키워드
문자열 제어, 데이터프레임 재구성, 시계열 제어
문자열 메소드
-
시리즈와 인덱스에 대한 벡터화 문자열 함수이다.
- 반복문을 사용하지 않고 간단하게 문자열 데이터 처리 가능
-
무조건 str을 사용하고 문자열 메소드를 실행
-
str으로의 형변환 함수가 아니다!
-
대문자, 소문자화
pokemons['Name'].str.upper()- lower()도 동일하게 사용
- 입력단에서부터 대문자로만, 소문자로만 받을 수 있겠으나, 다시 한 번 확인해줄 필요가 있음
-
슬라이싱
pokemons['Name'][0:5]하면 데이터 프레임의 슬라이싱이 일어남pokemons['Name'].str[0:5]하면 각 데이터의 0:5까지만 읽어올 수 있다.[::-1]을 통해 문자열 역정렬이 가능
-
contains(pattern)
- 포함 여부에 따라 불리안 시리즈 또는 인덱스를 반환
- 마스크랑 유사
pkemons[’Name’].str.contains(’q’, case=True)- 이름에 q가 들어간 데이터를 뽑아냄
- case의 디폴트는 true, 이는 대소문자의 구분 여부를 나타냄
pokemons['Name'].str.contains('saur|ragon', case=False)- saur 혹은(or) ragon이 포함되는 데이터 추출
- &도 가능할까?
- 포함 여부에 따라 불리안 시리즈 또는 인덱스를 반환
-
startswith(), endswith()
- case 인자 없음. 대소문자 구분이 디폴트
pkemons[’Name’].str.startswith(’Q’)- 정규표현식 사용 불가
pkemons[’Name’].str.startswith((’Q’,'Pid'))- 튜플로 패턴을 넘겨주면 두 문자열로 시작하는 데이터 추출
-
replace
pokemons['Type 1'].str.replace('Fire','Flame')- Fire를 Flame으로 변경
-
index, columns
- 인덱스와 컬럼도 str 메소드를 사용할 수 있다!
pokemons.index.str[:5]- 앞에서와 동일하게 str 메소드 적용이 가능함
pokemons.columns = pokemons.columns.str.upper()- 컬럼 값들을 대문자로 일괄 변경
데이터프레임 재구성
-
transpose()
league.transpose(),league.T로 트랜스포즈 가능- 디폴트 값이 원본을 바꾸는 것. copy 인자를 True로 넘겨줘서 카피본을 만들 수 있다.
- 행과 열을 교환해 얻는 행렬. 행이 열이되고 열이 행이되고
- 한 데이터프레임을 두번 전치하면 전치 이전과 같을 것 같지만 dtype을 보면 데이터가 모두 object가 됨!
- 하나의 열은 모두 같은 dtype을 가져야함으로 처음 전치를 할 때 모두 object로 변경하는 것. 이후 전치를 하더라도 type이 돌아오진 않음
- 두 번의 전치 후 다시 사용하고싶다면 astype으로 타입을 원래대로 돌려줘야함
-
stack()
- 컬럼 인덱스가 로우 인덱스의 레벨로 이동. 컬럼을 로우로 압축하는 작업 수행
- level 인덱스를 지정해줘서 특정 컬럼인덱스, 로우인덱스를 이동할 수 있다.

- -1 레벨(디폴트값)의 컬럼 인덱스를 로우 인덱스 레벨로 이동
-
unstack()
- stack()을 원상복구, 행을 열들로 옮기는 것
- stack() → stack()하면 멀티인덱스가 만들어짐 (차원이 무너짐. 시리즈화)
-
droplevel()
-
stack, unstack을 하며 생긴 불필요한 인덱스, 열을 삭제하는
-
구조를 바꿔 데이터를 보기 쉽게함
-
-
melt()
- 언피봇
- 데이터프레임의 구조를 변형해 와이드 형식에서 긴 형식으로 데이터를 재구성하는 작업
df.melt(id_vals='이름', value_vars=['국어', '영어', '수학'], var_name='과목', value_name='점수')-
id_vals 열을 기준으로 value_vars 들을 정렬
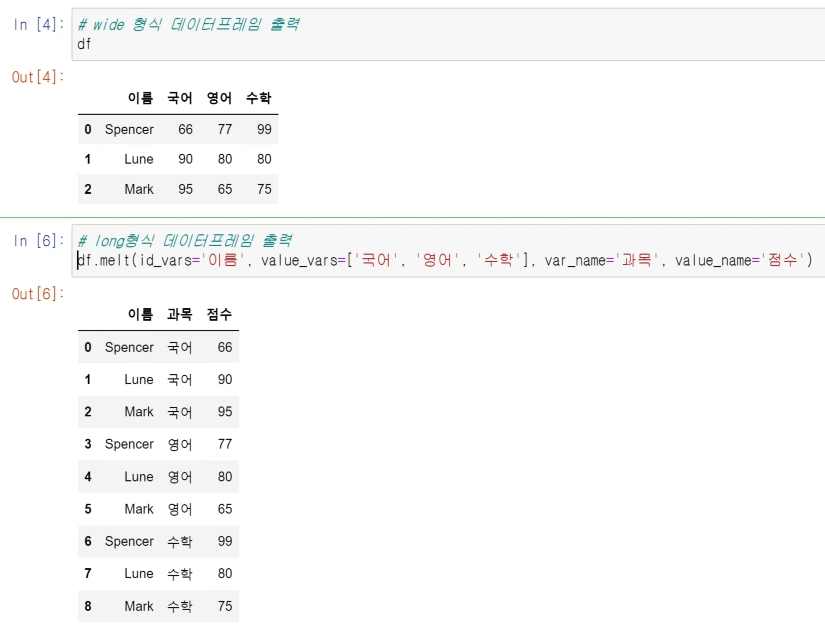
-
- 언피봇
-
pivot()
- 롱형 데이터를 와이드형으로 만들어줌으로써 데이터를 보기 쉽게 만들어줌
company.pivot(index='연도', columns='사원이름', values='연도별매출')- index를 생략하면 기존 인덱스가 들어감
- values를 생략하면 멀티인덱스로 모든 열이 들어감
- pivot과 melt는 서로 다른 기능을 함
-
pivot_table()
- 매개변수를 사용해 엑셀 스타일의 피봇 테이블 생성
company.pivot_table(values='연도별매출', columns='사원이름', aggfunc='sum')- 연도별로 사원이름 기준 value sum. 사원별 누적 연도별 매출
company.pivot_table(values='연도별매출', columns='연도')- 연도별 ‘연도별매출’ 평균 통계내기
- aggfunc이 생략된다면 디폴트로 mean이 실행됨
company.pivot_table(values='연도별매출', columns='소속팀', aggfunc='mean', index='연도')- 소속팀 별 ‘연도별매출’ 평균을 연도별로 보기
- A별 BB의 CCC함수값을 DDDD인덱스로 확인하기
-
.groupby()
- sql의 그룹바이와 다르지 않음
- 그룹으로 나눌 열/열들을 선택 → 그룹 객체에 원하는 연산을 수행
df.groupby('과목')→ DataFrameGroupBy 객체를 반환함 → 데이터프레임에서 이름을 표현할 수 없으므로- 하지만 이를 .groups 해서 딕셔너리 형태로 확인할 수는 있음
- .get_group(key값)으로 접근할 수 있음
- 즉
group = df.groupby(’과목’)하고group.get_group(’과학’)하면 과목 컬럼으로 ‘과학’을 갖는 데이터를 뽑아볼 수 있다.
- 즉
df.groupby(’과목’)[’성적’].mean()하면 과목 별 성적 평균값을 얻을 수 있다.- 두 개의 열 그룹화
types_groups = df.groupby([’Type 1’, ‘Type 2’], dropna=False)- groups를 통해 확인하면 key값이 튜플로 묶여있음
types_groups.max().loc[[’Dark’, ‘Ghost’]]→ 인덱스를 통한 조회와 동일- 특정 타입 조회, 멀티 인덱싱 레벨1
types_groups.max().loc[:, ’Dark’, :]
- 그룹화하면 한 행의 각 열 데이터는 독립적임! 즉 한 행의 name과 HP가 동일한 레코드에서 온 값이 아니라는 것
- groupby 이후 agg 사용
pokemons.groupby('Type 1').agg('Total': ['max','min','mean'])- type 1 그룹 별 Total 컬럼에 max, min, mean 값을 볼 수 있음
- 문자형 컬럼에 적용할 수 있는 agg 함수
- unique, nunique, count, first, last
-
과제
parents_group = df.groupby("부모 학업 성취") analysis = parents_group.agg({'총점':['count','median','max','min','mean','std']}) analysis['총점'].sort_values('mean')- 부모 학업 성취 별 총점 평균에 차이가 있다고 볼 수 있음
시계열 제어
- pd.Timestamp
- 단일의 타임스탬프 객체를 반환
- pd.Timestamp(year=2023, month=12, day=20, hour=13, minute=45, second=56, microsecond=345111, nanosecond=237).tz_localize(’UTC’)
- pd.Timestamp(’2023-12-29T13:45:56.345678901Z’)
- 나노세컨드는 9자리까지만 가능
- pd.Timestamp(’2023-12-29T13:45:56.345678901+09:00’)
- 세계 협정시 조정
- t1.math, t1.day와 같이 접근 가능
- t1.strftime(’%Y-%m-%d %H:%M:%S’)
- 시간 연산 가능
- t2 - t1
- pd.to_datetime()
- 대체로 문자열을 입력 받음. 반면 Timestamp는 문자열, 정수, datatime 객체 등 다양한 형식의 데이터를 입력
- 단일의 타임 스탬프 객체 혹은 데이트타임인덱스 객체를 반환
- Timestamp는 하나만 입력받을 수 있으나, to_datetime은 여러개를 입력받을 수 있음
- to_datetime에 하나라도 잘못된(변환할 수 없는) 데이터가 들어오면 모두 변환되지 않는다.
- errors를 coerce로 설정해 강제할 수도 있다.
- 안되는 건 NaT로 표현하고 되는 것만 변환
- pd.DatetimeIndex()
- 날짜와 시간 데이터를 인덱스로 사용하기 위한 특수 데이터구조
- data_list = [’2023-12-01’,’2023-12-02’,’2023-12-03’,’2023-12-04’]
- pd.to_datetime(data_list) → DatatimeIndex를 반환
- pd.date_range(’2023-12-01’, ‘2023-12-31’, freq=’D’)
- 한번에 datetimeindex 만들기, frequency를 D로 설정해 일별 날짜를 받을 수 있음
- freq를 W-MON으로 설정해 주별 월요일 날짜만 받는 등 주기를 정해줄 수 있다.
- period 인자를 넘겨줘서 기간을 나누는 개수(?)를 지정해줄 수 있음
- pd.Timestamp() → 그 때 (몇분, 몇초)
- pd.period() → 그 날 (시간 데이터 X)
- pd.period_range()
- period_index를 반환
- to_period(), to_timestamp()
- periodindex ↔ datetimeindex 간 변경
- timedelta
- to_timedelta() : day를 기준으로 반환(?)
- 리스트로 입력을 받으면 각각으로 변환
- 여러 값을 하나의 문자열로 받으면 누적값 반환
- timedelta_range(start, periods)
- closed 인자 → 끝점 포함 여부 (left, right, None)
- to_timedelta() : day를 기준으로 반환(?)
- .dt
- .str처럼 .dt 사용! (날씨 속성 접근자)
- *to_frame()을 이용해 체인형으로 시리즈 데이터를 데이터프레임으로 만들 수 있음
- 즉 range index를 series로 변경해주고 to_frame() 적용!
df[’Weeks’].dt.day→ df[’Weeks’] 값들에서 일자를 가져올 수 있음df['Weeks'].dt.strftime('%Y년 %m월 %d일')→ df[’Weeks’] 값을 원하는 포맷으로 출력 가능
- df.index.month_name() → index의 월별 이름을 가져올 수 있음
파일을 읽어오고 to_datetime()을 사용해도 되고, read_csv(’AAPL.csv’, usecols, index_col=’date’, parse_dates=[’date’])처럼 parse_dates 인자를 사용해 object를 date로 변환할 수 있다.
df.index.day_name(locale=’ko_KR.utf8’) 으로 각 데이터에서 요일을 한국어로 뽑아낼 수 있다.
stocks[’date’].dt.strftime(’%Y.%m.%d %H:%M:%S’)
stocks[’date’].dt.strftime(’%Y.%m.%d 시작 9:30’) → 포맷이 아닌 문자는 그대로 출력됨
pd.to_datetime(stocks[’date’], format=’%Y.%m.%d 시작 9:30’)
object가 ‘시작’과 시간을 제외하고 datetime으로 변경됨
-
조회
- .loc[] 시 완전히 매칭이 되지 않아도 데이터를 조회할 수 있음
- stocks.loc[’2015-05-27’] → 시간과 관련된 부분이 작성되지 않았음에도 조회가 됨
- stocks.loc[’2015-6-1’] → 이런식이어도 가능
- stocks.loc[’2015.05’] → 5월 데이터가 조회됨. 년월일이 닷으로 연결되어있지 않음에도 조회됨
- stocks.loc[’2015’] → 2015년 데이터 모두 조회
-
series.reindex(new_index)
- 인덱스를 재배치하고 없는 건 만들어! (변경, 재정렬)
- 즉 set_index와 다른 것은 기존 인덱스를 기반으로 인덱스를 수정하는 것이다!
stocks 데이터는 휴일을 포함하지 않음.
없는 날짜까지 포함해 전체를 인덱스로 설정하고싶다면?
min_date = stocks.index.min()
max_date = stocks.index.max()
new_index = pd.date_range(min_date, max_date, freq=’D’)
stock.reindex(new_index, fill_value='휴장') #-> 비파괴
stock.reindex(new_index).ffill() #-> forward fill을 사용해 nan을 이전 값으로 fill- 리샘플링
- 다운 샘플링
-
ex 주간 평균으로 다운 샘플링
stock_years = stocks.resample(’Y’, kind='period') #-> groupby 때와 동일한 객체 상태 # kind로 period를 설정해 결과 인덱스를 기간 인덱스로 변환 stock_years.group #-> 경계선에 있는 데이터의 인덱스 위치 stock_years.agg(['mean','max','min'])
-
- 업샘플링
- 월별 → 일별/시간별. 만약 일별 데이터가 필요한데 나한텐 월별 데이터밖에 없을 때
- 보간 방식 (interpolate)
- 선형(linear, 디폴트값), 시간(time), 인덱스(index), 패드(pad)
- df.resample(’D’).asfreq().interpolate(method=’time))
- 다운 샘플링
내 생각
- 이야,,,, 새삼 판다스에 많은 함수들이 있었음을 느낀다. 이걸 외운다는 느낌보다는 실습하면서 적용해보면서 익히는 게 맞겠다는 생각이 든다!
- str.contains
|로 여러개의 문자 포함 여부를 한번에 확인할 수 있는걸 보고 혹시&로 and 조건으로도 쓸 수 있지 않을까 했는데 안된다!
