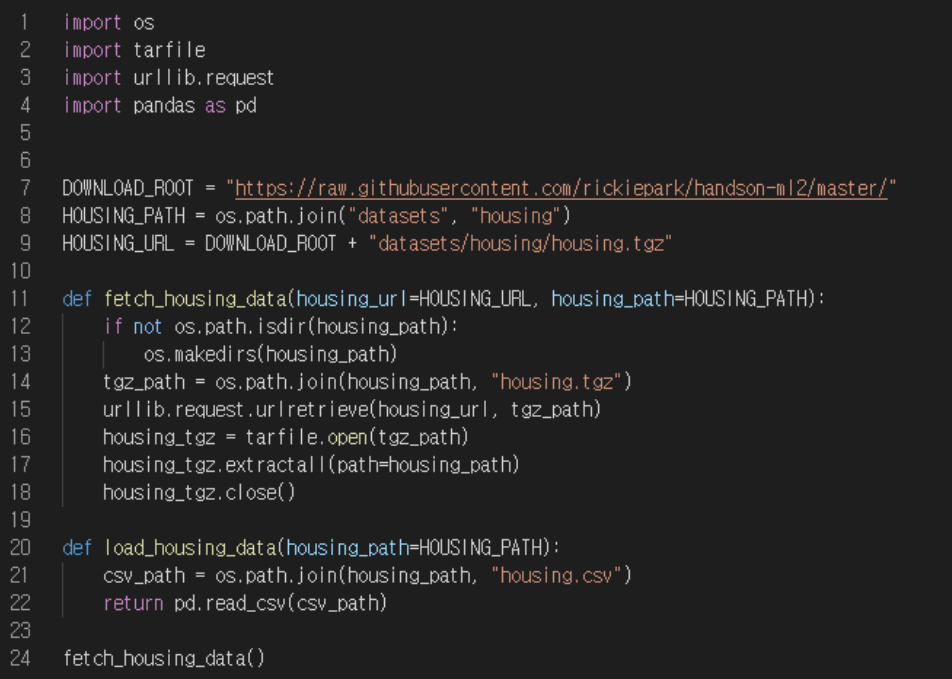
1. 데이터 읽어오기
• fetch_house_data() : 작업공간에 housing.tgz 파일을 다운 받아 압축 해제
• pd.read_csv() : 판다스(pandas)의 데이터를 읽어들이는 메소드
2. 데이터 훑어보기
• housing.head() : 앞 5개의 데이터 추출(숫자 지정 가능)
• housing.info() : 데이터의 전체 행수, 각 특성의 데이터 타입과 결측치(null)가 아닌 개수 파악
• housing[‘ocean_proximity’].value_counts() : 특성 별로 데이터 분포 확인
• housing.describe() : 수치형 특성에 대한 기초 통계자료 제시 ( 평균, 표준편차, 백분위수 등 )
• Housing.hist(bins=50) : 전체 데이터셋의 수치형 특성에 대해 히스토그램 살펴보기
3. 테스트 데이터 만들기
• 과대적합을 피하기 위해 미리 테스트 데이터를 만들고, 학습에 이용하지 않기
• 테스트 데이터를 들여다보면, 테스트 데이터가 지닌 패턴에 속아 학습 모델을 선택하게 될 수 있음
• 이러한 낙관적 추정은 이후 실제 시스템을 런칭했을 때 성능저하의 원인이 될 수 있다 -> 데이터 편향이 될 수 있음
• 사이킷런(sklearn)의 train_test_split() 함수로 훈련 데이터(80%)와 테스트 데이터(20%) 분리
• 타겟 비율(계층적 비율)을 훈련/테스트 셋에서 유지하고 싶다면 StratifiedShuffleSplit() 함수 활용
• 타겟 변수(Income 수준이 5 scale로 구분될 때)가 있다고 할 때,
타겟 비율(계층적 비율)을 훈련/테스트 셋에서 유지하고 싶다면 StratifiedShuffleSplit() 함수 활용
