1. 설명 변수와 타겟 변수 분리
• Drop()을 활용

2. 데이터 정제
• total_bedrooms 변수에 값이 없는 경우 수정 방법
1. 해당 데이터들을 제거
2. 전체 특성을 제거
3. 특정 값으로 대체 ( 0, 평균값, 중앙값 등 )

Pandas 데이터프레임의 dropna(), drop(), fillna() 메서드를 활용해 간단히 처리할 수 있음
• 누락된 값을 손쉽게 다루는 방법
사이킷런의 SimpleImputer 클래스 활용 -> 중간값으로 쉽게 변형 대체 가능하다

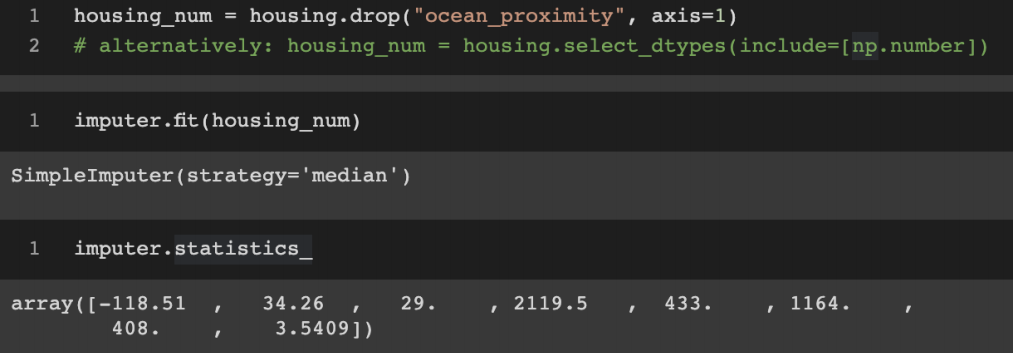

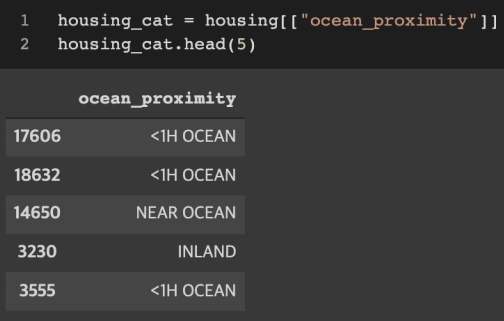
3. 범주형 특성 다루기
- 데이터 확인하기 ( 변수 ocean proximity )
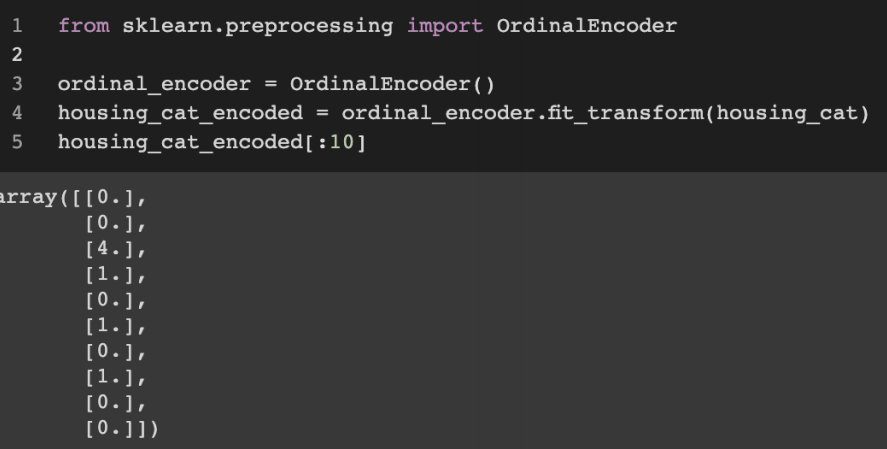
2. 범주형 변수 -> 간단히 수치형 변수로 변환하기
• 사이킷런의 OrdinalEncoder 클래스 사용
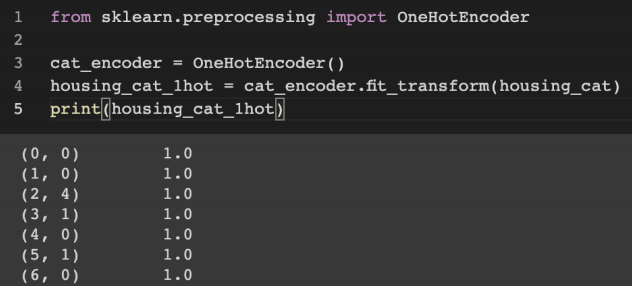
3. 범주형 변수 -> 더미 변수로 변환하기
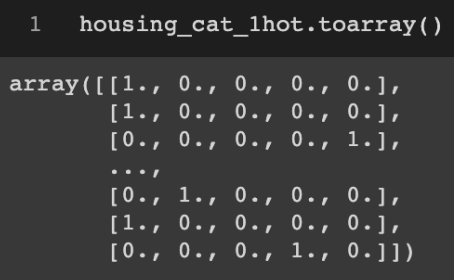
• 사이킷런의 OnehotEncoder 클래스 사용
-> 희소행렬로 출력되므로, toarray() 메서드로 numpy.array화 해주어야 함
4. 변수 스케일링
설명변수들이 나타내는 값의 범위를 유사하도록 스케일링하는 방법
• 머신러닝 알고리즘 학습시, 수치형 설명변수들의 스케일이 많이 다르면 학습이 제대로 되지 않는 경우들이 다수 존재한다
예시) 주택가격 데이터의 경우, 방 개수의 범위는 6~39,320개이며, 중간 소득의 범위는 0~15이다.
• 일반적으로, 타겟 변수에 대한 스케일링은 불필요하다
• 대표적인 방법으로 min-max 스케일링(정규화)과 표준화가 주로 사용된다
1. min-max 스케일링
• 최소값을 뺀 후 최대값과 최소값을 뺀 차로 값들을 나누어 0~1 범위에 속하도록 값을 스케일링
• 사이킷런의 MinMaxScaler 클래스를 통해서 변환가능하다
2. 표준화 ( Standardization )
• 평균을 뺀 후, 표준편차로 나누어, 분포의 평균이 0, 분산이 1이 되도록 변환한다
• 이상치의 영향을 덜 받는다
• 사이킷런의 StandardScaler 클래스를 통해서 변환가능하다
5. 변환 파이프라인
• 변환 단계가 많을 때 사용하는 개념
• 사이킷런의 Pipeline 클래스를 활용
• fit_transform()을 활용하여 한번에 학습 및 변환 진행
6. 변수 변환기
• 범주형 변수와 수치형 변수를
동시에 하나의 변환기로 처리할 때 유용
• 사이킷런의 ColumnTransformer 클래스 활용
