관심 있는 변수와 일치하는 관찰에 대한 평균을 가져온다
-
data.groupby(INDICES)[COLUMN].FUNCTION을 사용해 INDICES의 각 고유값에 대해 데이터를 그룹으로 나눈 다음 각 그룹의 COLUMN에 있는 데이터에 FUNCTION 함수를 적용한다
-
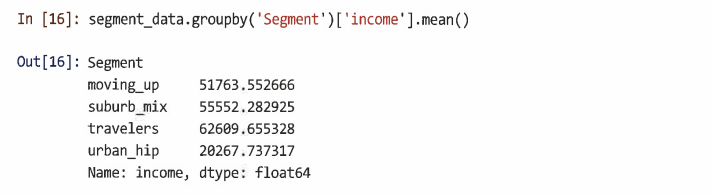
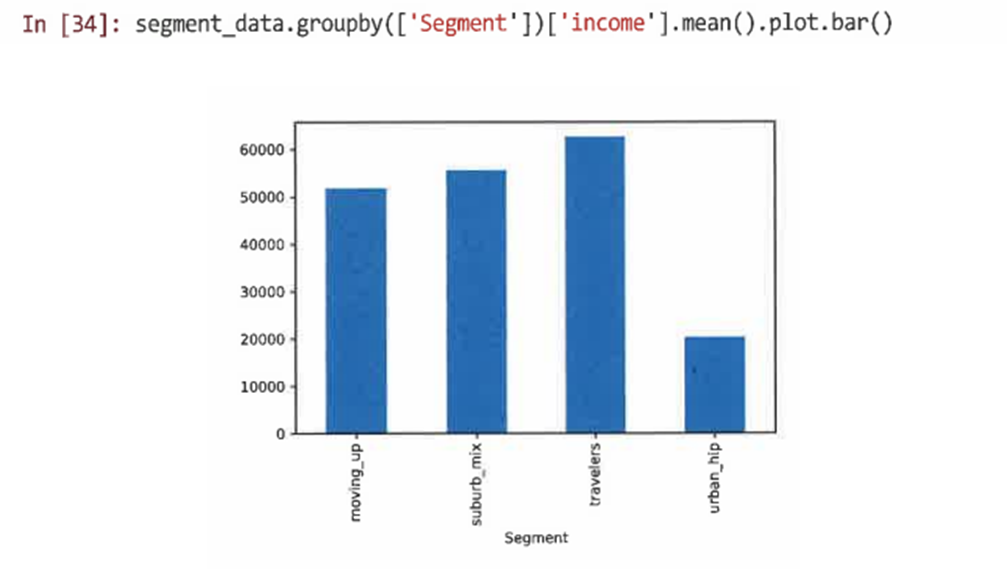
이 경우 'moving_up' 세그먼트의 평균 수입을 찾아본다
-
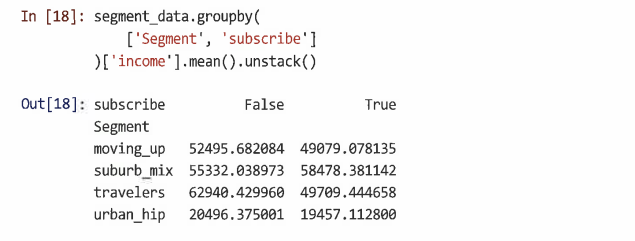
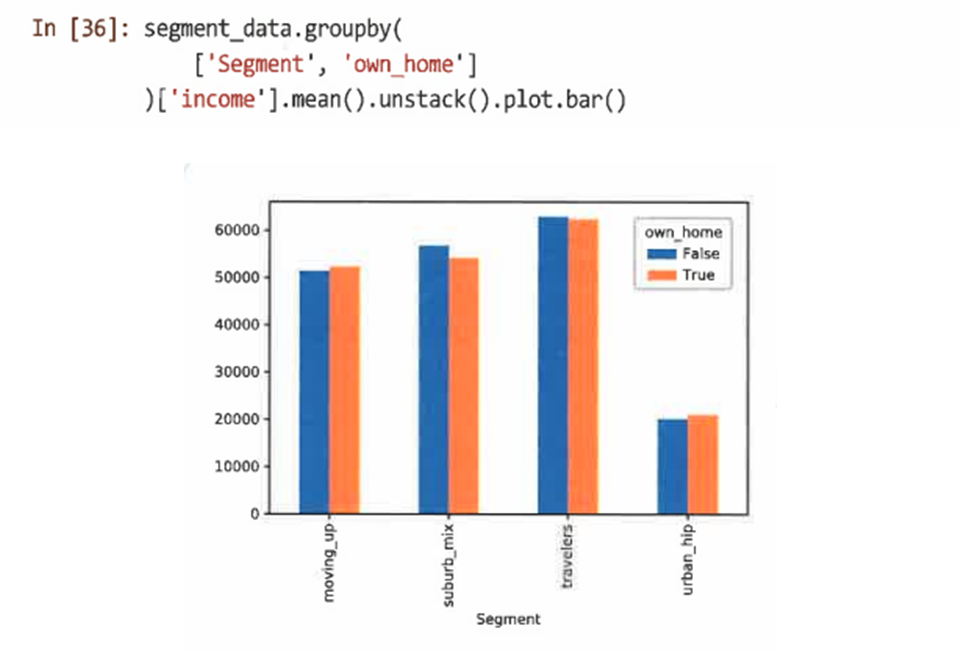
리스트에 요인을 제공하고 출력에 대한 unstack() 메서드를 사용해 결과를 여러 요인으로 나눌 수 있다
-
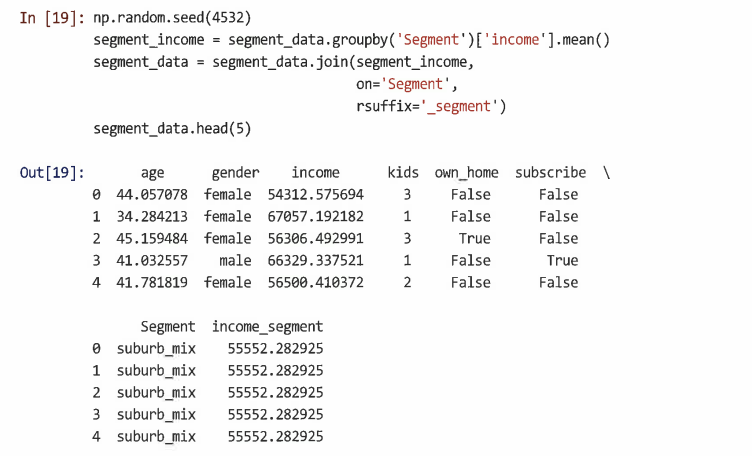
데이터에 '세그먼트 평균'열을 추가한다고 가정: groupby()를 사용해 세그먼트 평균을 얻은 다음 join()을 사용해 열 소득세로 추가할 수 있다
5.2.1 양방향 그룹에 대한 설명
-
그룹화는 필요한 만큼 그룹화 변수를 포함하도록 확장할 수 있다

-
count() 메서드와 함께 groupby()를 사용해 빈도를 계산하면 단방향이나 다방향 개수를 얻을 수 있다

-
각 가구의 아동 수(kids)를 세그먼트별로 분류한다고 가정
-
여기서는 kids를 숫자가 아닌 요소로 취급하고 있음을 알 수 있다

-
그러나 kids는 실제로 개수 변수이다 => 각 세그먼트에 보고된 총 어린이수를 얻기 위해 개수를 합산할 수 있다

5.2.2 그룹별 시각화: 빈도와 비율
-
각 세그먼트의 구독자 수를 도식화
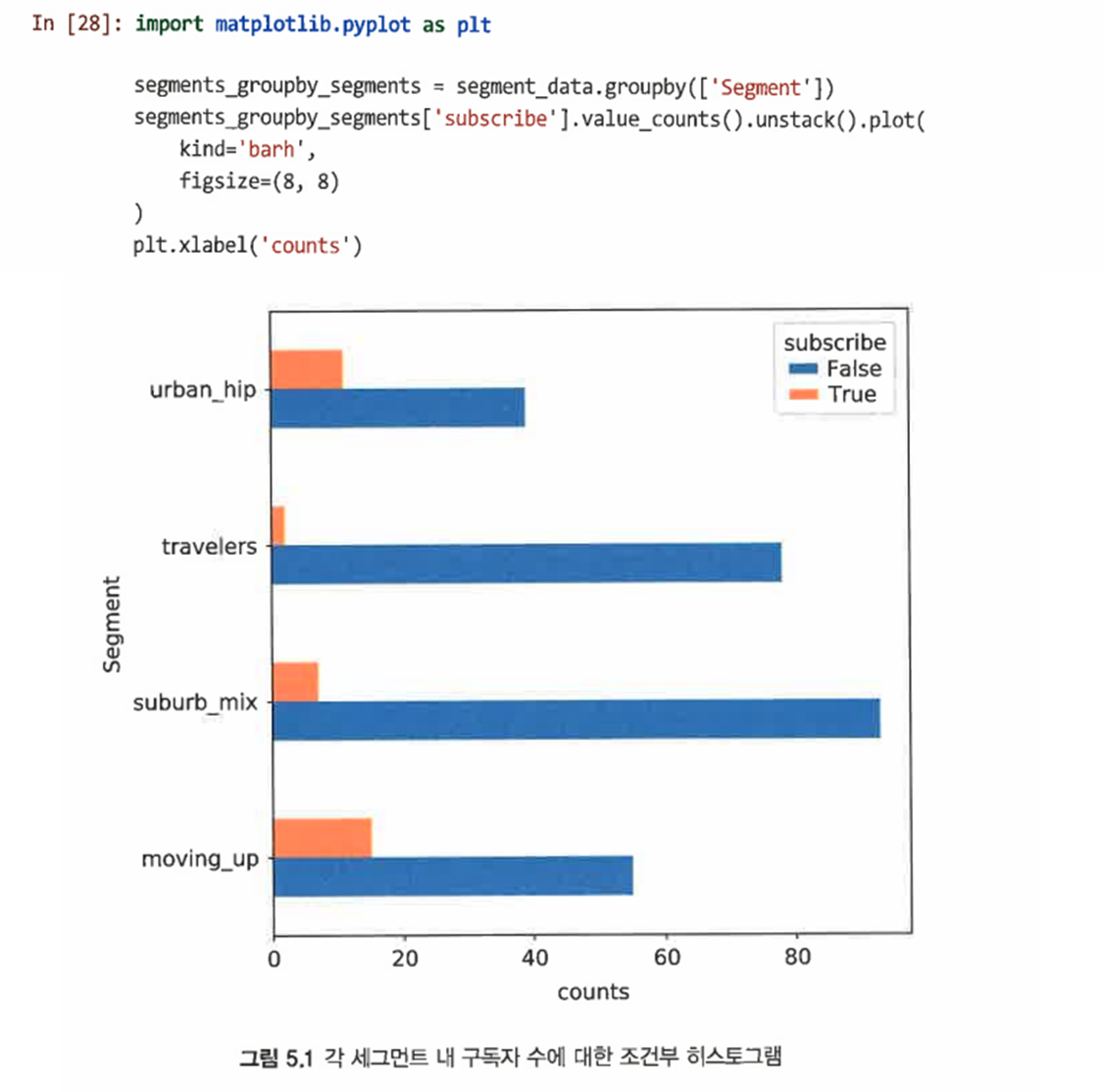
-
value_counts()에 normalize=True를 전달하면 각 세그먼트 내에서의 비율을 얻을 수 있다
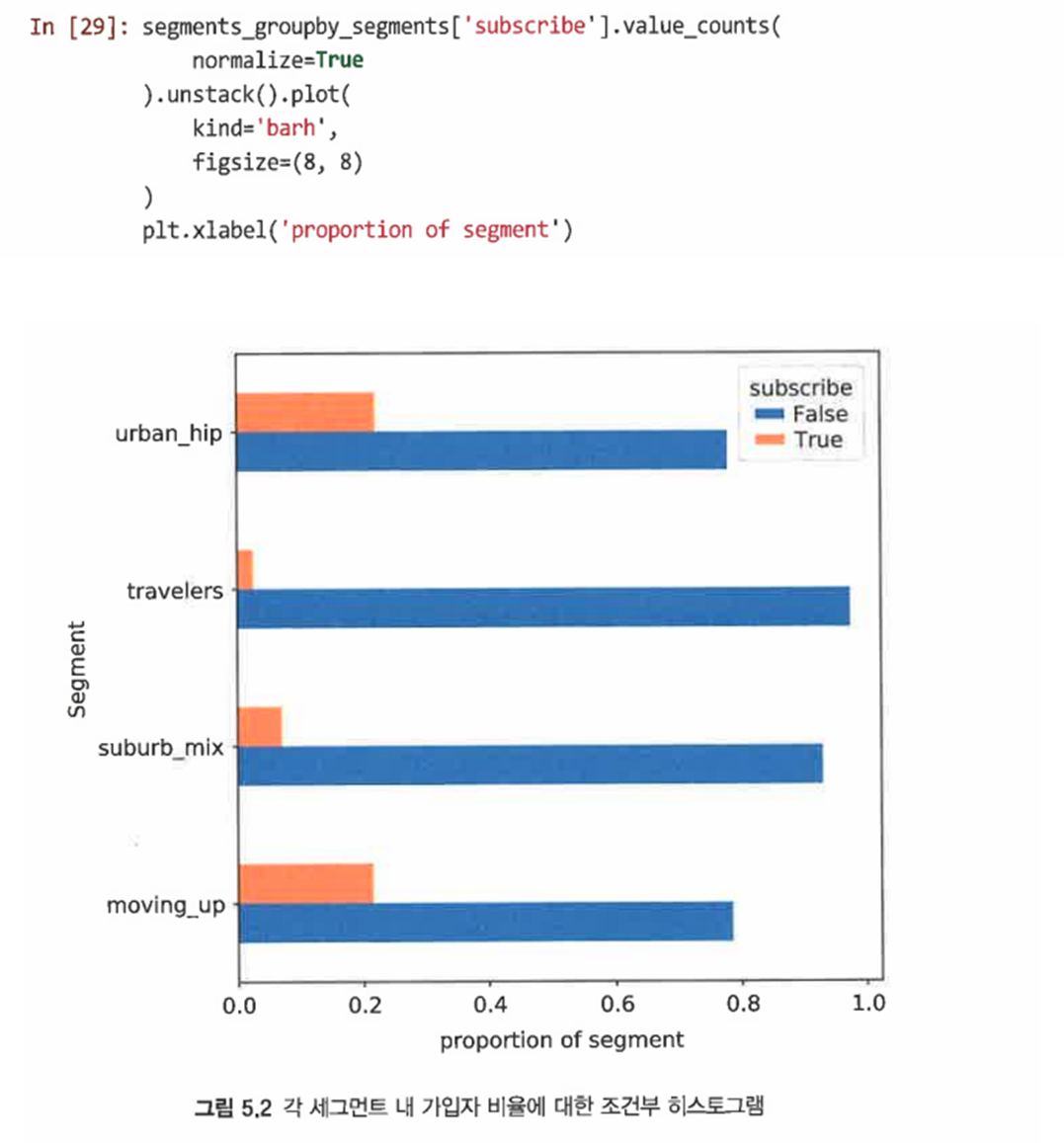
-
subscribe로 집계하고 Segment에서 value_counts()를 실행하면 구독자와 비구독자의 세그먼트별 분석을 볼 수 있다
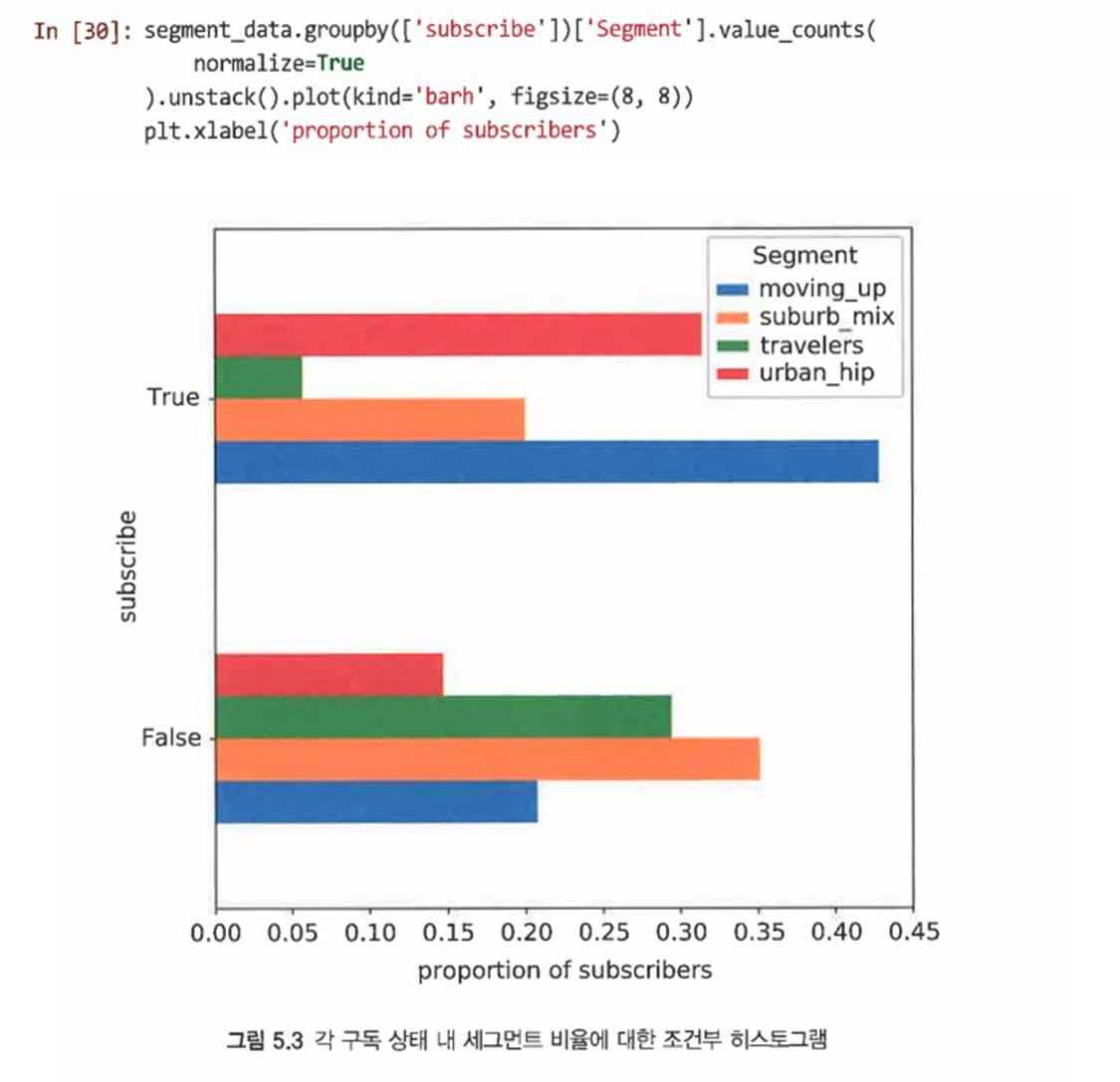
-
seaborn 패키지의 facegrid() 함수를 사용하여 다중 패널 그림을 만들 수도 있다
-
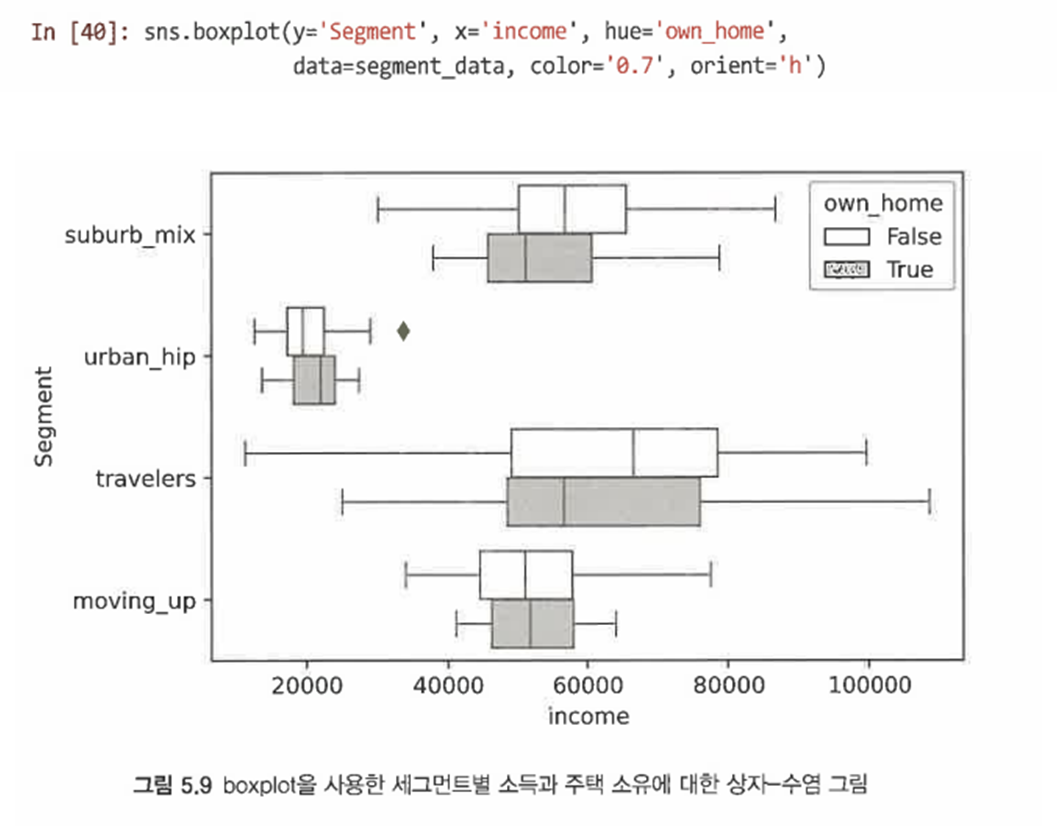
이를 이용해 주택 소유와 같은 요인을 별도로 분리해 비교할 수 있다
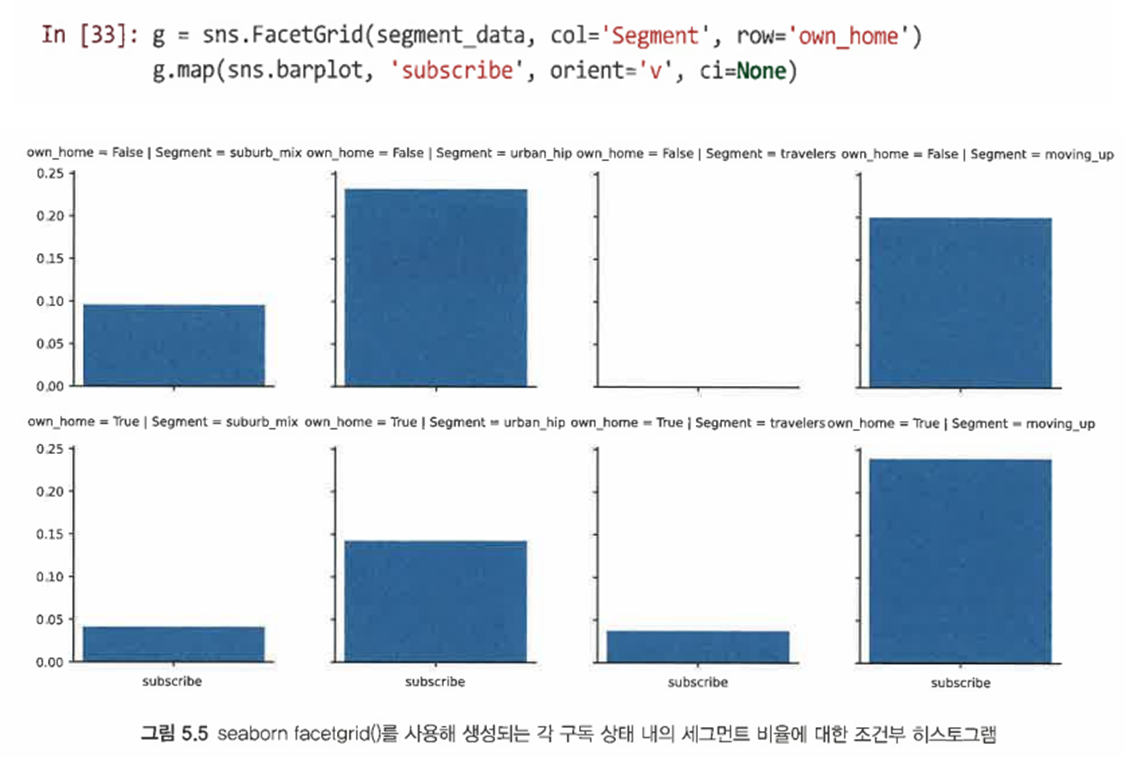
5.2.3 그룹별 시각화: 연속 데이터
-groupby()를 사용해 평균 수입을 찾은 다음 plot(kind='bar') 메서드를 사용해 계산된 값을 도식화
-
matplotlib를 사용해 다른 요소를 추가할 수 있다
-
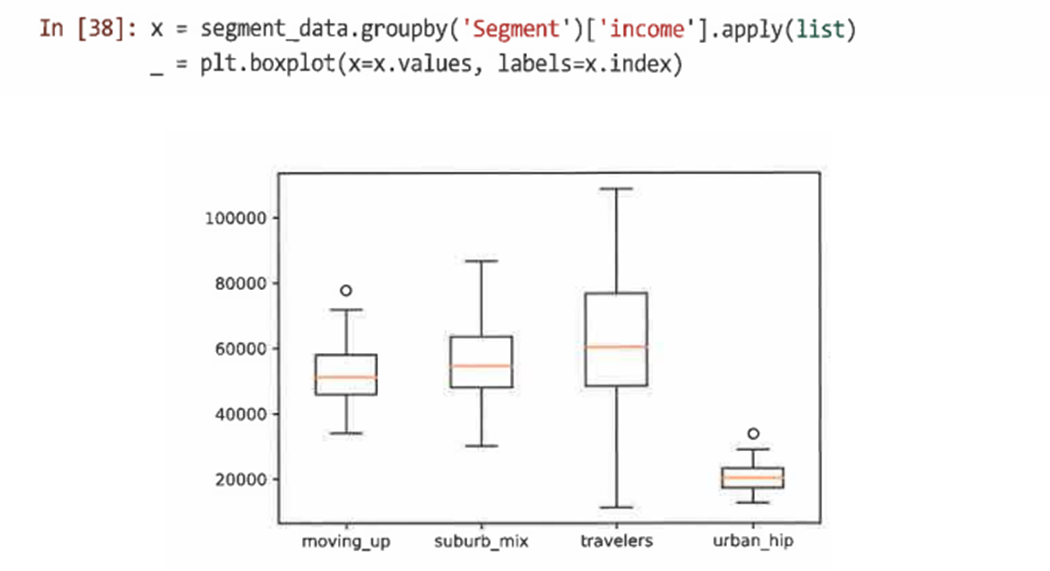
다른 그룹의 연속 데이터 값을 비교하기 위해 boxplot() 함수를 사용할 수 있다
-
hue 인수를 추가하여 더 많은 요인으로 분류할 수 있다
5.3 요점

