1. 비지도 학습이란?
레이블이 없는 데이터를 학습하는 알고리즘
• 우리가 사용하는 데이터의 대부분은 레이블(정답)이 없다
• 정답이 없는 데이터는 지도학습이 불가능하다
• 즉, 강아지와 고양이의 구분조차 처음에는 사람이 직접 라벨링을 해야 하는데, 시간과 돈 소모 비용이 크다
• 비지도 학습 대표 기능
• 군집(Clustering)
• 이상치 탐지(Outlier Detection)
• 밀도 추정(Density Estimation)
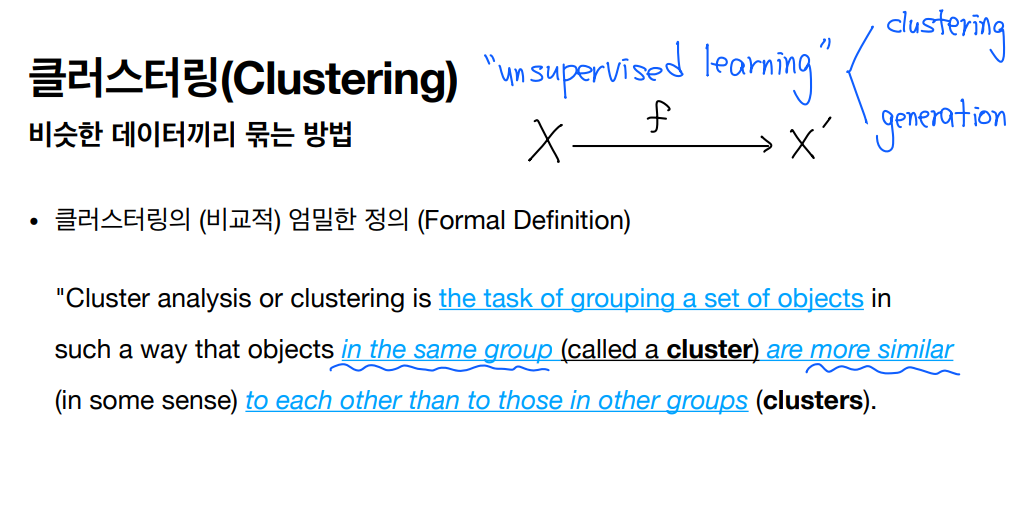
2. 군집 ( Clustering )

비슷한 샘플을 구별해 하나의 클러스터(cluster)로 할당하는 작업
• 분류(왼쪽) vs 군집(오른쪽)
• 활용 예시
• 고객 분류 ‒ 추천 시스템
• 데이터 분석 ‒ 군집 기반 클러스터별 분석
• 차원 축소 기법 ‒ 각 클러스터에 대한 친화성 측정을 통해, 저차원으로 변환
• 이상치 탐지 ‒ 모든 클러스터에 친화성이 낮은 샘플을 이상치로 분류 ( 결함 감지, 부정 거래 감지 등 )
• 준지도 학습 ‒ 일부 레이블된 샘플을 군집화 함으로서 모든 샘플에 레이블을 진행할 수 있음
• 검색 엔진 ‒ 제시된 이미지와 비슷한 이미지를 찾아줌
• 이미지 분할 ‒ 색을 기반으로 픽셀을 클러스터로 모아, 평균 색으로 대체
• Cluster에 대한 보편적 정의는 따로 없으며, 군집 알고리즘에 따라 달라진다
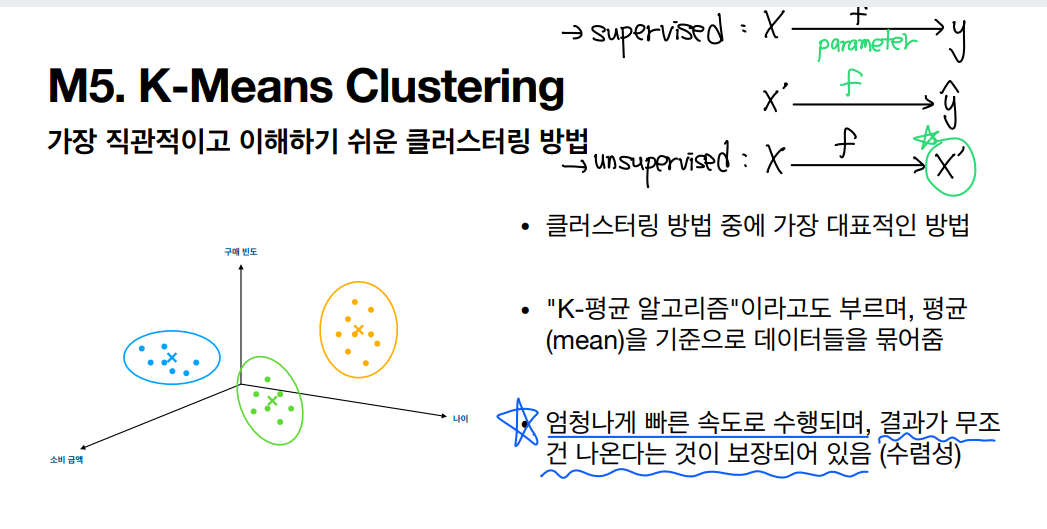
3. k-평균 ( k-means )
각 클러스터의 중심을 찾고 데이터를 가장 가까운 cluster에 샘플을 할당하는 알고리즘
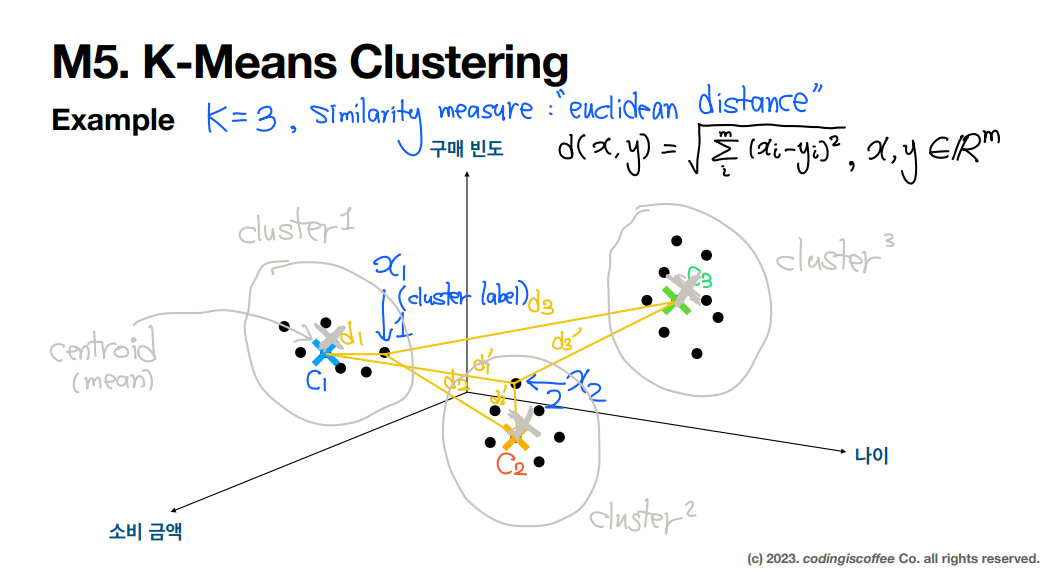

k-평균 중심과 분류값 확인 및 예측하기
하드 군집 vs 소프트 군집
• 하드 군집 : 샘플을 하나의 클러스터에 할당하는 것
• 소프트 군집 : 클러스터마다 샘플에 점수를 부여하는 것
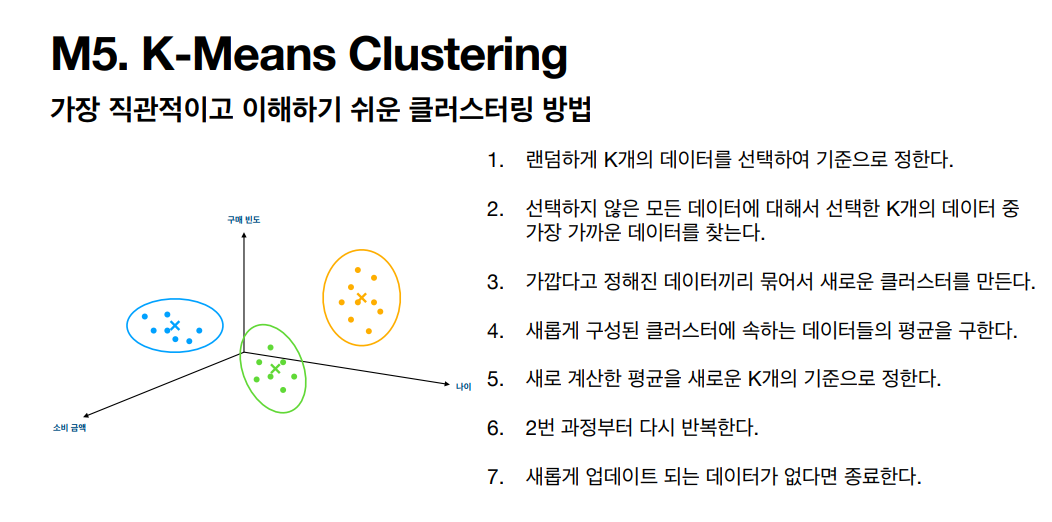
k-평균 알고리즘의 작동 방식
- 초기화 : centroid(클러스터의 중심)를 랜덤하게 선정
- 샘플에 레이블 할당
- Centroid 업데이트
- 레이블 재할당
- 최적값(centroid 변화가 없을 때)을 찾을 때까지 반복
운 나쁜 초기화에 따른 결과
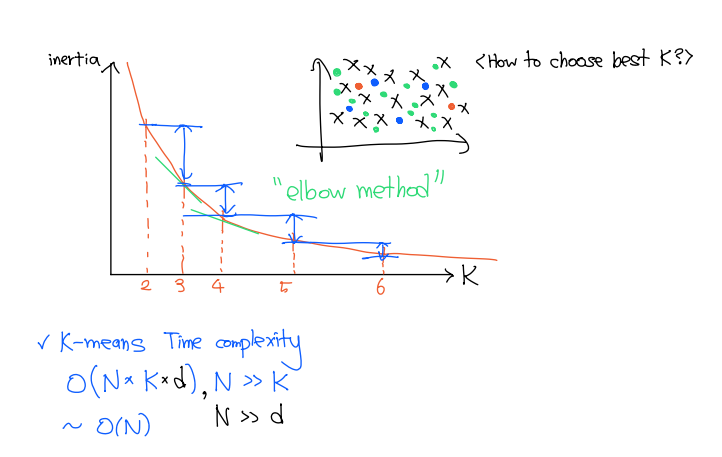
이너셔(inertia)
미니배치 k-평균(k-means) 알고리즘
최적의 k(클러스터 개수) 찾기: 엘보우, 실루엣 점수
• 방법
1. 엘보우(Elbow, 팔꿈치) 찾기
: 이너셔의 감소폭이 크게 줄어드는 지점
2. 실루엣 점수 & 다이어그램 활용
k-means 알고리즘의 한계
• 속도가 빠르고 확장이 용이하다
• 하지만 클러스터 개수(k)를 직접 지정해줘야 하고, 최적의 값을 찾기 위해 알고리즘을 여러 번 반복 실행해야 한다
• 클러스터의 크기나 밀집도가 다르거나, 원형이 아닐 경우 잘 작동하지 않는다 * 타원형 cluster에는 가우시안 혼합모델(GMM)이 잘 작동한다
k-means 알고리즘 활용 Tip
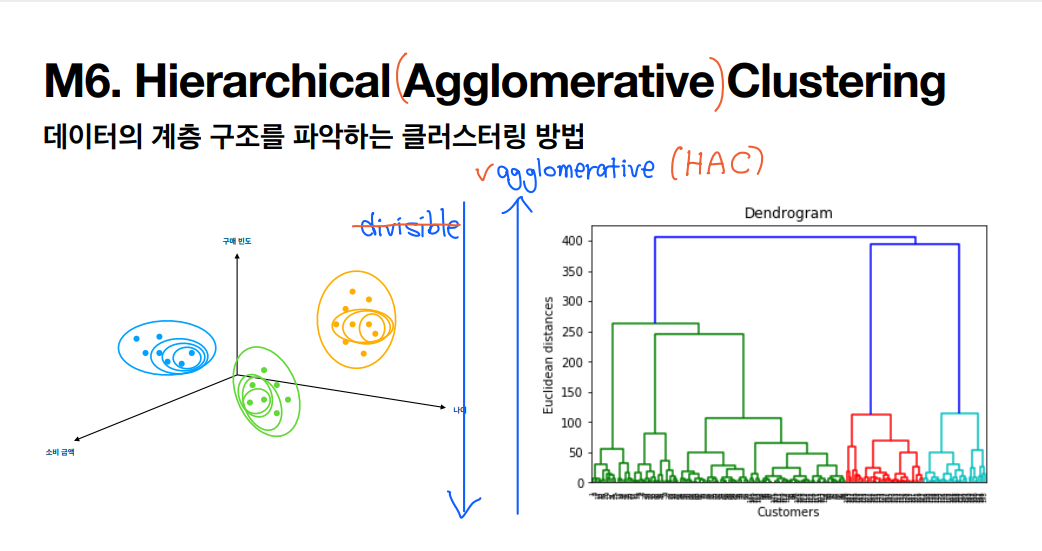
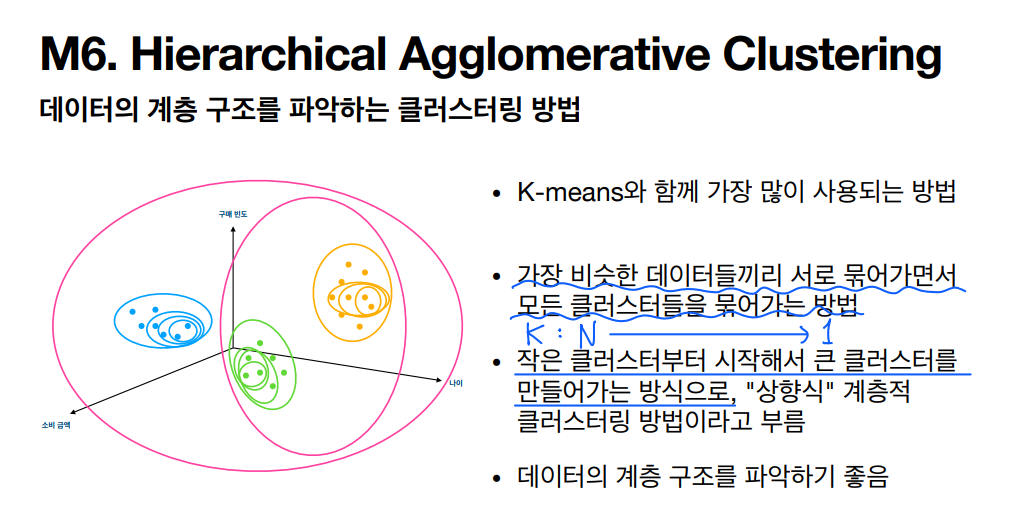
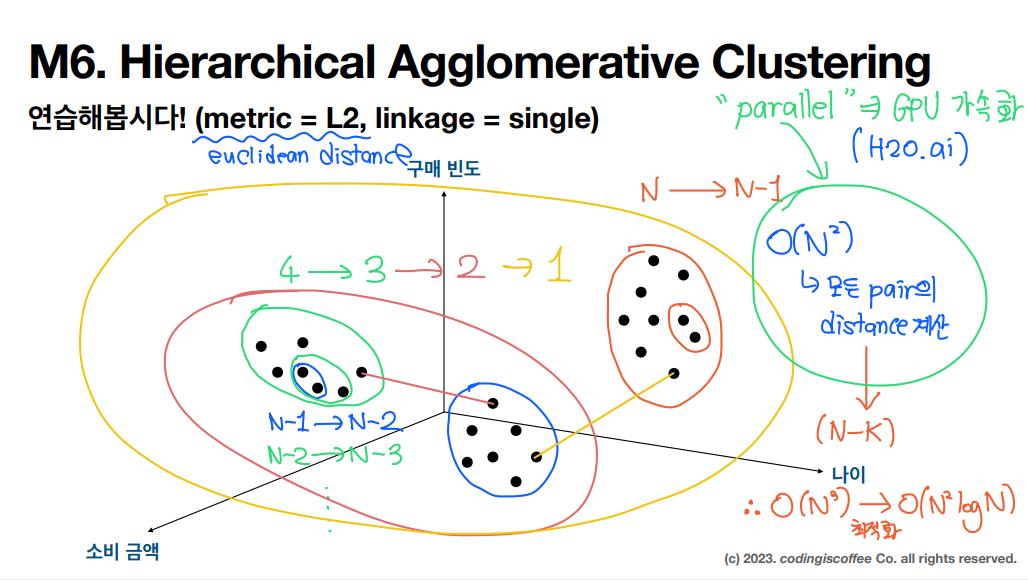
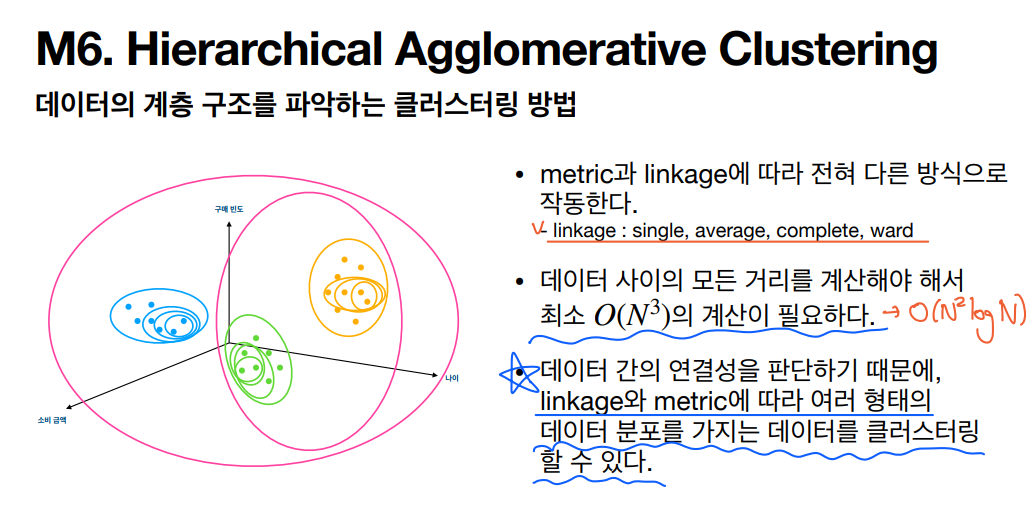
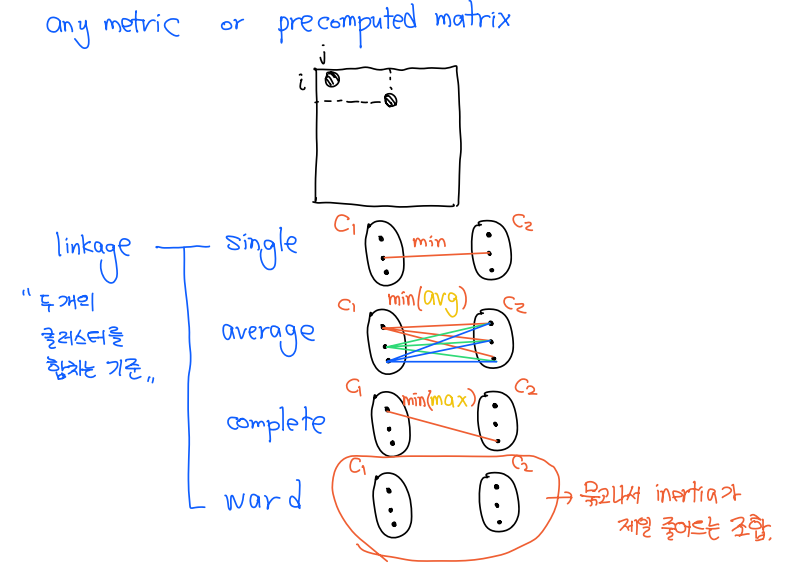
HAC 계층적 군집 분석

4. DB Scan
• 밀도 기반 군집화의 대표적 알고리즘
• 작동 방식
• 각 샘플에서 작은 거리인 𝜀내에 샘플이 몇 개 있는지 셈 > 𝜀 − 이웃이라고 부름
• 자신을 포함해 𝜀 − 이웃 내에 min_samples개 샘플이 있다면, 이를 핵심 샘플로 간주
• 핵심 샘플의 이웃에 있는 모든 샘플은 동일한 클러스터에 속함. 따라서 핵심 샘플의 이웃의 이웃은 계속해서 하나의 클러스터를 형성
• 핵심 샘플이 아니고 이웃도 아닌 샘플은 이상치로 판단
• 주요 파라미터
• eps : epsilon, 개별 데이터를 중심으로 입실론 반경을 가지는 원형의 영역
• min_samples : 개별 데이터를 중심으로 입실론 주변 영역에 포함되는 타 데이터의 개수
