AI : Fine Tuning
1.[AI] 파인튜닝 - 나에게 특화된 모델을 만들어보자.

이것저것 잡스러운걸 만들다보니 결국 모델을 특정 데이터로 훈련하여 서비스하는 것으로 귀결되었다. 지금까지는 rag > langchain > mcp + agent 순으로 공부를 했다면 지금부터는 특정 분야에 전문성을 지닌 모델을 만들어 볼까 한다.그 배경에는 rag 와
2.[AI] 파인튜닝 - 그런데... jsonl 파일은 조상님이 만들어주냐?

한국말로는 "지시학습 데이터셋" 이라고 한다.GPT 에게 물어봤더니 널리 사용되는 데이터셋이 몇개 있다고 한다.그걸 한번 알아보자.Princeton & AI2의 논문 "Self-Instruct" 을 기반으로 만듬.형식: { "instruction": ..., "inst
3.[AI] 파인튜닝 - OpenOrca 로 Instruction dataset 만들자.

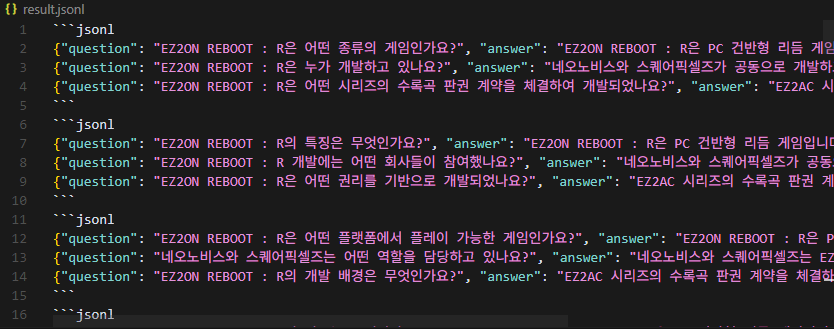
6번 실패해서 총 140개의 질문과 대답이 만들어졌다.근데 자세히 보면 질문이 아닌 평문이 question 에 들어가 있는 것을 볼 수 있다.이런 것은 미조정이 필요하다. 질문에 대한 답변이 이상한 것도 많이 보인다. 오오...왜 3000원?흠...허허허...질문, 답
4.[AI] 파인튜닝 - 질문, 답변 데이터셋 만드는게 너무 힘들다! (작성중)

질문과 대답의 품질은 뛰어난데... 너무 조금 나오네...
5.[AI] 파인튜닝 - google-adk 를 api_server 로 구동하자.

URLhttp://0.0.0.0:8000/apps/multi-agent/users/exoluse/sessions/session_exoluseMethodPOSTHeaderContent-Type : application/jsonBody{ "state": {"
6.[AI] 파인튜닝 - google-adk(api_server) + ollama

google 의 모델을 사용하는게 아니기 때문에 사용량 변화는 없다.자료가 없으니 찾는데 애좀 먹었다...모델명은 https://docs.litellm.ai/docs/providers/ollama허깅페이스는 여기로 https://docs.litellm
7.[AI] 파인튜닝 - google-adk 의 callback 사용
종류는 총 4가지가 있다.before_model_callbackafter_model_callbackbefore_agent_callbackafter_agent_callback자세한 내용은 https://google.github.io/adk-docs/callbac
8.[AI] 파인튜닝 - google-adk Agent 를 그냥 llm 처럼 사용
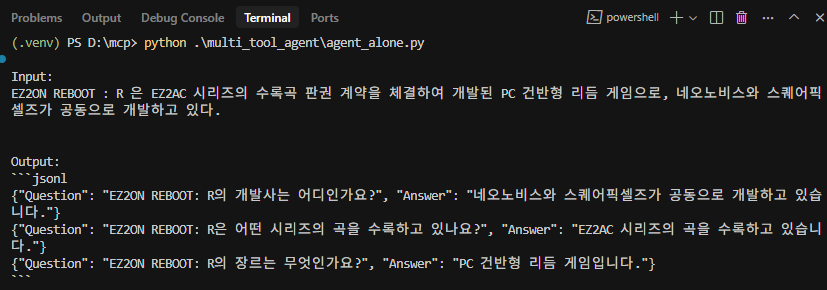
한번에 여러개가 나오지는 않지만 조금씩 계속 돌리면 될 듯 하다.이렇게 질문, 응답 데이터 수집 과정을 거쳤다.여러 방법이 있었지만 결국 돈이 드는 GPT 계열 대신 google-adk Agent 를 쓰게 되었고 다행히(?) ollama 연동도 시원하게 되어서 모델 선
9.[AI] 영화 소개 문장으로 학습해보자

2023년도에 개봉한 시게루짱의 수퍼마리오 브라더스의 나무위키 일부분이다.이걸 가지고 데이터를 만들어 보겠다.총 713개의 질문과 답변 생성모델은 exaone3.5:7.8b 을 사용하였다.소스는 이전과 동일하니 패스.만든 질답 데이터로 학습을 실시한다.학습 대상은 아무
10.[AI] 파인튜닝 전 accelerate config
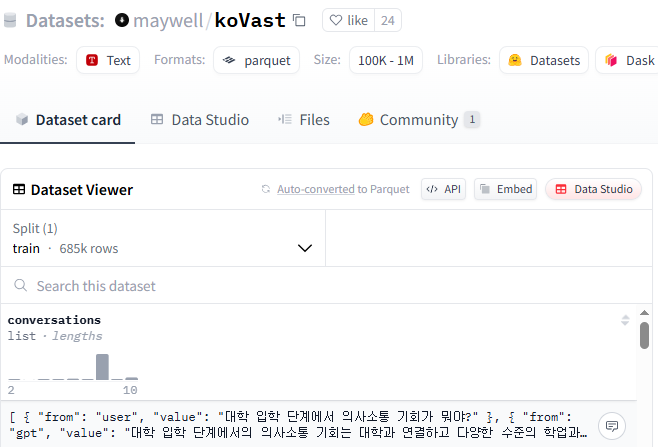
tinyllama chat 계열의 모델에 한국어 문답을 학습시킬 계획이었다.TinyLlama-1.1B-Chat-v1.0 모델https://huggingface.co/TinyLlama/TinyLlama-1.1B-Chat-v1.0maywell/koVast 데이터셋
11.[AI] 파인튜닝으로 만드는 나만의 아이폰 고객센터 #1
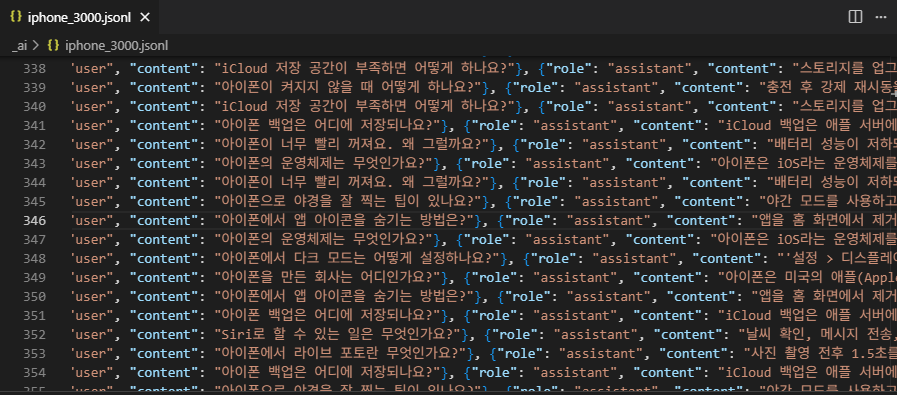
gpt에게 아이폰 관련 질문과 답변을 3,000개 만들어달라고 뗴쓴다.역시 빠르게 만들어준다. Openorca 를 써볼까도 했지만 어제일(네이버 뉴스 학습 실패함)이 생각나서 빠르게 포기했다.TinyLlama/TinyLlama-1.1B-Chat-v1.0 로 골랐다. e
12.[AI] 파인튜닝으로 만드는 나만의 아이폰 고객센터 #2

num_train_epochs 10 > 20per_device_train_batch_size 4 > 8logging_steps 3 > 8또한번 개소리 남발...개소리 남발222개소리 남발33333333자... Take 학습량을 늘려서 일단 원래 질문에는 답변을 할 수
13.[AI] 파인튜닝으로 만드는 나만의 아이폰 고객센터 #3

같은 맥락의 비슷한 질답이 이어지니 학습이 잘 되지 않을거 같음.대충 100가지 정도 될거같은데 3000건은 너무 많다. 중복 제거 요망아이폰의 다른 질문거리도 넣어보자.데이터 중복 제거로 인한 파라미터의 변경이 불가피해 보인다.마찬가지로 수정이 필요해 보인다.내가 직
14.[AI] 파인튜닝 할때 가장 힘들었던 것
회사 컴퓨터로 파인튜닝을 돌려봤는데 업무 끝날때까지 Progress 화면을 보지 못했다고 한다.기다리다 흰머리 날거같아서 빡종함.perplexity 에게 물어보았다.i7-11700 CPU(8코어/16스레드)로 1.1B 파라미터 모델을 LoRA(r=32, alpha=64
15.[AI] LoRA 모델과 원본 모델을 합치기
이걸 사용하려면 항상 원본 모델에 얹어서 로드해야만 했는데...합치면 이런 모양새가 된다.당연하겠지만 같은 결과가 나온다.
16.[AI] 허깅페이스 튜닝 옵션 복기...(정리중)
1. TrainingArguments 파라미터 정리 | 옵션명 | 설명 | 예시 | | ---------------