1. 1b 채팅모델 훈련을 목표로...
tinyllama chat 계열의 모델에 한국어 문답을 학습시킬 계획이었다.
TinyLlama-1.1B-Chat-v1.0 모델
https://huggingface.co/TinyLlama/TinyLlama-1.1B-Chat-v1.0
2. 조금 큰 데이터셋 선택
maywell/koVast 데이터셋
conversation 안에 user 와 gpt 의 대화가 들어있다. 무려 685k...
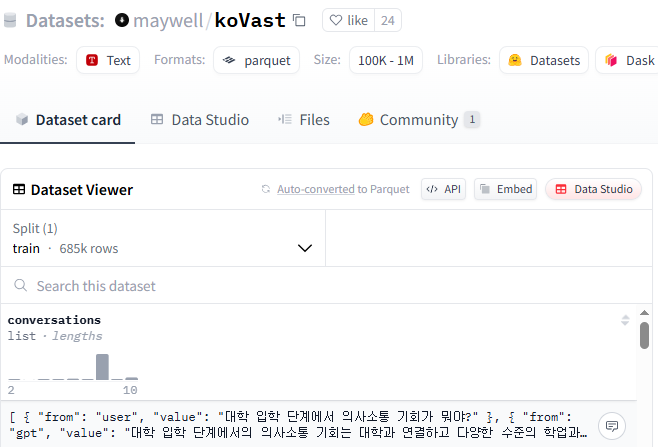
대충 전부다 끌고 온다.
# 필요한 라이브러리 임포트
import os
from datasets import load_dataset
from dotenv import load_dotenv
# .env 파일 로드
load_dotenv()
hf_token = os.getenv("HUGGINGFACE_API_KEY")
# 2. 데이터셋 로딩
dataset = load_dataset("maywell/koVast", token=hf_token)
# 5. 저장
dataset.save_to_disk("original_dataset")3. 다운로드 받은 데이터셋 토크나이징
# 필요한 라이브러리 임포트
import os
from transformers import AutoTokenizer
from datasets import load_from_disk
from dotenv import load_dotenv
MAX_LENGTH = 2048
# 1. env 파일 로드
load_dotenv()
hf_token = os.getenv("HUGGINGFACE_API_KEY")
model_id = "TinyLlama/TinyLlama-1.1B-Chat-v1.0"
tokenizer = AutoTokenizer.from_pretrained(model_id, token=hf_token)
# 2. 데이터셋 로딩
dataset = load_from_disk("./original_dataset")
# 프롬프트 생성
def make_prompt_from_conversations(example):
messages = example["conversations"]
# "from"을 role로 매핑
formatted = [{"role": "user" if m["from"] == "user" else "assistant", "content": m["value"]} for m in messages]
prompt = tokenizer.apply_chat_template(
formatted,
tokenize=False,
add_generation_prompt=False
)
return {"text": prompt}
# 3. 데이터셋으로 프롬프트 생성
dataset = dataset.map(make_prompt_from_conversations, batched=False)
# 토크나이징
def tokenize(example):
return tokenizer(example["text"], truncation=True, max_length=MAX_LENGTH)
# 4. 최종 토큰처리된 데이터셋.
tokenized_dataset = dataset.map(tokenize, batched=False)4. LoRA 튜닝 시도
# 필요한 라이브러리 임포트
import os
from transformers import (
AutoModelForCausalLM, TrainingArguments, Trainer,
DataCollatorForLanguageModeling, AutoTokenizer
)
from datasets import load_from_disk
from dotenv import load_dotenv
import torch
import gc
from peft import LoraConfig, get_peft_model, TaskType
# PyTorch CUDA 메모리 설정: GPU 메모리 조각을 동적으로 확장 가능하게 설정 (OOM 방지)
os.environ["PYTORCH_CUDA_ALLOC_CONF"] = "expandable_segments:True"
# 불필요한 객체 수거 및 GPU 메모리 초기화
gc.collect()
if torch.cuda.is_available():
torch.cuda.empty_cache()
# .env 파일에서 환경변수 로딩 (예: HUGGINGFACE_API_KEY)
load_dotenv()
hf_token = os.getenv("HUGGINGFACE_API_KEY")
# CUDA 사용 가능 여부 확인 (있으면 GPU 사용, 없으면 CPU)
device = "cuda" if torch.cuda.is_available() else "cpu"
# Hugging Face에서 TinyLlama 모델과 토크나이저 로드
model_id = "TinyLlama/TinyLlama-1.1B-Chat-v1.0"
tokenizer = AutoTokenizer.from_pretrained(model_id, token=hf_token)
model = AutoModelForCausalLM.from_pretrained(model_id, token=hf_token)
# LoRA 구성 설정
lora_config = LoraConfig(
r=8, # LoRA 랭크 (적은 파라미터 수)
lora_alpha=16, # LoRA scaling factor
target_modules=["q_proj", "v_proj"], # attention 모듈에서 q/v projection에만 적용
lora_dropout=0.05, # LoRA 드롭아웃 비율
bias="none", # 기존 bias 학습 안 함
task_type=TaskType.CAUSAL_LM # Causal Language Modeling (GPT류) 태스크
)
# 기존 모델에 LoRA 레이어 적용 (PeftModel 생성)
model = get_peft_model(model, lora_config)
# 모델을 CUDA 디바이스로 이동
model.to(device)
# 토크나이징이 완료된 데이터셋 로딩 (train split만 사용)
dataset = load_from_disk("tokenized_dataset")["train"]
# CausalLM을 위한 데이터 콜레이터 생성
# - MLM(False): 마스크드 언어모델링이 아니라 다음 토큰 예측 방식
# - labels 자동 생성: input_ids 복사
data_collator = DataCollatorForLanguageModeling(
tokenizer=tokenizer,
mlm=False
)
# 학습 관련 설정 정의
training_args = TrainingArguments(
output_dir="./tinyllama-lora", # 체크포인트 및 출력 디렉토리
per_device_train_batch_size=2, # GPU당 배치 사이즈
gradient_accumulation_steps=8, # 누적 후 역전파 → 실제 배치사이즈는 2 x 8 = 16
num_train_epochs=3, # 전체 데이터셋을 3번 학습
logging_steps=10, # 로그 출력 빈도
save_strategy="epoch", # 각 epoch마다 모델 저장
save_total_limit=2, # 저장할 체크포인트 최대 수
learning_rate=2e-4, # 학습률
fp16=True, # float16 사용 (GPU 메모리 절약)
report_to="none" # 로그 보고 안 함 (예: wandb 비활성화)
)
# Trainer 객체 생성
# - 모델, 학습 인자, 데이터셋, 데이터 콜레이터 전달
trainer = Trainer(
model=model,
args=training_args,
train_dataset=dataset,
data_collator=data_collator,
)
# 학습 시작
trainer.train()
# 최종 모델 저장 (LoRA 어댑터만 저장됨)
trainer.save_model("./tinyllama-lora/final")
5. 자... 이제 좀 기다려 볼까 했는데... 응?
야... 147시간은 너무하네;;;

6. AI 야... 이거 맞아?
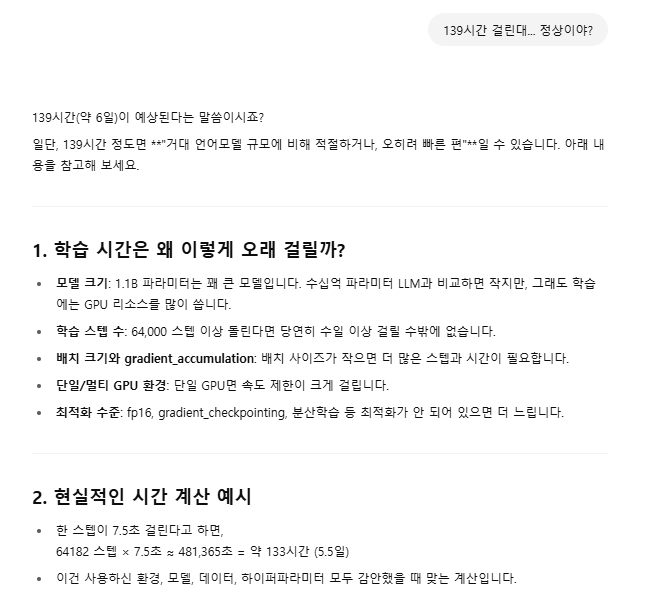
7. 허깅페이스에 accelerate 라는 모듈이 있다는데
🤗 Accelerate를 활용한 분산 학습
모델이 커지면서 병렬 처리는 제한된 하드웨어에서 더 큰 모델을 훈련하고 훈련 속도를 몇 배로 가속화하기 위한 전략으로 등장했습니다. Hugging Face에서는 사용자가 하나의 머신에 여러 개의 GPU를 사용하든 여러 머신에 여러 개의 GPU를 사용하든 모든 유형의 분산 설정에서 🤗 Transformers 모델을 쉽게 훈련할 수 있도록 돕기 위해 🤗 Accelerate 라이브러리를 만들었습니다. 이 튜토리얼에서는 분산 환경에서 훈련할 수 있도록 기본 PyTorch 훈련 루프를 커스터마이즈하는 방법을 알아봅시다.
라고 한다... 쉽게 말하자면 분산 환경에서 잘 굴러갈 수 있게 도와주는 가속기임.
8. accelerate 의 간단 사용법
-
accelerate 는 여기서 읽어보기로 하고
https://huggingface.co/docs/transformers/ko/accelerate -
설치는 이렇게 하고
% uv pip install accelerate- 설정은 이렇게...
% accelerate config8-1. accelerate config 세부 옵션 (by chatgpt)
| 질문 | 설명 | 예시 |
|---|---|---|
| In which compute environment are you running? | 실행 환경을 선택. 보통 This machine 선택 | - This machine (로컬) - AWS (SageMaker) - Vertex (Google Cloud) - etc. |
| Which type of machine are you using? | 로컬 환경의 유형. 일반적으로 No distributed training 또는 Multi-GPU | - No distributed training (CPU or 1 GPU) - Multi-GPU - TPU - DeepSpeed |
| Do you want to run your training on CPU only (no GPU support)? | GPU 없이 CPU로 실행할지 여부 | yes 또는 no |
| Do you want to use DeepSpeed? | DeepSpeed 분산 학습 프레임워크 사용 여부 | yes 또는 no |
| How many processes in total will you use? | 학습 프로세스 수 지정. GPU 개수와 보통 같음 | 예: 1 (싱글 GPU), 4 (4개 GPU 사용) |
| Do you wish to use FP16 or BF16 (mixed precision)? | 혼합 정밀도(FP16 또는 BF16) 사용할지 선택 | - no (기본값)- fp16- bf16 |
| Which backend should be used for distributed training? | 분산 학습 백엔드 선택. PyTorch에서는 보통 nccl | - nccl (GPU)- gloo (CPU)- mpi (특수 환경) |
| Even though this machine is not a multi-node one, should I use the same network interface for all processes? | 모든 프로세스에서 같은 네트워크 인터페이스를 쓸지 여부 (멀티-GPU인 경우 유용) | yes 또는 no |
| What is the main training script you want to use? | 실행할 메인 학습 스크립트 입력 | 예: train.py |
| Do you want to include any specific arguments when launching your training script? | 학습 스크립트에 추가 인자 전달 여부 | 예: --epochs 10 --batch_size 32 |
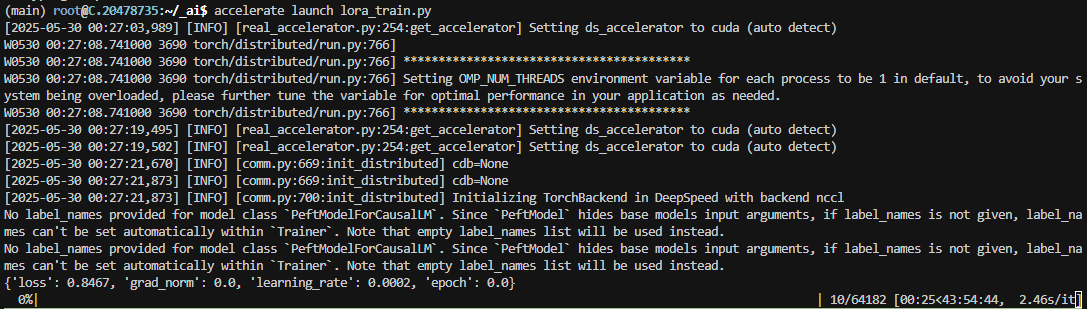
9. accelerate 를 적용하여 학습
GPU 갯수를 2로 설정하고 deepspeed 적용하고 튜닝 시작
% accelerate launch lora_config.py- 소요시간이 3분의 1로 줄어들었다. 확실히 의미있는 수치인듯

인공지능이라는 옷을 입었습니다. 뭔가 멋지면서도 잘 맞습니다.