키워드
딥러닝, CNN, RNN
딥러닝 개요
-
학습을 통해 (사람처럼) 예측을 진행 → 어떻게 학습? (사람의 인지과정)
-
사람의 신경망(사람을 모방)을 기반으로 학습과 추론을 진행하는 학문
- 사람의 신경 구조는 뉴런을 기본 단위로 함 (뉴런 → 신경계)
- 뉴런을 모방한 퍼셉트론을 수학적으로 모델링. 이를 기본단위로함. (퍼셉트론 → 모델)
- 풀어야 하는 문제에 따라 다른 구조의 퍼셉트론 모임(모델)을 사용
- 퍼셉트론을 잇는 게 가중치임
- 앞선 퍼셉트론에서 정보 출력 → 가중치를 기반으로 신호 필터링 → 신호 수신 → 연산 및 신호 전달 여부 결정 → 신호 출력 → 반복
- 퍼셉트론을 다양하게 배치해 데이터 특성에 맞는 구조를 설계 가능(모델 크기 조절 가능)
-
이미지 데이터는 CNN이 기본 구조임
-
텍스트 데이터는 attention 모듈이 주로 사용됨. 초기엔 RNN이 사용되었음
이미지 처리(CNN)와 텍스트 처리(RNN)
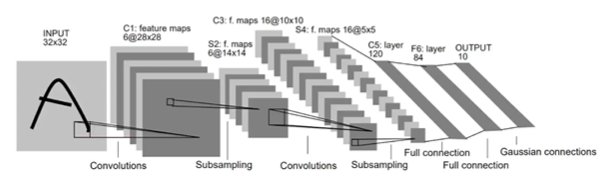
CNN
- 사람의 ‘본다’
- 분석 단위를 설정 후 정보를 추출
- 주변 정보를 통합해 차츰 상위 개념을 구성
- 목적하는 상위 개념에 도달할 때까지 반복 ⇒ 즉 우리는 작은 곡선과 직선의 의미를 통합하는 과정으로 이미지를 판단
- CNN의 본다
-
Convolutional filter (이미지를 부분적으로 보는 정보 처리기)
-
pooling (주변 정보를 모아 상위 개념을 만듦)
-
반복
-
RNN
- 사람이 ‘읽는다’
- 문장 앞에서부터 한 단어씩 읽음
- 새로운 단어가 들어오면 읽고 이해
- 앞서 해석해 만들어낸 기억 정보에 정보를 추가해 기억을 업데이트
- 반복
- 딥러닝(RNN)의 본다
- 앞에서 한 단어씩 입력으로 받음
- 새 단어가 들어오면 처리해서 정보 추출
- 앞서 해석해 만들어낸 정보 덩어리에 추출한 정보를 추가해 정보를 업데이트
- 반복
- RNN
- 이웃한 텍스트 글자 간의 연관성을 표현하는 방식으로 정보 처리 (hidden state가 기억을 담당)
- Attention
- 모든 데이터를 같은 중요도로 처리하지 않음 → 이를 딥러닝 모델에 적용
이미지 분류 실습
-
선택 가능한 모든 클래스에 대한 정답 점수값을 예측
-
ResNet ← 실습에서 사용할 모델
- layer 수에 따라 성능, 학습 속도가 달라짐 (이 둘은 trade-off 관계)
-
데이터
- 머신러닝 모델은 학습 과정과 똑같은 전처리를 진행한 뒤 추론을 진행해야함
- 학습 결과물 객체(ResNet18_Weights)안에 전처리 과정이 저장되어있음
- weights = getattr(models, weight_name).DEFAULT
- transform = weights.transforms() → 전처리 함수
- 즉, transform(image_data) 하면 데이터가 전처리 되는 것
- 머신러닝 모델은 학습 과정과 똑같은 전처리를 진행한 뒤 추론을 진행해야함
실습
- 즉 데이터를 새롭게 불러와서 모델 학습시 사용됐던 전처리 적용
- 전처리된 데이터를 모델의 input으로 넘겨줌
- 해당 모델의 경우 학습된 클래스가 100개이므로 100개에 대한 logit(?)이 출력됨
- softmax를 사용해 각 클래스 별 확률을 뽑고 가장 높은 확률을 갖는 클래스로 추론
성능 평가
교차 검증 (Cross Validation)
검증 → 모델의 학습이 잘 진행되었는지(일반화 능력)를 판단하는 평가 과정
-
검증 데이터가 너무 쉬우면 학습 과정과 결과를 명확히 확인할 수 없으며, 실제 적용에선 좋은 결과를 얻을 수 없음
-
이를 방지하기 위해 교차검증이 사용됨
-
교차검증
- 전체 데이터를 여러개의 하위 데이터로 나누고, 하위 세트들의 조합은 서로 다른 방법으로 훈련과 검증에 사용해 일반화 능력을 충분히 측정하는 것
- 시간 복잡도 측면을 제외하고 일반적인 랜덤 검증 데이터 활용 방법보다 좋은 방법
- 일반화 능력 추정, 데이터 활용 최대화
- 조합을 어떻게 만들어내냐에 따라 여러 방법이 존재
-
K-Fold CV
- 전체 데이터를 k개의 덩어리(fold)로 나누고 각 덩어리를 순차적으로 검증 데이터로 사용
- K번의 학습 및 평과 과정이 반복
- 모든 데이터가 학습 및 평가로 사용됨
-
계층적 교차 검증
- k-fold와 유사하지만, 각 폴드에서 클래스의 비율을 원본 데이터셋의 클래스 비율과 유사하게 유지 (stratified)
- 각 클래스 별로 데이터를 k개로 분할해서 조합
- k-fold의 장점과 더불어, 클래스 사이의 불균형이 있는 경우의 편향까지 고려
-
LOOCV (Leave-One-Out Cross Validation)
- 하나의 데이터만을 검증 데이터로 사용 (극단적인 K-Fold CV)
- 전체 데이터 수 = K
- 매우 정확하지만, 데이터의 크기가 크다면 매우 많은 시간이 소요됨. 작은 데이터셋에 유용
# k-fold
np.mean(cross_val_score(logistic_reg, X, y, cv=5)
# stratified
np.mean(cross_val_score(logistic_reg, X, y, cv=StratifiedKFold(5))
# LOOCV
np.mean(cross_val_score(logistic_reg, X, y, cv=LeaveOneOut())- 그러면 이렇게 교차 검증을 사용한다면 학습은 어떻게 진행되는거지..? 모든 데이터에 최소 한번 이상 학습되는건가? 아니면 평균을 내는거면, 그중 어떤 모델을 사용하는거지?
성능 평가 지표(메트릭)
-
성능 평가: 모델의 성능을 객관적으로 측정하고 비교하는 과정에서 사용
- 풀고자 하는 문제에 적지않은 경우로 적절한 메트릭이 없을 수 있음 → 생성 모델의 성능같은 경우
-
분류 문제
- Confusion Matrix
- TP, FN, TN, FN (correcteness, prediction 순서)
- precision: TP / TP+FP (positive로 예측한 것 중 실제 Positive의 비율)
- recall: TP / TP+FN (실제 Positive 중 positive로 예측한 것의 비율)
- ROC curve
- 이진 분류 문제에서 널리 사용되는 성능 측정 도구
- 양성과 음성을 나누는 임계값(threshold)의 변화에 따른 성능을 시각화한 그래프
- X축: FPR (FP/TN+FP), Y축: TPR (TP/FN+TP)
- fpr은 작아야하고, tpr은 커야함
- threshold를 조절하며 roc 값이 달라지는 걸 확인하고 적절한 threshold를 찾는다.
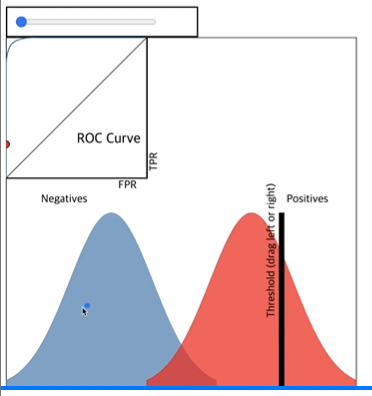
- AUC (Area Under the Curve)
- 음성, 양성을 잘 구분할수록 좋은 분류기임 → roc curve 아래 면적으로 판단할 수 있음
- 최대=1, 최소=0.5(사각형의 반)
- negative와 positive를 잘 구분하지 못한 경우 auc가 작아짐

- Confusion Matrix
-
회귀 문제
- R^2 (결정계수)
- 회귀 모델의 성능을 평가하는 통계적 지표임. 모델이 데이터의 변동성을 얼마나 잘 설명하는지
- R^2 = 1- SSres/SStot
- SSres = 모델 예측값과 실제 값 사이의 제곱합, SStot=실제 값들의 평균과 실제 값 사이의 차이 제곱합. (실제 데이터 내의 총 변동량을 나타냄, 모델이 설명해야하는 전체 변동성의 양)
- R^2가 0이면 변동성을 설명하지 못함을 의미. 단순히 모델의 평균값을 예측
- R^2가 1이면 모델이 데이터의 변동성을 완벽하게 설명함을 의미
- R^2가 클수록 설명력이 크지만, 과적합의 위험성을 주의해야함
- R^2 (결정계수)
복습
- 독립 변수끼린 상관성이 없어야함 → 다중 공선성
- 파라미터의 선형 결합으로 수치를 계산 → 선형 회귀
- 비용함수로 MSE 사용하며, 정규 방정식, 경사 하강법을 사용해 최적화
- 선형 모델로 logit을 예측해 확률 추정으로 선형 분류
- 비용함수로 로그 손실을 사용하고, 경사하강법으로 최적화
- SVM은 두 데이터를 분류하는 최적의 직선을 찾는 문제 → 마진을 최대화(최대 마진 초평면)
- 하드, 소프트 마진(슬랙변수), 선형, 비선형 SVM (커널 트릭 활용)
- 데이터 내에 존재하는 엔트로피, 지니 불순도를 줄이는 방향으로 Tree를 생성 → Decision Tree
- 사람이 보는 방식으로 모델이 시각적 능력을 얻게함 → CNN (convolutional filter, pooling)
- 텍스트와 같은 순차 데이터를 처리하기 위해 RNN 사용 (hidden state)
- 전체 데이터를 K개의 클러스터로 나누는 비지도 학습법 (엘보우 메소드로 k를 찾기)
- sse, 실루엣 계수로 평가
- 이상치 데이터 고립은 낮은 수준의 분할 과정으로도 가능 → Isolation Forest
다음 스텝 소개
- 지도학습 알고리즘
- 앙상블, 랜덤 포레스트, GBM, XGBoost
- 비지도학습 알고리즘
- 차원축소(PCA, t-SNE), DBSCAN
- 캐글 데이터 분석 추천
- 공부하고 싶은 분야, 관심있는 데이터 (취업 희망 회사가 다루는 데이터면 좋을듯)
- 기본적이지만 매우 중요한 EDA 진행
- 전처리(논리 필요)와 학습 진행
- 해석 → 본인 나름대로 모델 결과 해석 진행
