머신러닝 Machine Learning
1.✅ 1. 머신러닝 소개

업로드중..
2.✅ 2. 머신러닝 프로세스

6\. 런칭(디플로잉), 모니터링, 시스템 유지보수
3.모형 청사진 그리기
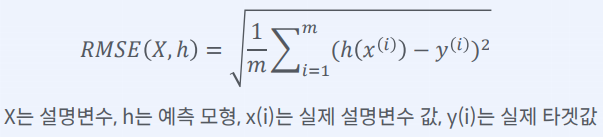
• 카네기멜론 대학교 통계학과에서 무료 공개http://lib.stat.cmu.edu/datasets/• 목표: 1990년 캘리포니아 인구조사 데이터를 통해 캘리포니아의 주택가격 모델을 만드는 것• 설명변수: 블록위치 정보
4.데이터 추출

• fetch_house_data() : 작업공간에 housing.tgz 파일을 다운 받아 압축 해제• pd.read_csv() : 판다스(pandas)의 데이터를 읽어들이는 메소드
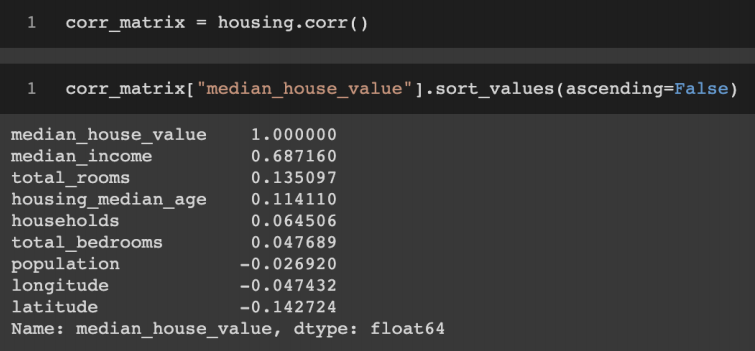
5.데이터 탐색 및 시각화
• 산점도(scatter plot)• 투명도(alpha) : 밀집된 부분을 알 수 있음• 색상(c) : 가격을 기준으로 색 구분• 색상 팔레트(cmap)
6.데이터 준비

• Drop()을 활용• total_bedrooms 변수에 값이 없는 경우 수정 방법1\. 해당 데이터들을 제거2\. 전체 특성을 제거3\. 특정 값으로 대체 ( 0, 평균값, 중앙값 등 )Pandas 데이터프레임의 dropna(),
7.모형 선택 및 훈련
• 선형 회귀모형 훈련 및 예측값과 실제값 비교• 선형 회귀모형 훈련 결과 RMSE 지표로 확인하기 \-> 예측 오차가 $ 68,628라는 점은 매우 만족스럽지 못한 결과라 할 수 있다• Decision Tree 모형 훈련 및 훈련 결과
8.모델 튜닝
• 알고리즘 내 효과적인 하이퍼파라미터 조합을 찾을 때까지,탐색하고자 하는 하이퍼파라미터와 그에 해당하는 시도해볼 값들을 지정하여 하이퍼파라미터 튜닝을 진행하는 것• 사이킷런의 GridSearchCV 클래스를 사용하여,미리 설정한 하이퍼파라미터 조
9.런칭(디플로잉), 모니터링, 시스템 유지보수
서비스 제품 시스템에 모형을 적용하기 위한 준비 진행• 코드 정리 및 문서 및 테스트 케이스 작성 등훈련된 모형을 Joblib 패키지를 활용하여 저장 후,상용 환경에서 로딩 후 predict() 메서드 기반의 예측 모듈 생성웹서비스에서 버튼을 누르면, pre
10.✅ 3. 분류 모델

> 1. 이진 분류 모형 훈련 2. 성능 측정 3. 다중 분류 모형 훈련 4. 에러 분석
11.이진 분류

• 고등학생과 미국 인구조사국 직원들이 손으로 쓴 70,000개 숫자 이미지 데이터 ( 28X28 사이즈 )• 0에서부터 9까지의 숫자로 구성되어있다• 0부터 9까지의 숫자들 중 숫자 5 하나만을 식별해보는 모형을 만들고자 할 때,‘5인 경우’ 혹
12.성능 측정
• 교차 검증을 이용한 정확도• 오차 행렬• 정밀도와 재현율• ROC 곡선성능 지표 비교 : SGDClassifier VS RandomForestClassifier
13.다중 분류
• 둘 이상의 클래스를 구별하는 모형• 알고리즘들의 일부는 다중 분류 기능이 있으나, 이진 분류만 가능한 알고리즘의 경우에는이진 분류를 여러 개를 사용하여 다중 클래스를 분류하는 방법도 있다
14.에러 분석
matplotlib의 matshow() 함수 활용5\. 에러 분석 4: 에러 케이스 이미지 시각화 Matplotlib의 imshow() 함수를 활용
15.✅ 4. 모형 학습 기초 및 회귀 모델

6\. 로지스틱 회귀
16.✅ 6. 결정 트리
7\. 불안정성
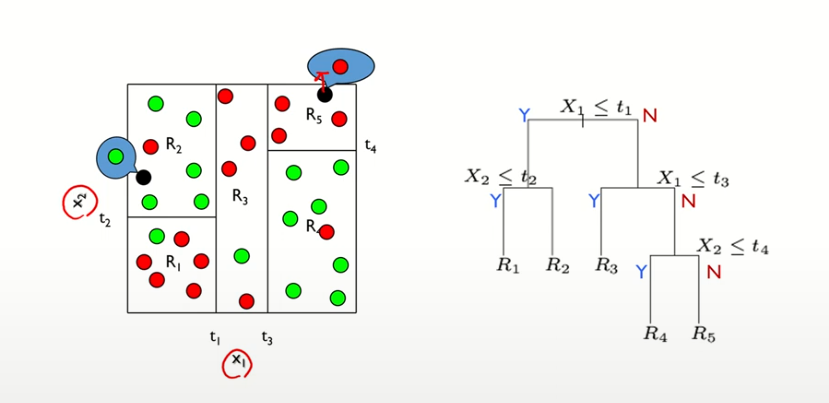
17.CART 훈련 알고리즘
• 먼저 훈련 세트를 하나의 특성 k의 임곗값 𝑡𝑘 를 사용해 두 개의 subset으로 나눈다• 다음, 가장 순수한( gini가 0에 가까운 ) subset으로 나눌 수 있는 (k, 𝑡𝑘 ) 짝을 찾는다• 따라서, CART 알고리즘이 최소화
18.✅ 7. 앙상블 및 랜덤 포레스트

5\. 그래디언트 부스팅 대표 3인방 - XGB, LGB, CatGB
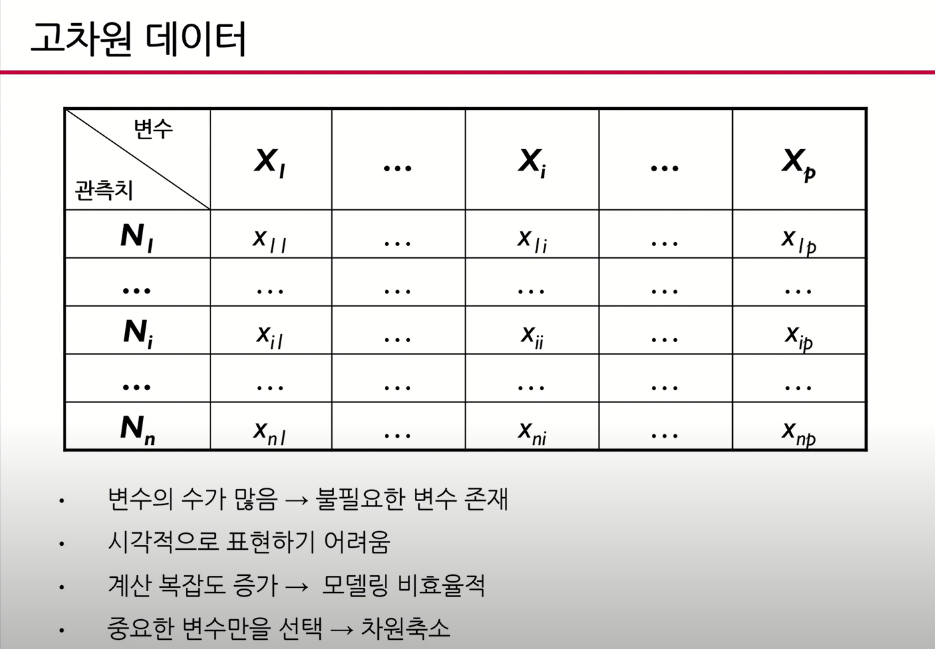
19.PCA(주성분분석)와 LLE(지역선형임베딩) (~사영까지 정리)
• 가장 인기 있는 차원 축소 알고리즘• 데이터에 가장 가까운 초평면을 해석적으로 정의한 후, 그 평면에 데이터를 투영시키는 방법• PCA는 훈련 세트에서 분산이 최대인 축을 찾음1\. 위 그림에서는 실선2\. 또한 첫 번째
20.군집 (Clustering)
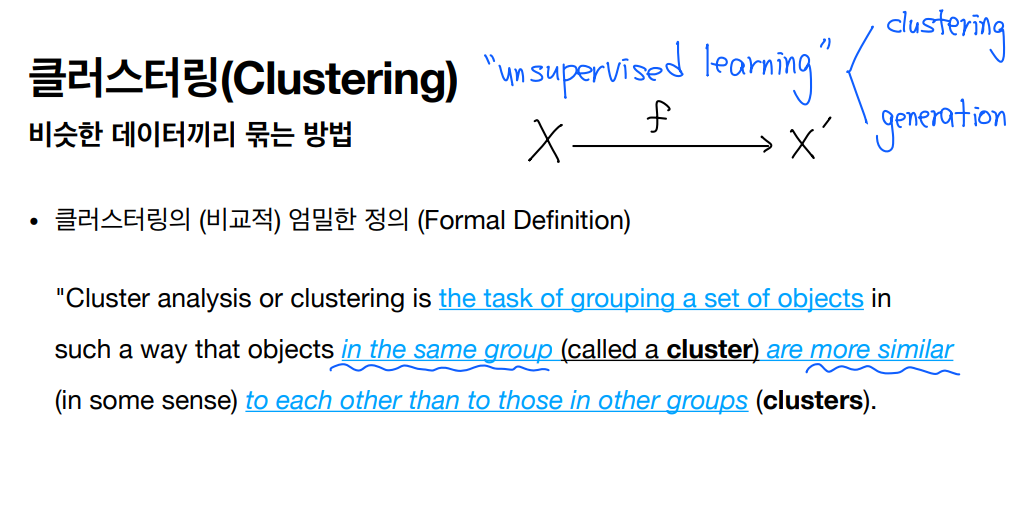
레이블이 없는 데이터를 학습하는 알고리즘• 우리가 사용하는 데이터의 대부분은 레이블(정답)이 없다• 정답이 없는 데이터는 지도학습이 불가능하다• 즉, 강아지와 고양이의 구분조차 처음에는 사람이 직접 라벨링을 해야 하는데, 시간과 돈