
- 전체보기(125)
- 코테(75)
- python(42)
- mysql(40)
- 데이터분석(17)
- 데브코스(17)
- level2(9)
- level1(5)
- 정리(4)
- 프로그래머스(3)
- 에러(2)
- Argparse(1)
- konlpy(1)
- rust compiler(1)
- Index(1)
- pip(1)
- lambda(1)
- RANK(1)
- ekphrasis(1)
- 가상환경(1)
- reculsive(1)
- bool(1)
- git-lfs(1)
- Sort(1)
- count(1)
- transformers(1)
- Lv2(1)
- Pop(1)
- remove(1)
- 오류(1)
- conda activate(1)
- reverse(1)
- SQL 궁금(1)
- isNaN(1)
- RDBMS(1)
- 궁금(1)
- 윈도우 pip(1)
- Map(1)
- twine(1)
- DATE 추출(1)
- 패키지모듈import(1)
- level0(1)
- Level 1(1)
- sql(1)
- pypi(1)
- INSERT(1)
- 약수(1)
[MySQL] JOIN 되는 일부 컬럼은 그룹화가 필요 없다.
이 문제를 풀면서 평소와 같이 쿼리를 아래처럼 작성했다.근데 계속 이런 쿼리에서 걸리는 점이 GROUP BY할 때 사실 DEPT_ID 하나만 해도 상관없는데, GROUP BY 사용할 때 SELECT 절에 올 수 있는 건 그룹화 대상이거나, 집계함수라고 알고 있었어서 계
[MySQL] GROUP BY와 PARTITION BY의 차이
이 문제에서 사원별 SCORE(상반기 score+하반기 score)를 기준으로 랭킹을 매겨야하는데, 윈도우 함수를 사용하며 어려움이 있었다.처음엔 이렇게 CTE로 SCORE와 RANKING을 구해서 1위 데이터만 뽑아보려고 했는데, 오류가 났다!GROUP BY를 사용하
[프로그래머스] 뒤에 있는 큰 수 찾기
https://school.programmers.co.kr/learn/courses/30/lessons/154539리스트가 주어질 때, 각 원소의 뒤에 있는 원소 중 자신보다 크며, 가장 가까이 있는 수를 뒷 큰수라고 할 때, 각 원소별 뒷 큰수가 담긴 리스트
프로그래머스 level 1,2 정리
증가폭이 0이면 안된다.range에서 3번째 인자인 증가폭(step)이 0일 경우 오류 남! 유의해서 코드 작성하기reversed문자열을 뒤집어주는 함수. 참고: 리스트는 ::-1과 같이 쓸 수 있음deldel arr\[1]과 같이 사용함poparr.pop(1)과 같이
[MySQL] 자동차 대여 기록 별 대여 금액 구하기
https://school.programmers.co.kr/learn/courses/30/lessons/151141길게도 썼다. 처음 생각했던 구성에서 오류난 걸 고치고 고치다보니 이렇게까지 길어졌다.처음엔 7일 이하의 렌트에 대해선 할인이 적용되지 않기 때문
[mysql] group by와 case문 함께 사용하기
https://school.programmers.co.kr/learn/courses/30/lessons/276036위 문제를 풀다가 난관에 봉착했다.개발자 별로 스킬을 확인해야하기에, group by를 사용해야하는데 그 안에서 등급 지정을 위해 case문을 써
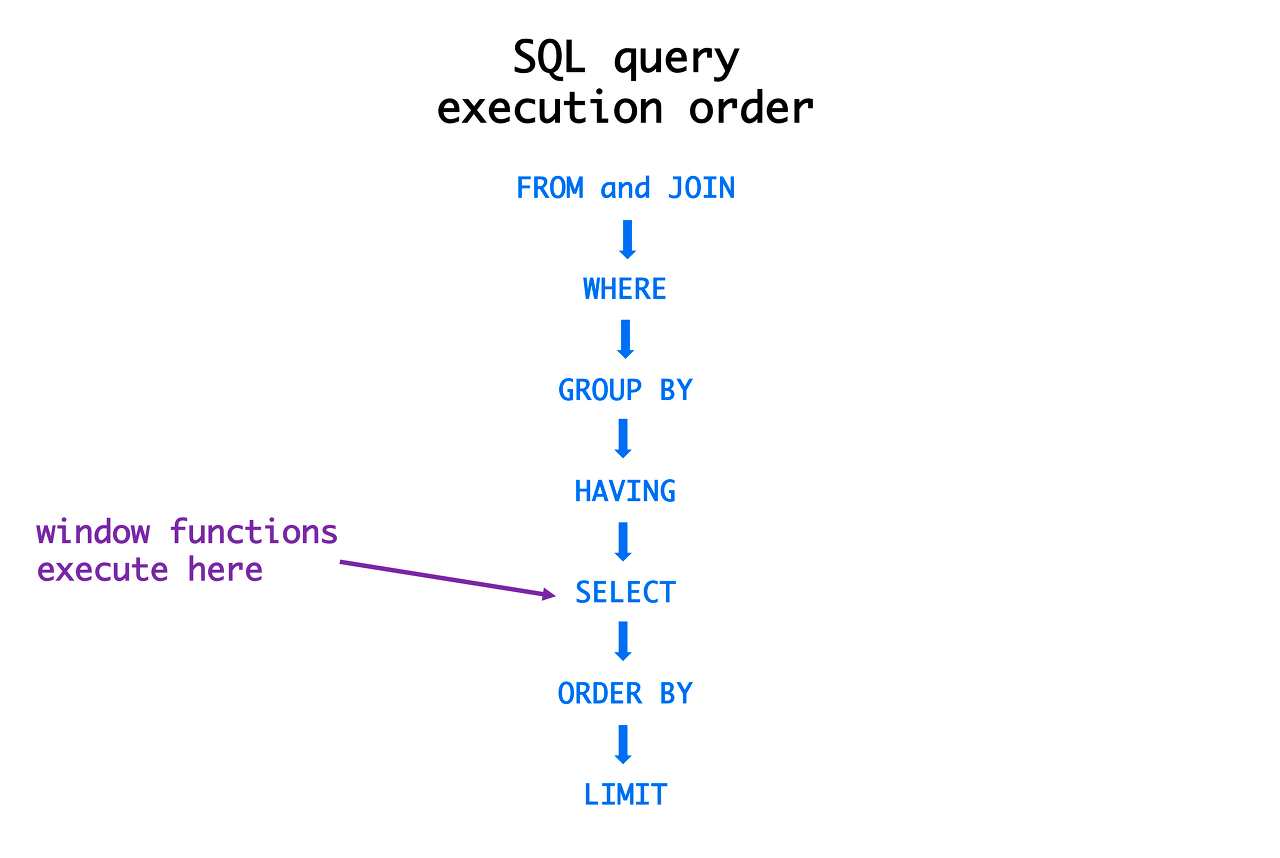
[MySQL] group by에서 select 절의 alias를 사용할 수 있나? 인덱스는?
코테 연습을 하다가 갑작스레 궁금해졌다.group by절은 select보다 먼저 실행되는데 어떻게 alias를 사용해도 되지?대답은,, mysql에서 가능한 것이라고 한다. 즉 DBMS가 알아서 처리해준다는 말씀사실 내가 궁금했던건 따로 있는데, 바로 group by
MYSQL) Recursive 문법
sql에서 재귀를 쓰는 방법이다!나는 해당 문제를 풀 때, 하드코딩(?)을 사용했는데 다른 사람들이 푼 걸 보니 재귀를 사용하길래 찾아봤다.기본 구조는 위와 같다.UNION ALL 윗 부분이 비재귀 부분이며 초기값을 설정한다.UNION ALL을 통해서 위와 아래 쿼리를
MYSQL) RANK 함수
RANK 함수는 말 그대로 순위를 매기는 함수이다. RANK() OVER(\[PARTITION BY COLUMN_1] ORDER BY COLUMN_2 \[DESC])위와 같이 사용되는데, 여기서 파티션은 그룹별로 그룹 내에서 랭킹을 매길 때 사용한다.나같은 경우는 해당
데브코스 50일차 - 딥러닝(CNN, RNN, 교차검증, 평가지표)
딥러닝, CNN, RNN학습을 통해 (사람처럼) 예측을 진행 → 어떻게 학습? (사람의 인지과정)사람의 신경망(사람을 모방)을 기반으로 학습과 추론을 진행하는 학문사람의 신경 구조는 뉴런을 기본 단위로 함 (뉴런 → 신경계)뉴런을 모방한 퍼셉트론을 수학적으로 모델링.
데브코스 49일차 - 머신러닝(K-means Clustering, Isolation Forest)
k-means clusteringK-평균 군집화전체 데이터를 K개의 덩어리(클러스터)로 나누는 비지도 학습법각 클러스터의 좌표 값의 평균으로 중심을 정할 수 있음로이드 알고리즘 vs 엘칸 알고리즘(거리 계산시 삼각 부등식 사용)순서초기화K개의 클러스터 중심점(최종 결과
데브코스 48일차 - 머신러닝(SVM, Decision Tree, 비지도 학습)
SVM, Decision Tree, 비지도학습각 클래스의 데이터 샘플로부터 거리(마진)가 가장 멀리 위치해있다 → 일반화 성능이 좋다마진을 구성하는 데이터 포인트를 서포트 벡터 라고 함SVM의 경우 마진을 최대화하는 최적 직선(최대 마진 초평면)을 만드는 것이 목적임최
데브코스 47일차 - 머신러닝(선형회귀/분류)
사이킷런사이킷런: 다양한 머신러닝 알고리즘이 구현되어있는 오픈소스 패키지데이터 처리, 파이프라인, 학습 알고리즘, 전/후 처리 등 다양한 기능객체 메소드Estimator: fit()으로 학습 진행Predictor: predict()로 예측 수행Transformer: t
[프로그래머스 SQL] 동명 동물 수 찾기
https://school.programmers.co.kr/learn/courses/30/lessons/59041동명의 동물 수 세기 (두 번 이상)이름이 없는 동물은 집계에서 제외설명 그대로 동명의 동물 수를 세기 위해 name으로 group by해 coun
데브코스 46일차 - 머신러닝 (개념, 선형대수, 확률)
머신러닝, 선형대수, 확률머신러닝이란?데이터에서 지식을 추출. 머신 스스로가 데이터의 특징과 패턴을 찾아냄명시적 프로그래밍의 한계를 극복할 수 있는 기법인공지능: (단순히) 기계가 사람의 지적 능력을 모방하는 것어떻게 할 것이냐? → 학습을 통해 예측을 진행 (머신러닝
데브코스 40일차 - 데이터 웨어하우스 심화
데이터 웨어하우스, ETL, ELT, 데이터 파이프라인데이터 웨어하우스고정비용 옵션 (redshift)가변비용 옵션 (bigquery, 스노우 플레이크)데이터 레이크구조화 데이터 + 비구조화 데이터(로그 파일)보통 클라우드 스토리지가 됨데이터 레이크에 있는 정보를 정제
:< [프로그래머스 SQL] 물고기 종류 별 대어 찾기
https://school.programmers.co.kr/learn/courses/30/lessons/293261물고기 종류 별 가장 큰 사이즈의 물고기의 ID, FISH_NAME, LENGTH을 조회물고기 종류 별 가장 큰 사이즈를 조회하는 서브쿼리(FIS
데브코스 35일차 - 데이터 모델링(2)
평가/분석 방법문 같이 생긴 기호가 productsklearn.naive_bayes의 CaussianNB를 import 해 사용모델을 어떻게 평가할지, 기준을 정해야함회귀 평가 방법MSE (Mean Squared Error)오차 제곱의 평균오차값이 큰 데이터점(outl
데브코스 34일차 - 데이터 모델링 (1)
데이터 모델링, 회귀분석주어진 데이터에서 사용하고자 하는 x(feature, input, 독립변수), 알고싶은 값 y(label, output, 종속변수)이 있을 때 y=f(x)라는 함수를 통해서 x와 y의 관계를 설명할 수 있다면?y와 x의 관계를 효과적으로 설명하는
데브코스 31일차 - 데이터 분석, 스케일링
데이터분석, 스케일링나스닥 시총 상위 기업을 보면 제조업 → 서비스 기업으로의 경향을 보임아마존 → 구매 예측을 통한 추천데이터를 정리, 변환, 조작, 검사하여 인사이트를 만들어내는 작업의사 결정의 판단 기준이 ‘주관적인 직감’에서 ‘객관적인 데이터’로!단순한 분석보단