키워드
데이터 웨어하우스, ETL, ELT, 데이터 파이프라인
데이터 웨어하우스
- 데이터 웨어하우스
- 고정비용 옵션 (redshift)
- 가변비용 옵션 (bigquery, 스노우 플레이크)
- 데이터 레이크
- 구조화 데이터 + 비구조화 데이터(로그 파일)
- 보통 클라우드 스토리지가 됨
- 데이터 레이크에 있는 정보를 정제해 데이터 웨어하우스에 적재(기록)할 수도 있음 ⇒ ELT
- 바깥의 데이터를 시스템 안으로 가져오는 과정 (ETL)
- ETL이 실패했을 경우 이를 빨리 고쳐 다시 실행하는 것이 중요 → 이를 적절하게 스케줄하고 관리하는 것이 중요해짐, ETL 스케줄러 혹은 프레임웍이 필요해짐
- Airflow가 대표적인 프레임웍 (ETL 스케줄러)
- ETL이 실패했을 경우 이를 빨리 고쳐 다시 실행하는 것이 중요 → 이를 적절하게 스케줄하고 관리하는 것이 중요해짐, ETL 스케줄러 혹은 프레임웍이 필요해짐
- 데이터 소스
- 프로덕션 데이터베이스(mysql, postgres 등)의 데이터
- 이메일 마케팅 데이터
- 크레딧카드 매출 데이터
- 사용자 이벤트 로그
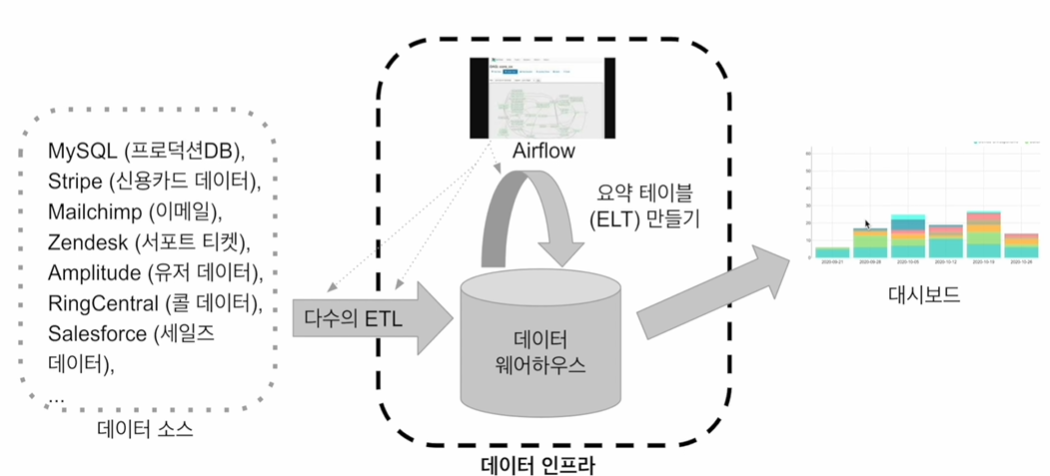
- ELT
- 데이터 웨어하우스 내부 데이터를 조작해 (보통은 좀 더 추상화되고 요약된) 새로운 데이터를 만드는 프로세스
- 데이터 레이크에서 데이터 웨어하우스로 ELT 하는 과정에서 빅데이터 처리 기술이 필요해짐 (spark 등)
- 빅데이터 처리 프레임웍
- 분산 파일 시스템(저장)과 분산 컴퓨팅 시스템(처리)이 필요
- 분산 환경 기반 (한 대 혹은 그 이상의 서버로 구성)
- 소수의 서버가 고장나도 동작해야함 (fault tolerance)
- 빅데이터 프로세싱 시스템
- 하둡, spark
데이터 웨어하우스 옵션들
- AWS Redshift
- AWS 기반의 데이터웨어하우스로 PB 스케일 데이터 분산 처리 가능
- Avro, Parquet과 같은 다양한 데이터 포맷을 지원
- Snowflake
- 클라우드 기반 데이터웨어하우스로 시작됨
- SQL 기반으로 빅데이터 저장, 처리, 분석을 가능하게 해줌
- 실시간 데이터 처리 지원
- Google Cloud Bigquery
- Bigquery SQL이란 SQL로 데이터 처리 가능
- nested fields, repeated fields 지원
- 가변비용 옵션
- Apache Hive
- 하둡 기반으로 동작하는 SQL 기반 데이터 웨어하우스 서비스
- 한 번에 처리할 수 있는 데이터의 양이 크다. (디스크 기반?)
- Apache Presto
- Facebook의 아파치 오픈소스 프로젝트 (Hive와 동일하게 하둡 기반으로 동작)
- 빠른 응답 속도에 좀 더 최적화 (메모리 기반)
- Hive와 Presto가 서로 유사해지는 경향성이 있음
- Apache Iceberg
- 넷플릭스가 시작한 아파치 오픈소스 프로젝트 (데이터 웨어하우스 기술 X)
- HDFS, S3, Azure Blob Storage 등의 클라우드 스토리지 지원
- ACID 트랜잭션과 타임여행(과거 버전으로 롤백과 변경 기록 유지 등등)
- 다른 아파치 시스템과 연동 가능
- Apache Spark
- UC 버클리 AMPLab이 시작한 아파치 오픈소스 프로젝트
- 빅데이터 처리 관련 종합선물세트
- 다양한 분산처리 시스템 지원
- 다양한 언어 지원(자바, 파이썬 스칼라, R)
실리콘밸리 회사들의 데이터 스택 트렌드
- 데이터 플랫폼 방전 단계
- 초기: 데이터 웨어하우스 + ETL
- 발전: 데이터 양 증가 (Spark와 같은 빅데이터 처리시스템/데이터 레이크(비구조화된, 스케일이 큰 데이터를 위해) 도입)
- 성숙: 현업단의 데이터 활용 증대 (ELT단이 더 중요해지면서 dbt 등의 분석 엔지니어링 도입)
- MLOps 등 머신러닝 개발 운영 관련 효율성 증대 노력 증대
클라우드: AWS, Googld cloud, on-premise(자체 서버) 등 ⇒ 데이터 웨어하우스
Big Data 시스템: Spark, snowflake, Hive 등 ⇒ 빅데이터 프로세싱 프레임웍
대시보드: Looker, Tableau 등 ⇒ 시각화 툴
데이터 파이프라인 프레임웍: Airflow, dbt 등 ⇒ ETL 스케쥴러
데이터 파이프라인이란?
- ETL
- Extract, Transform, Load
- 동의어: 데이터 파이프라인, ETL, 데이터 웍플로우, DAG(Airflow에서 사용하는 용어)
- 데이터 파이프라인
- 데이터를 소스로부터 목적지(대체로 데이터 웨어하우스, 데이터가 크면 데이터 레이크)로 복사하는 작업
- 보통 코딩 혹은 SQL을 통해 이뤄짐
- 데이터를 소스로부터 목적지(대체로 데이터 웨어하우스, 데이터가 크면 데이터 레이크)로 복사하는 작업
- Raw data ETL Jobs
- 외부/내부 데이터 소스에서 데이터를 읽어다가(API 사용) 적당한 데이터 포맷 변환 후(데이터의 크기가 커지면 spark 등이 필요해짐) 데이터 웨어하우스 로드
- 이 작업은 보통 데이터 엔지니어가 함
- Summary/Report Jobs
- 소스와 목적지가 동일
- 데이터 시스템 (DW, DL)에서 데이터를 읽어 다시 데이터시스템에 쓰는 ETL
- sql만으로 만들거나, dbt를 이용. 데이터 분석가가 하는 일
- Production Data Jobs
- DW로부터 데이터를 읽어 다른 storage(대체로 프로덕션 환경)로 쓰는 ETL
- 강의 수강생 수, 별점 등의 데이터 처리를 위함
데이터 파이프라인을 만들 때 고려할 점
- 데이터 파이프라인의 실패
- 데이터 소스상의 이슈(포맷 변화)
- 데이터 파이프라인들간의 의존도 이해 부족 (마케팅 채널 정보가 업데이트 안된다면 마케팅 관련 다른 모든 정보들이 갱신되지 않음)
- Best Practices
- 가능하다면 매번 통채로 복사해서 테이블을 만들기 (full refresh)
- 변경된 부분만 복사 (incremental update)
- 데이터 소스가 프로덕션 데이터베이스라면 다음 필드가 필요 (created, modified, deleted)
- 데이터 파이프라인이 멱등성을 보장해야함
- 멱등성: 동일한 입력으로 데이터 파이프라인을 다수 실행해도 최종 테이블의 내용이 달라지면 안됨. 예를 들면 중복 데이터가 생기면 안됨
- 데이터 파이프라인이 중간에 실패하면, 이전 상태로 롤백해야함(SQL transaction과 유사)
- 실패한 데이터 파이프라인 재실행이 중요함
- 과거 데이터를 다시 채우는 과정(Backfill)이 쉬워야함
- incremental update할 때 특히 중요
- 데이터 파이프라인의 입력과 출력을 명확히하고 문서화
- 비지니스 오너 명시 (데이터 요청한 사람)
- 주기적으로 쓸모없는 데이터들을 삭제
- 데이터 파이프라인 사고시마다 사고 리포트(posst-mortem) 쓰기
- 동일한 혹은 아주 비슷한 사고가 또 발생하는 것을 막기 위함임
- 중요 데이터 파이프라인의 입력과 출력을 체크하기
간단한 ETL 작성하기 (실습)
- ETL
- Extract(데이터 소스에서 읽어내는 과정), Transform(원본 데이터의 포맷을 원하는 형태로 변경시키는 과정), Load(DW에 테이블로 집어넣는 과정)
- 웹에 있는 csv파일을 redshift에 있는 테이블로 복사
import requests
def extract(url):
f=requests.get(url)
return (f.text)
def transform(text):
lines = text.strip().split('\n')
records = []
for l in lines[1:]: # 첫 레코드는 헤더이므로
(name, gender) = l.split(",")
records.append([name, gender])
return records
def load(records):
cur = get_Redshift_connection() # 미리 정의해둔 함수 호출
cur.excute("BEGIN;") # 트랜잭션 열기(멱등성)
try:
# full fresh
cur.execute("DROP TABLE IF EXISTS ~.name_gender; CREATE TABLE ~.name_gender (name varchar(32) primary key,gender varchar(8));")
for r in records:
name = r[0]
gender = r[1]
print(name, '-', gender)
sql = "INSERT INTO ~.name_gender VALUES ('{n}', '{g}')".format(n=name, g=gender)
cur.execute(sql)
cur.excute('END')
except (Exception, psycopg2.DatabaseError) as error:
print(error)
cur.execute("ROLLBACK")생각해볼 것
여러분이 좋아하는 주제를 바탕으로 여러분만의 가상의 데이터 웨어하우스를 만든다면 어떤 데이터 소스들을 ETL로 읽어오고 그걸 정리해서 어떻게 요약 정보 (ELT)를 만들어볼지 생각해서 구글닥으로 만들어서 아래 이메일로 공유해주세요!
예를 들어 내가 특정 분야의 음악에 관심이 많다면 관련 내용을 어디서 읽어올 수 있을지 (ETL) 생각해보고 이걸 어떻게 요약을 하면 (ELT) 시각화나 분석이 쉬워질지 생각해보세요. 다시 한번 가상입니다.
