키워드
데이터분석, 스케일링
데이터 분석이란?
- 나스닥 시총 상위 기업을 보면
제조업 → 서비스 기업으로의 경향을 보임- 아마존 → 구매 예측을 통한 추천
- 데이터를 정리, 변환, 조작, 검사하여 인사이트를 만들어내는 작업
- 의사 결정의 판단 기준이 ‘주관적인 직감’에서 ‘객관적인 데이터’로!
- 단순한 분석보단 어떻게 문제를 해결할지에 대한 고민이 중요
- 데이터 분석은 결국 수단임! → 본질(문제 해결)을 잊지 말아야함
데이터 분석 과정
- 문제 정의
- 풀고자하는 문제가 명확하지 않으면 데이터분석은 무용지물이 됨
- 큰 문제를 작은 단위의 문제들로 나눈 후
- 각 작은 문제들에 대해서 여러 가설들을 세우고
- 데이터 분석을 통해 가설을 검증 & 결론을 도출하거나 피드백을 반영
- 해당 문제를 일으키는 원인이 뭔지, 지표가 무엇인지
- 데이터 수집
- 가설 검증에 필요한 데이터가 존재하는가?
- 어떤 종류의 데이터가 필요한가?
- 데이터로부터 얻고자하는 정보가 무엇인지 명확하게 해야 필요한 데이터만 모을 수 있다.
- 얻고자 하는 데이터의 지표가 명확한가?
- 데이터 전처리
- 데이터 추출, 필터링, 그룹핑, 조인 등 (sql)
- 이상치 제거, 분포 변환, 표준화, 카테고리화, 차원 축소 등
- 데이터 분석
- EDA
- 그룹별 평균, 합 등 기술적 통계치 확인
- 분포 확인
- 변수 간 관계 및 영향력 파악
- 데이터 시각화
- 모델링 (머신러닝, 딥러닝)
- EDA
- 리포팅/피드백
- 내용의 초점은 데이터 분석가가 아닌 상대방
- 언어 선택에 주의, 목적을 수시로 상기&재확인
- 적절한 시각화 방법 활용
- 항목간 비교시 원 그래프는 지양, 막대 그래프 위주
- X,Y 축 및 단위 주의
- 시계열은 라인이나 실선으로,
- 분포는 히스토그램이나 박스플롯
- 변수간 관계는 산점도!
- 내용의 초점은 데이터 분석가가 아닌 상대방
데이터 정규화와 스케일링 기법
-
하나의 instance(sample) - 여러 속성값들(feature)
-
피쳐 간 크기 및 단위가 들쭉날쭉하거나 가지는 값의 범위가 크게 다른 경우, 혹은 이상치 문제가 심각한 경우, 데이터 분석이 어려워지거나 머신러닝, 딥러닝 방법을 적용하기 어려워지는 경우가 있음
- 연봉, 나이, 보유 주택 수 등
-
Normalization(정규화): 여러가지 값들이 가지는 범위의 차이를 왜곡하지 않으면서 범위를 맞추는 것
-
min-max normalization
- 모든 피쳐 값이 0~1 사이에 위치하도록 스케일링
- (x-min(x))/max(x)-min(x))
- 피쳐들간의 variance(분산) 패턴은 유지한채로 스케일링됨
- variance가 유지된다는 것은 특정 피쳐의 variance가 매우 큰 경우엔 여전히 데이터분석에 적절치 않을 수 있음
-
z-score normalization(standardization)
- 피쳐값이 평균=0, 표준편차=1 값을 갖는 정규 분포를 따르도록 스케일링
- z = (x-평균)/표준편차 → 표준점수(z-score)
- outlier 문제에 상대적으로 robust한 스케일링 방법임
- 하지만 최소값 최대값 범위가 정해지지 않는 단점이 있음 (평균적으로 -2~2)
-
log scaling
- 피쳐값들이 exponential한 분포(positive skewed, 한쪽으로 치우친?)를 가지는 경우 피쳐값들에 log 연산을 취해 스케일링
- ex 대한민국 국민 연봉의 분포
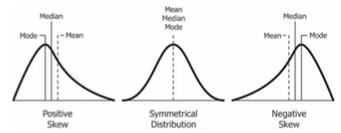
- ex 대한민국 국민 연봉의 분포
- 비슷하게 square root 연산을 취하거나
- 반대의 분포를 갖는 경우 power/exponential 연산을 통해 스케일링 할 수 있음
- 피쳐값들이 exponential한 분포(positive skewed, 한쪽으로 치우친?)를 가지는 경우 피쳐값들에 log 연산을 취해 스케일링
-
다양한 스케일링을 통해 데이터가 좀더 정규분포에 가까워지도록 스케일링하여 outlier 문제에도 좀 더 적극적으로 대응 가능
-
실습
df[’age’].hist(bins=30)→ 특정 피쳐의 값으로 히스토그램을 그려볼 수 있음- bins 값을 키우면 좀 더 촘촘한 히스토그램
scaler = MinMaxScaler()
df['fare_minmax'] = scaler.fit_transform(df['fare'].values.reshape(-1,1))
df['age_minmax'] = scaler.fit_transform(df['age'].values.reshape(-1,1))- min-max의 문제점은 variance가 그대로 유지된다는 것임 (분포의 패턴은 동일, 범위만 달라짐)
scaler = StandardScaler()
df['fare_standard'] = scaler.fit_transform(df['fare'].values.reshape(-1,1))
df['age_standard'] = scaler.fit_transform(df['age'].values.reshape(-1,1))- 실습 데이터에선 조금씩 달라진 걸 확인할 수 있음
# 난수 생성
exp_scale_data = np.random.exponential(1,300)
df_exp = pd.DataFrame(columns=['x'])
df_exp['x'] = exp_scale_data
# log scaling
df_exp['log_x'] = np.log(df_exp['x'])
# outlier 값들이 조금 있지만 비교적 종 모양을 따라감# squre root를 이용한 스케일링
df['fare_sqrt'] = np.sqrt(df['fare'])- 시각화를 통해 데이터의 분포를 살펴보면서 데이터를 스케일링 해주는 것이 효과적이다.
느낀점
- 프로젝트를 하면서 느낀 것들을 압축해놓은 수업이었던 것 같다. 문제 정의를 하는 게 가장 중요하다는 점과, 단순한 분석보단 어떻게 문제를 해결할 것인지 고민하는 게 중요하다는 점.
- 프로젝트 하기 전에 이 내용을 배웠다면...! 그치만 몸소 느끼는 게 더 기억에 오래 남을 수도 있겠지
