의사결정나무 모델 (Decision Tree)
참고자료
- 김성범 소장, [핵심 머신러닝] 중 의사결정나무모델 강의
- 파이썬 라이브러리를 활용한 머신러닝
- 핸즈온 머신러닝, 박해선 강의
- 이어드림, 김용담, 이상엽 강의
1. 의사결정나무모델 개요

-
데이터에 내재되어 있는 패턴을 변수의 조합으로 나타내는 예측/분류 모델을 나무의 형태로 만드는 것
-
핵심아이디어: 질문을 던져서 맞고 틀리는 것에 따라 우리가 생각하고 있는 대상을 좁혀나감,
스무고개놀이와 비슷한 개념 -
의사결정나무의 핵심개념 정리
-노드(node): 질문이나 정답을 담은 네모 상자
-리프(leaf): 마지막 노드
-에지(edge): 예/아니오, True or False의 선 -> 질문의 답과 다음 질문을 연결함
-특성: 질문의 수, "날개가 있는가?", "날 수 있는가", "지느러미가 있는가"클래스: 구분하는 가지수 ex> 붓꽃분류: 3가지
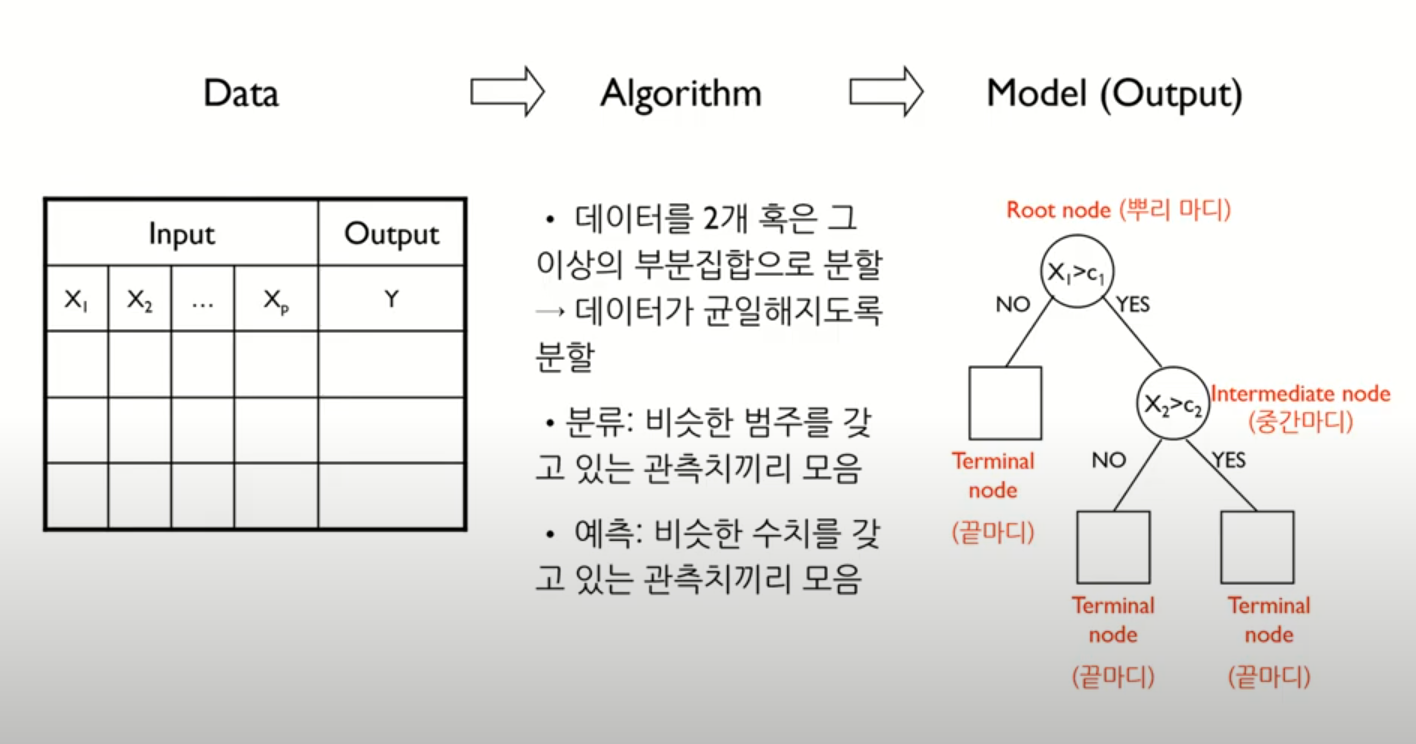
-
그림과 같이
데이터가 들어오고알고리즘을 통해서모델(output)이 구축되는 형태 -
Data: 다변량 변수가 들어왔고, input변수, output변수로 구성, 인풋과 아웃풋은 관계가 있다는 가설을 가지고 있는 것 -
Algorithm: 데이터가 2개 혹은 그 이상의 부분집합으로 분할, 이때 데이터가 균일해지도록 분류를 한다.
-분류: 비슷한 범주를 갖고 있는 관측치끼리의 모음
-예측: 비슷한 수치를 갖고 있는 관측치끼리의 모음 -
Model:노드의 구성
- 뿌리마디(Root node): 의사결정나무 모델에서 유일하게 1개만 존재- 중간마디(Inermediate node): 아래 가지가 존재하는 경우
- 끝마디(Terminal node, Leaf node): 아래에 더이상 가지 분지가 발생하지 않는 경우
-
이진분할
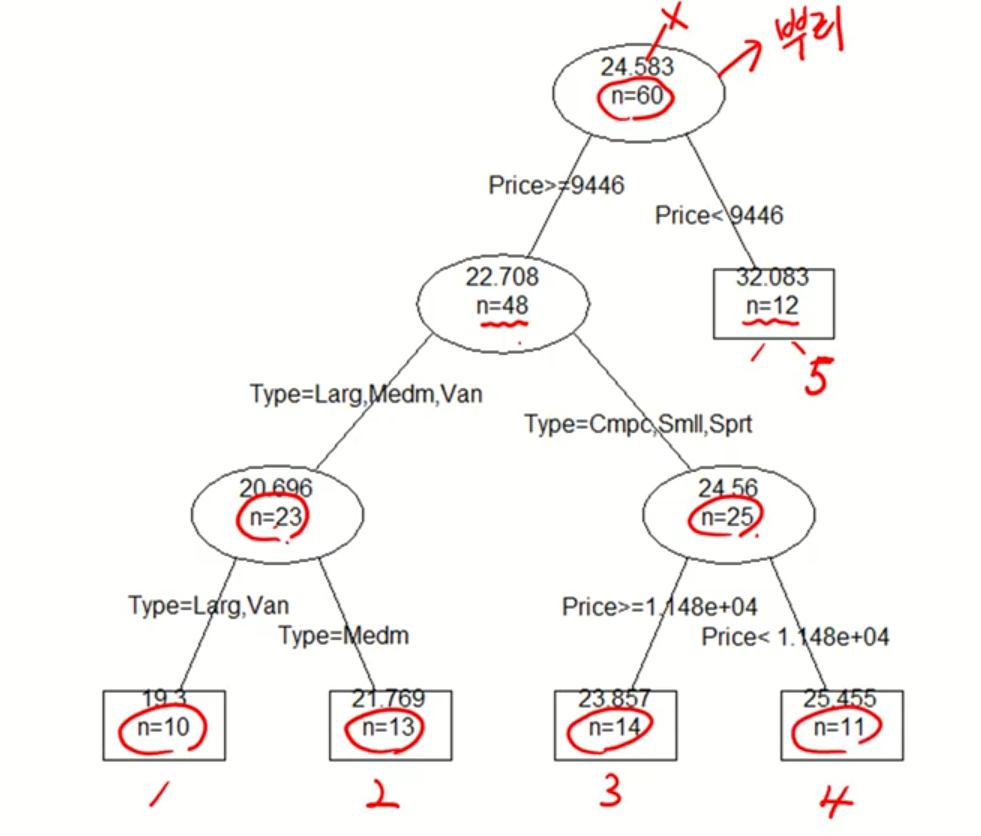
-
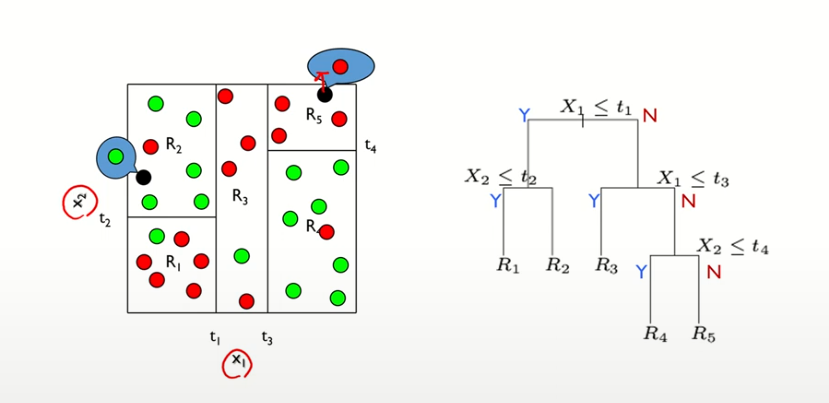
60개의 데이터가 4번의 이진분할에 의해서 5개의 부분집합으로 분할이 되었다.

-
왼쪽 그림: 2차원 공간에서의 이진분할
- 변수가 weight와 acceleration- 박스(결정경계, Decision boundary)를 만들어서 점점 작은 박스를 분할하여 혼재되어 있는 데이터를 점점 균일한 데이터로 바뀌게 된다.
- 최종적으로 큰 박스에는 대부분이 흰색이고 작은 박스는 대부분 검은색, 처음 데이터보다 균일해졌다.
-
오른쪽 그림: 3차원상에서 이진분할
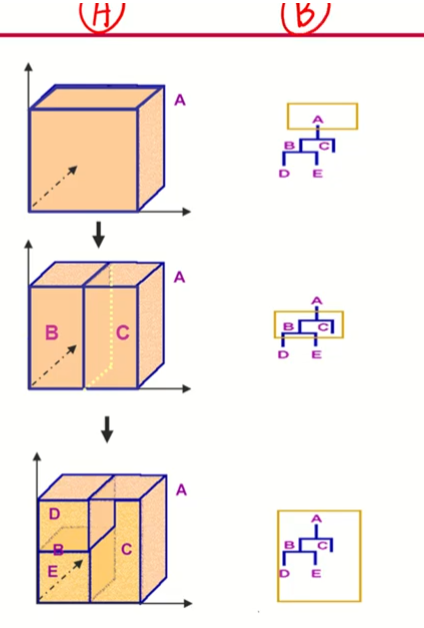
-
A는 3차원공간에서 이진분할, B는 의사결정나무
-
마지막의 끝마디 갯수는 3개
-
A가 직관적이긴 하나 2차원 혹은 3차원, 즉 변수가 3개 있을 때까지만 표현가능, 4차원이 되려면 축이 하나 더 늘어나야 하는데 공간상 표현하기가 어려움
-
B의 경우 변수가 5개이든, 1000개이든 2차원공간에서 나무형태로 그려지기 때문에 x변수의 갯수가 아무리 늘어나도 B의 표현은 가능하다.
2. 예측나무모델 (Regression Tree)
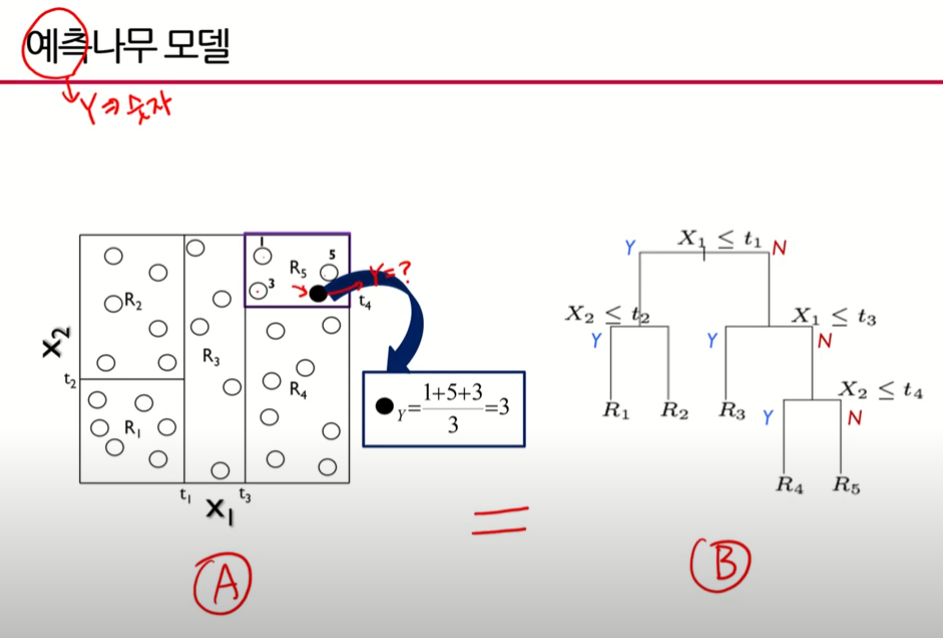
- 예측나무모델의 기본적인 아이디어 설명
- 그림상에서 변수가 2개, ○는 관측치, 예측나무에서의 값은 숫자(범주가 아닌)
- 결정경계(나누는선) 4개를 이용해서 5개의 부분집합(), 작은 사각형으로 나눔
- 예측나무모델은 새로운 데이터(관측치)가 들어왔을 때 그 데이터에 대한 값을 알아내야 한다.(예측할 수 있어야함)
- 각 ○ 하나하나가 값을 가지고 있는 형태
- 그림처럼 검은점●이 들어왔을 때 검은 게 속해있는 작은 박스내에 나머지 3개의 ○의 값을 조사해보니 1,3,5였을 때 Q. 검은 점을 어떻게 예측할것인가?
- 방법은 여러가지 있겠으나 검은점이 속해있는 작은 박스의
관측치의 Y값의 평균으로 예측하겠다는 것이 예측나무의 핵심 - B도 표현은 다르나 같은 내용
- 은 6개, 는 6개, 는 3개.. 이런식으로 끝마디에 관측치가 이진분할에 의해 나누어져 들어가있음

- 예측나무 모델의 식에서 는 indicator fuction으로 중괄호의 조건이 0이면 False를, 1이면 True를 내뱉는 이진함수이다.
- {}의 중괄호 안의 조건은 가 지역에 있는지 물어본 것, 여기서 은 끝마디를 의미함, Q.내가 고려하고 있는 데이터가 지역에 있는가? 없으면 0, 있으면 1
- 지역에 있는 경우 이 됨
- 이처럼 새로운 데이터가 들어왔을 때는 이렇게 costant한 하나의 숫자로 예측을 하는 모델
- 의사결정나무(예측나무)를 표현하는 3가지 방법
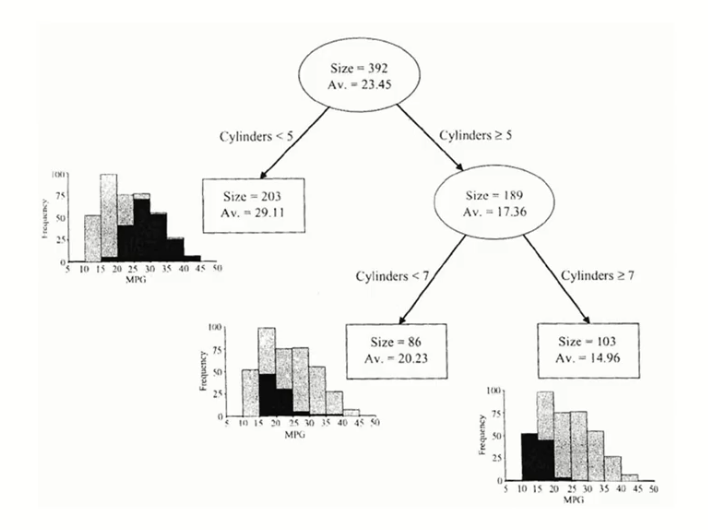
- 예측나무모델의 실제 예제
- 는 처음 가지고 있는 데이터의 관측치의 총 갯수가 392개라는 것, 는 변수(output)의 평균값
- 실린더가 5보다 작냐 크거나 같으냐로 2가지로 나뉨
- 끝마디가 3가지
- 처음 평균값이 23.45였으나 분기를 통해 좀 더 균일한 를 갖고 있는 관측치끼리 모임 -> 첫번째 끝마디는 꽤 큰 값이 모였고(평균값이 상대적으로 크다), 세번째 끝마디는 꽤 작은 값이 모였다.(평균값이 상대적으로 작다)
Q.어떻게 예측나무에서 나눌 것인가?
예측나무 모델링 프로세스

- Q.Cm이 무엇인가?
- 실제 값과 모델을 통해 나온 값의 차이의 제곱의 합을 최소화시키려면 이 무엇이 되어야 할까?를 찾는 것이 예측나무모델의 비용함수
- 결국 아래와 같은 식이 되며 각 분할에 속해있는 y값의 평균으로 예측했을 때 오류가 최소화된다.
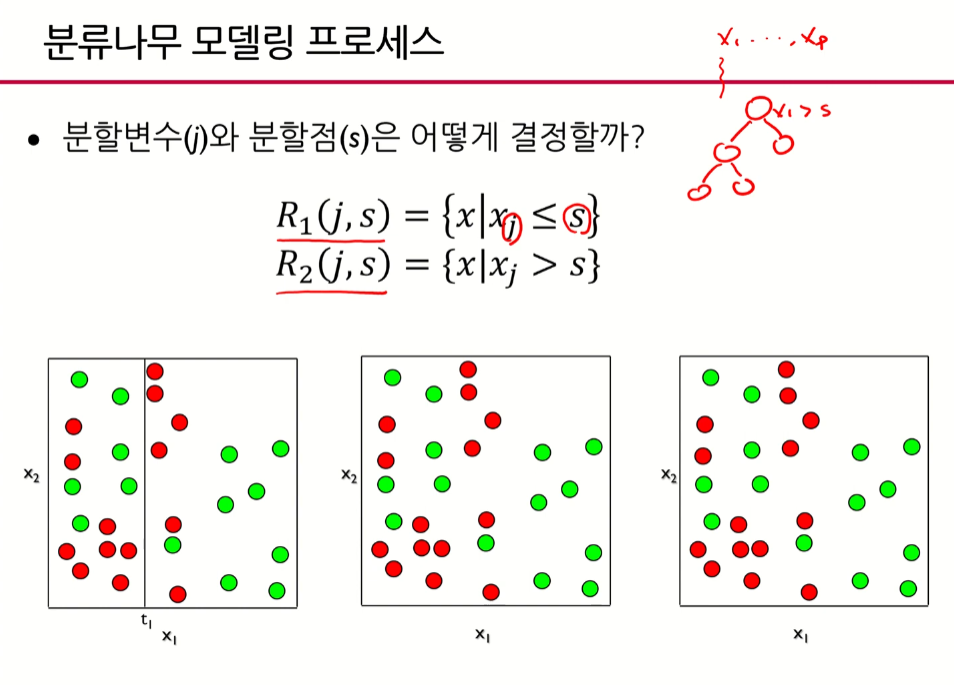
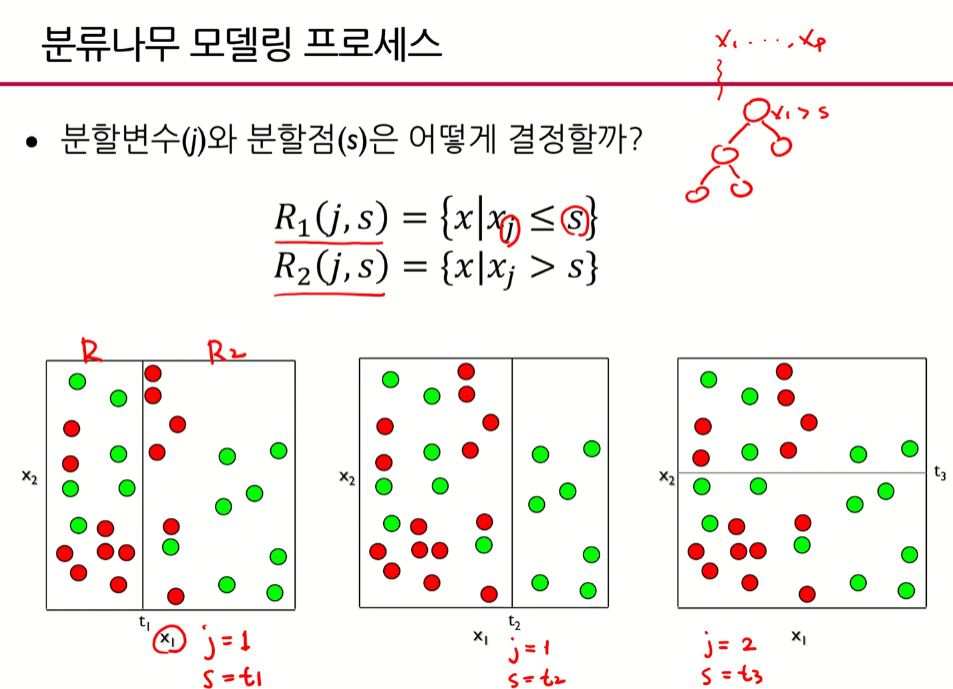
Q.예측나무에서 분할변수(j)와 분할점(s)은 어떻게 결정할까?


- 분할변수와 분할점을 찾는 것은 모든 후보군들을 다 고려해가면서 찾는 것이 때문에 GridSearch에 해당한다.
3. 분류나무모델(Classification Tree)
- 그 지역의 대다수(majority) 범주(클래스)로 분류하는 것이 분류나무모델의 기본 아이디어이다.
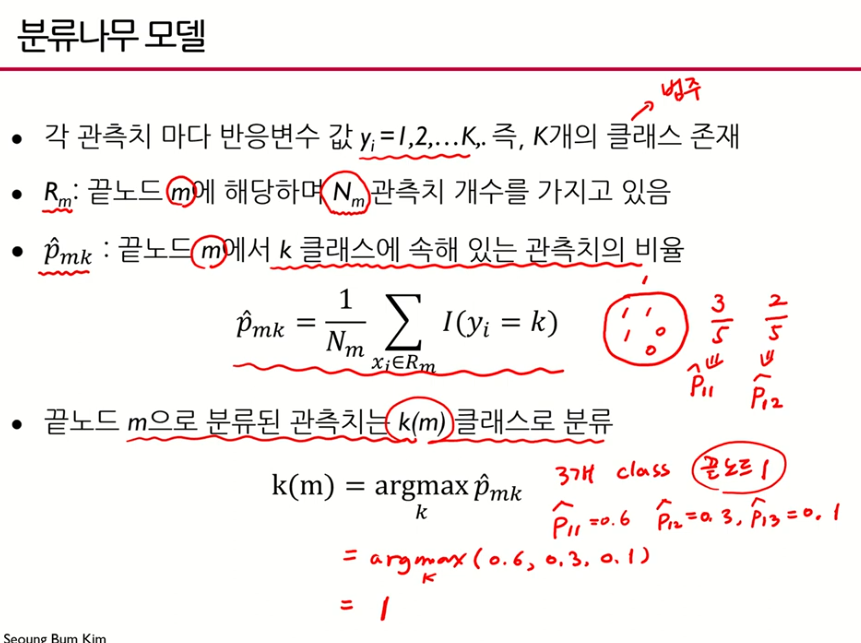
- 마지막 끝노드1의 1번 클래스가 답

- 는 인 3번째 끝노드에서 가장 큰 확률을 가지고 있는 범주(클래스)
,majority observations을 가지고 있는 그 클래스의 인덱스
분류모델의 비용함수
- 분류모델에서는 y가 실제값이 아니라 범주이기 때문에 차이를 계산하는 게 무의미함
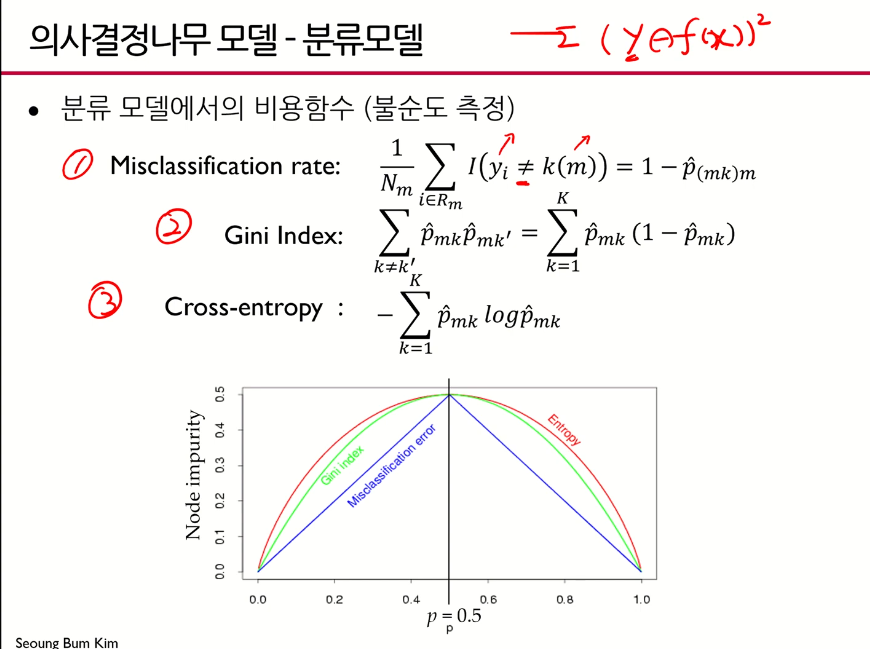
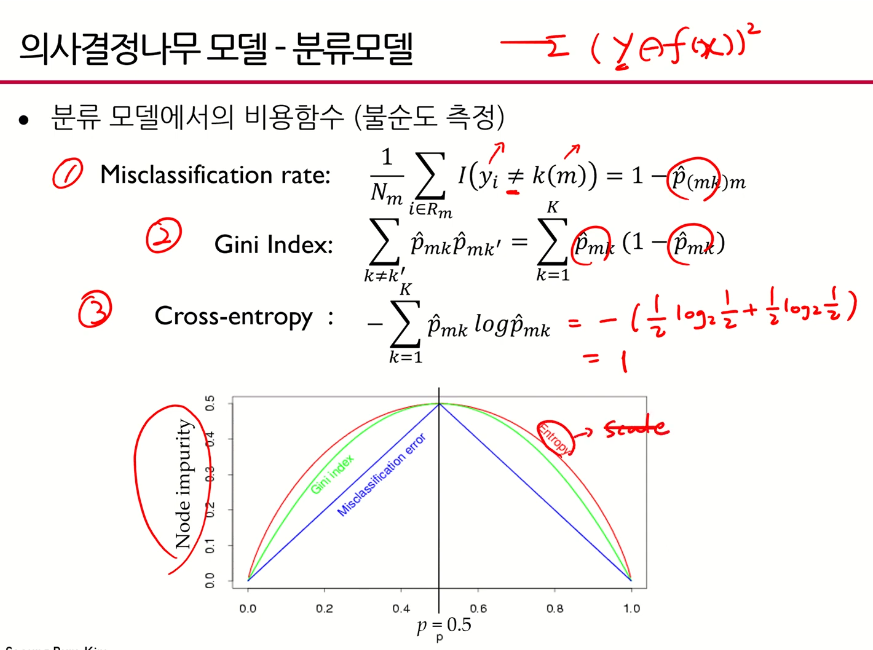
- 크로스엔트로피 함수에서 가 많이 쓰임
- 여기서 크로스 엔트로피 값 는 1인데 여기서 는 0.5가 최대가 되도록 하는 값 -> entropy가 스케일 된 값, 축을 맞추기 위해 그려놓은 그림
- Q.분류나무에서 분할변수(j)와 분할점(s)은 어떻게 결정할까?
- 비용함수를 최소로 하는 값을 찾는 것이 분류모델의 핵심
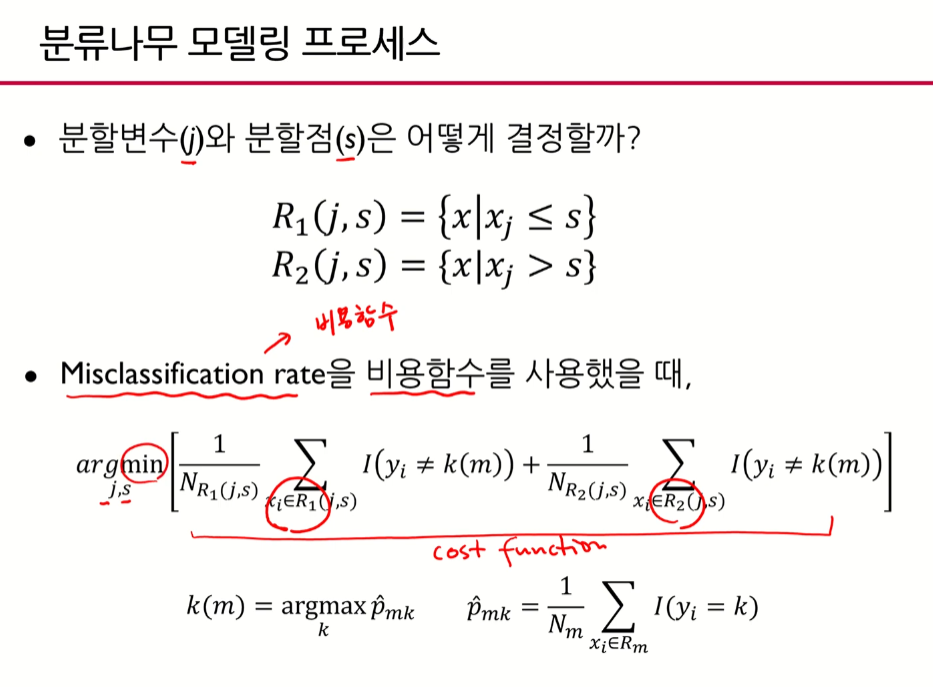
- 비용함수를 최소로 하는 j(분할변수)와 s(분할점)를 찾는 것
- j와 s를 찾아서 분지하고 그 분할점 찾는 것을 반복함

- y가 균일한 방향으로 가는 것 = 목표변수의 분포를 가장 잘 구별해줌
- 45%, 55%인 경우는 굉장히 혼재되어 있는 경우를 의미함 (순수도가 낮다, 불순도가 높다.)
- 불순도의 감소가 최대가 된다 = 불순도의 값이 최소가 된다는 의미
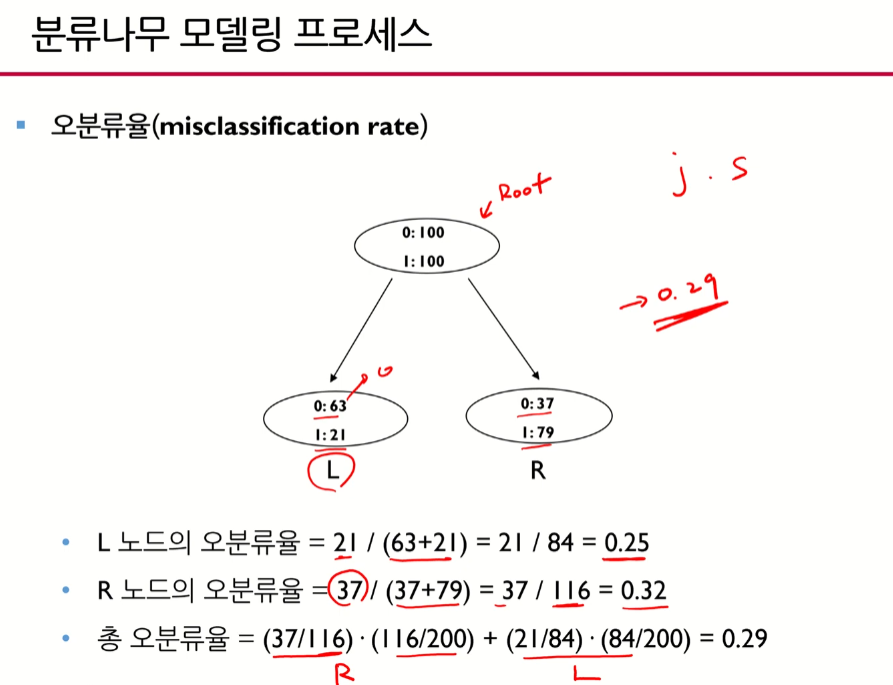
- 총 오분류율(여기서 0.29)가 가장 작았을 때 j와 s를 결정한다.
지니인덱스와 엔트로피 계산

- 지니계수:(얼룩말의 비율 1-얼룩말의 비율)+(코뿔소의 비율 1-코뿔소의 비율)
- 지니인덱스는 0~0.5사이, 0.24는 2정도의 불순도를 가지고 있다고 할 수 있음 - 엔트로피:-{(얼룩말의 비율얼룩말의 비율)+(코뿔소의 비율코뿔소의 비율)
- 엔트로피는 1에 가까울수록 안좋다. 0.1781이므로 지니계수에 비해 상대적으로 불순도가 작다.
4. 정보이론 Information Gain

- 엔트로피가 0.94이므로 꽤 혼재되어 있음

- Informtion Gain을 이용해서 중요한 변수를 찾는 예제
- :전체 중 바람부는 날의 Information Gain을 계산하려면
- 전체 엔트로피(혼잡도)에서 A즉, Wind라는 변수를 사용했을 때 엔트로피가 얼만큼 감소했는가를 보여주는 척도 - Humidity의 IG가 0.151이 나옴, wind와 humidity를 비교해봤을 때 humidity의 information gain이 훨씬 크다. humidity가 전체play 엔트로피를 더 많이 감소시킨다는 뜻, 따라서 wind보다는 humidity가 더 중요한 변수라고 볼 수 있다.
개별 트리모델의 단점

- 다음단계의 에러가 계속 누적되서 다음에 전달됨
- 나무의 최종 노드의 갯수를 늘리면(max depth를 키워서) taining error는 거의0으로 만들 수 있으나 과적합 위험이 커진다.
- 이렇게 되면 2번째 그림처럼 bias는 낮아져도 Variance(변동성)는 커질 수 있다.
- ※참고: bias와 variance https://todo-data.tistory.com/5
박중배, CH01_06. [Theory Session 2]Bias Variance Trade-off - Variance가 크다는 것은 새로운 데이터에 대해서 예측성능이 떨어진다는 의미
- 이러한 단점을 보완하기 위해 나온 것이 Random Forest
- 랜덤포레스트는 나무를 여러개 만들어 여러개 나무로부터 나온 결과를 요약해서 최종 결과를 내는 모델
